1️⃣SVM(Support Vector Machine)이란?
- 개념: 주어진 데이터를 기반으로 분류 또는 회귀 분석을 할 수 있는 알고리즘
- 목적
- 분류 작업: 결정 경계를 찾고 데이터를 클래스로 분류
- 마친 최대화: 데이터 포인트 사이의 간격(마진)을 최대화하려고 노력
- 장점: 쉽게 확장이 가능
2️⃣Linear SVM Classification
- 개념
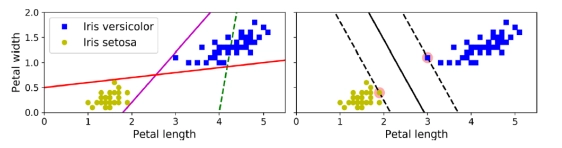 두 클래스가 명확하게 분리되는 경우, 직선으로 쉽게 구분할 수 있다.
두 클래스가 명확하게 분리되는 경우, 직선으로 쉽게 구분할 수 있다.
-
왼쪽 그림에서 두 모델은 훈련 세트에서 완벽하게 작동하지만, 결정 경계가 인스턴스에 너무 가까워서 새로운 인스턴스에 대해 성능이 그리 좋지 않을 가능성이 있다.
-
오른쪽 그림에서는 실선이 SVM 분류기의 결정 경계를 나타내며, 이 직선은 두 클래스를 분리하는 것뿐만 아니라 가능한 한 가장 멀리 떨어져 있다. 이를 큰 마진 분류(large margin classification)라고 한다. 새로운 훈련 인스턴스를 "거리 밖"(off the street)에 추가해도 결정 경계에는 영향을 미치지 않는다.
-
이러한 인스턴스를 서포트 벡터(support vectors)라고 한다. 이들은 오른쪽 그림에서 원으로 표시되어 있다.
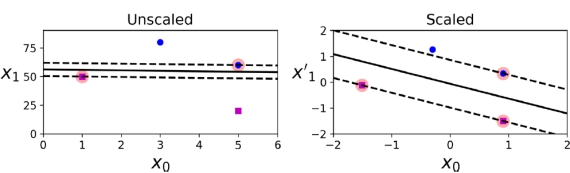
SVM은 특성(feature) 스케일에 민감하다
- 왼쪽 그림에서 수직 스케일이 수평 스케일보다 훨씬 크기 때문에 가장 넓은 거리는 수평에 가깝다.
- 오른쪽 그림에서는 특성 스케일링 후 결정 경계가 훨씬 좋아 보인다.
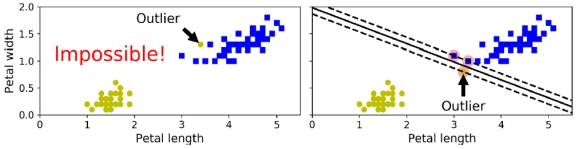
- 문제점
- 데이터가 선형적으로 구분 가능한 경우에만 작동한다.
- Outlier에 민감하다.
- 해결책:
Soft Margin Classification
2. Soft Margin Classification
- 개념: 하이퍼파라미터 C(규제 파라미터)를 사용하여 조정하는 방식
- 목표: 거리를 최대한 넓게 유지하며 마진 위반(중간이나 잘못된 쪽에 있는 인스턴스)을 제한하는 것
- C값의 따른 차이:
- 작으면 → 마진 크게, 오분류 조금 허용 (일반화 ↑)
- 크면 → 오분류 최소화, 마진 좁음 (과적합 위험 ↑)
 낮은 값으로 설정하면 왼쪽 모델처럼 되고, 높은 값으로 설정하면 오른쪽 모델처럼 된다.
낮은 값으로 설정하면 왼쪽 모델처럼 되고, 높은 값으로 설정하면 오른쪽 모델처럼 된다.
✅slack variable: 약간 경계를 넘어가도 되도록 허용하는 것
3. Nonlinear SVM Classification
- 개념: 더 많은 특성을 추가하는 방식
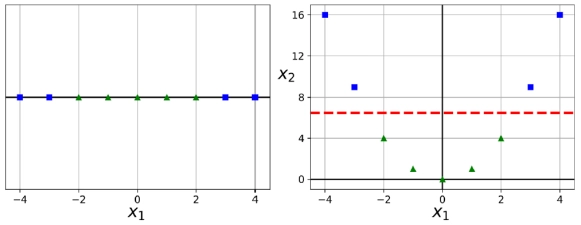 왼쪽 그림은 선형으로 분리할 수 없는 데이터셋을 보여준다.
왼쪽 그림은 선형으로 분리할 수 없는 데이터셋을 보여준다.
오른쪽 그림은 𝑥1^2 = 𝑥2를 추가하여 완벽하게 선형으로 분리할 수 있는 데이터셋을 보여준다.
- 문제점:
1. 낮은 다항식 차수에서는 매우 복잡한 데이터셋을 처리할 수 없음
2. 높은 다항식 차수에서는 모델이 너무 느려질 정도로 방대한 수의 특성이 생성됨
- 해결책:
커널 트릭(kernel trick)
→ 커널 트릭을 사용하면 실제로 특성을 추가하지 않고도 많은 다항식 특성을 추가한 것과 동일한 결과를 얻을 수 있다. 따라서 실제로 특성을 추가하지 않기 때문에 특성 수의 조합 폭발이 발생하지 않는다.
1. Polynomial Kernel (다항식 커널)
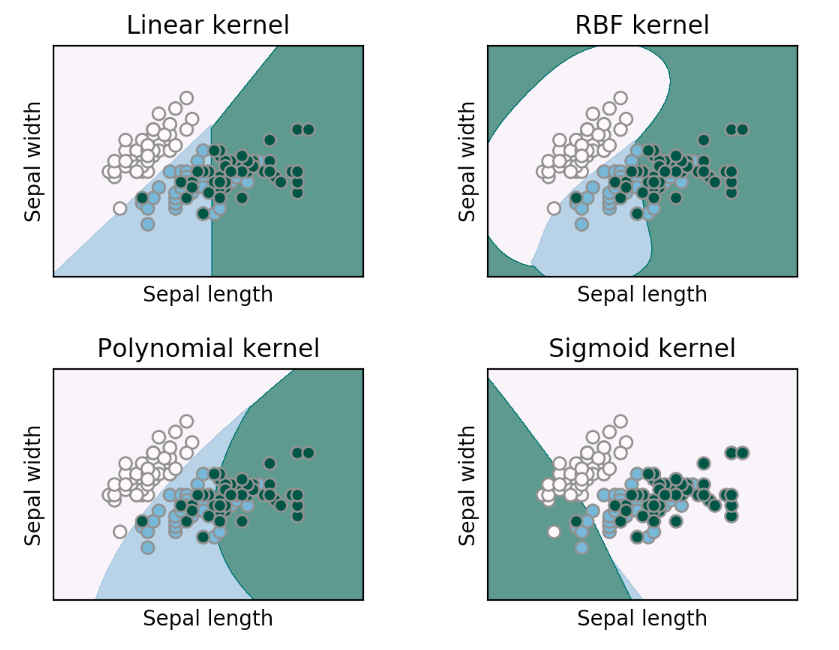
2. Gaussian RBF Kernel (RBF 커널)
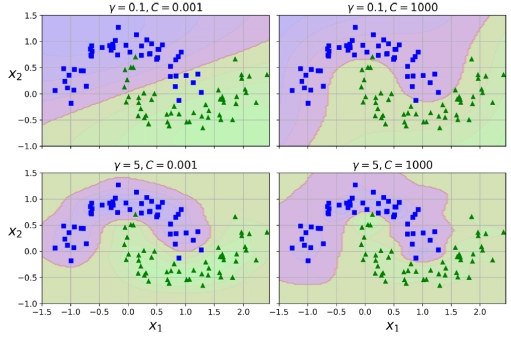
- 개념: 데이터 포인트 간의 거리를 기반으로 유사도를 계산하는 함수
✅Similarity Features
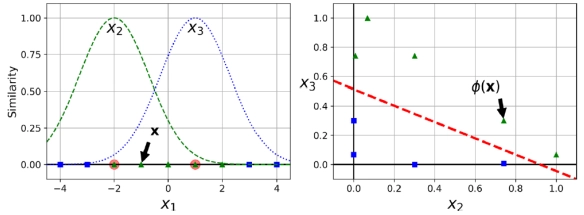
- 개념: 특정 landmark와 각 인스턴스가 얼마나 닮았는지를 측정하는 유사도 함수(similarity function)를 사용하여 생성된 특성을 추가하는 것

개발자를 꿈꾸는 대학생