1️⃣기계 학습의 종류
1. Supervised learning (지도학습): learning from labeled data
- 개념: 입력 데이터와 그에 해당하는 정답(라벨, 목표값)이 함께 주어진 상태에서 학습하는 방식
- 목적: 새로운 입력에 대해 올바른 출력을 예측
2. Unsupervised learning (비지도학습): learning from unlabeled data
- 개념: 정답(라벨) 없이 입력 데이터만 주어진 상태에서, 데이터의 숨겨진 구조나 패턴을 찾는 방식
- 목적: 데이터의 군집, 특징, 차원 축소 등을 통해 구조 파악
3. Reinforcement learning (강화학습): learning through trial and error
- 개념: 환경과 상호작용 하면서 행동을 선택하고, 보상을 받아 학습하는 방식
- 목적: 주어진 환경에서 누적 보상을 최대화하는 최적의 정책 학습
2️⃣기본 개념
1. 개념
- Sample (attribute/variable) : 행(각 데이터)
- Feature (instance/point) ****: 열(칼럼,필드)
- Structured data (정형데이터) : 표 형식으로 나타내어진 데이터
- Sample의 개수는 데이터의 개수 N이고, Feature의 개수는 총 필드 M개에서 Target Label 한개를 제외한 M-1개 이다.
2. 변수의 종류
- Categorical (범주형)
- nominal : 명목형 (ex. 성별, 혈액형)
- ordinal : 순서형 (ex. 난이도, 평점)
- Numeric (수치형)
- discrete : 이산형 (ex. 판매량, 불량품의 수)
- continuous : 연속형 (ex. 키, 몸무게, 나이)
3️⃣범주형 데이터를 표현하는 방법
1. 정수로 매핑
Red : 0 / Blue: 1, Green : 2 같은 방식으로 표현
문제점: 알고리즘이 이 값을 수치형으로 간주하여 최적이 아닌 결과를 초래할 수 있음
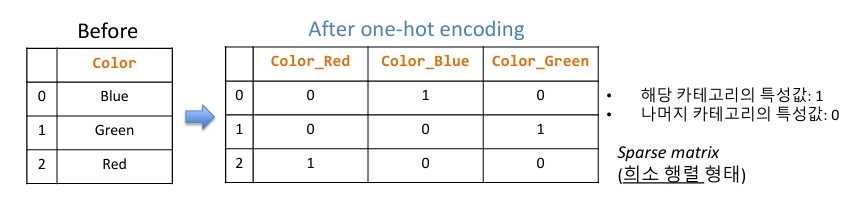
2. One hot encoding (가장 많이 사용함)
- 특정 카테고리의 모든 종류의 값을 필드로 나열 (
Red/Blue/Green) - 해당 카테고리의 특성값은 1, 나머지 카테고리의 특성값은 0으로 표현
- 그 결과, Sparse matrix(희소 행렬) 형태로 나타남.
✅체크 포인트
-
One-Hot Encoding 적용후생성되는열(column) 개수는 무엇에 의해 결정될까?
→ 해당 카테고리의 서로 다른 종류의 값 개수
-
희소 행렬의 저장과 연산을 위해 NumPy array대신 어떤 자료구조를 사용하는 것이 좋을까?
→ scipy.sparse의 희소 행렬 타입
-
이 예시에서, 3개보다 적은 수의 열로 데이터를 표현할 수 있을까?
→ 가능 / k-1인코딩, 바이너리 인코딩 등
4️⃣데이터 품질
1. Noise (노이즈)
개념: 원래의 데이터에 포함되어 있지 않아야 하는 무작위적 변형
✅해결책
- 더 많은 데이터 수집 → 노이즈 상쇄
- Binning을 통한 스무딩 → 대표값으로 안정화
- 정규화 → 모델이 노이지를 과적합하지 않도록 방지
2. Missing values (결측값)
개념: 데이터가 중간에 비어있는 것
원인:
- 데이터 수집 과정 오류: 센서 오류, 입력 실수 등
- 정보 미수집: 응답자가 특정 질문에 답변하지 않음
- 시스템적 제한: 저장 공간 문제, 네트워크 장애 등
표현 방식:
- NA (Not Available)
- 빈 칸 (blank)
- NaN (Not a Number)
- NULL
문제점:
- 편향된 결과
- 잘못된 예측
✅해결책
- 결측 데이터 제거👎
- 정보 손실의 가능성 존재
- 결측데이터 보정👍
- 열평균, 행평균, 중앙값, 최빈값(범주형일 경우)
- KNN Imputation: 가장 가까운 K개의 샘플들을 참고하여 다수결로 결정

3. Outliers (이상값)
개념: 데이터 집합에서 대부분의 값들과는 현저히 다른 특성을 가진 데이터 객체
원인:
- 측정 오류(Measurement error)
- 센서 오작동, 장비 문제, 데이터 입력 오류 등
- 사람의 실수(Human error)
- 잘못된 단위 입력, 오타, 코드 오류 등
- 자연적(outlier)
- 실제로 존재하는 극단적 값 (ex. 매우 높은 소득, 매우 긴 통화시간, 드문 자연 현상)
✅해결책
- 단순 제거 (Simple removal)
- 실제 의미 있는 데이터일 경우 정보 손실 발생 가능성
- 대체값으로 치환 (Replacement)
- 평균이나 중앙값으로 교체 (보통 중앙값을 이용)
- 예: 키=250cm 값 → 전체 평균(170cm)으로 보정
- 중앙값 사용 시 극단치에 덜 민감
- 예측 모델 기반 대체 (Model-based replacement)
- 회귀, 머신러닝 모델(랜덤포레스트, 신경망 등)로 해당 값을 예측해서 교체
✅탐지 방법
- EDA (탐색적 데이터 분석)
- 이상치(outlier) 탐지
- 가정 검증 (ex. 정규분포 여부, 왜도 확인)
- 유용한 원자료와 변환 탐색 (ex. log(x) 변환)
- 모델 기반 접근
- LOF
- Isolation Forest
- Autoencoders
5️⃣EDA (Exploratory Data Analysis) 탐색적 데이터 분석
개념: 데이터를 분석하기 전에 그래프나 통계적인 방법으로 자료를 직관적으로 바라보는 과정
방식:
- 개별 데이터 관찰
- 통계 값 활용
- 시각화 활용
- 머신러닝 기법 활용
1. 수치적 요약
- 평균(Average) : 좋은 대표값이 아님
- 중앙값(Median) : 비대칭 분포에서 중심을 잘 반영, Outlier가 있어도 크게 흔들리지 않음(=Robust함)
- 백분위수(Percentiles) : 데이터 집합을 100등분했을 때, n% 이하에 해당하는 값
- 상관계수(Correlation coefficient) : 값이 낮다고 관계가 없다고 단정지으면 안됨
- [-1,1] 구간의 값
- +1에 가까울수록: 강한 양의 선형 상관관계
- -1에 가까울수록: 강한 음의 선형 상관관계
- • 0에 가까울수록: 매우 약한 선형 상관관계
📌 수치적 요약은 너무 믿어서는 안된다. (ex. 통계적 오류 존재함)
2. 시각적 요약
-
히스토그램 (histogram)
- 목적: 수치형 데이터의 분포를 시각화
- 작성 방법:
- 데이터 범위를 일정한 구간으로 나눈다.
- 각 구간에 포함되는 데이터 개수를 센다.
- 축을 구성한다
- x축 → 변수의 값 범위(구간)
- y축 → 빈도수(해당 구간에 속한 데이터 개수)
- 장점: 대규모 데이터셋에서는 분포의 전반적 특성을 효과적으로 보여줌
- 단점:
- 소규모 데이터셋에서는 왜곡된 인상을 줄 수 있어 신뢰성이 낮음
- 단일 변수(1차원) 분포만 표현 가능
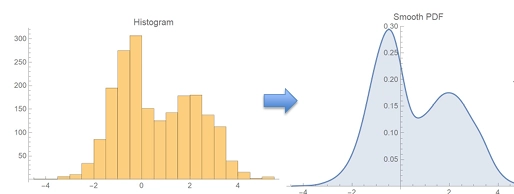
✅히스토그램의 모양
- 히스토그램의 모양을 통해서 데이터 분포를 확인할 수 있음

✅Smoothed Histograms
-
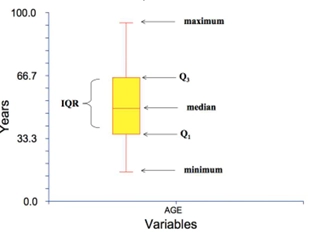
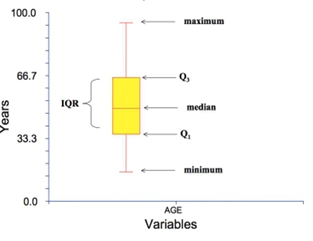
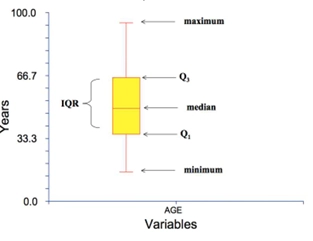
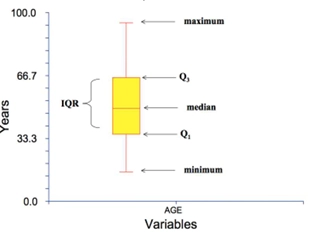
박스플랏 (Boxplot)
- 목적: 데이터의 5가지 요약 통계량(Five-number summary)을 시각적으로 표현
- 구성 요소:
- 중앙값 (Median, Q2)
- 사분위수 (Quartiles)
- Q1: 제1사분위수 (하위 25%)
- Q3: 제3사분위수 (상위 75%)
- IQR (Interquartile Range) : Q3에서 Q1을 뺀 값
- 수염 (Whiskers): 이상치가 아닌 데이터의 최소값과 최대값 (Q1 - 1.5×IQR ~ Q3 + 1.5×IQR 범위)
- 이상치 (Outliers): 수염의 범위를 벗어나는 데이터
✅바이올린 플롯 (Violin Plot)
- 박스플롯(Boxplot) + 커널 밀도 추정(KDE)을 결합한 시각화 기법
- 분포 모양까지 한눈에 보여줌
- 박스플롯의 한계 보완
-
산점도 (Scatter Plot)
-
목적: 두 개의 변수 사이의 관계를 표현
-
구성 요소:
- x축: 독립 변수(설명 변수)
- y축: 종속 변수(반응 변수)
- 점 하나: 데이터의 (x, y) 값
-
한계: 데이터 포인트들이 겹쳐 보이는 문제 → Jittering 기법 사용👍
- Jittering 기법: 각 점의 위치에 작은 무작위 노이즈를 추가하는 기법
- 원래 점들이 동일한 좌표에 겹쳐서 하나만 보이는데, Jittering기법을 이용하면 겹친 점들이 약간씩 퍼져서 여러 개로 보이게 됨
- 원래 점들이 동일한 좌표에 겹쳐서 하나만 보이는데, Jittering기법을 이용하면 겹친 점들이 약간씩 퍼져서 여러 개로 보이게 됨
- Jittering 기법: 각 점의 위치에 작은 무작위 노이즈를 추가하는 기법
-
✅범주형 변수 탐색법
- 막대 그래프 (Barchart)
- 개념: 연속형 값을 표현
- Spine Plot
- 개념: 막대그래프의 변형 형태로, 각 막대의 길이는 동일하게 두고, 내부를 비율에 따라 나눠서 표현하는 그래프
6️⃣특성 정규화
1. KNN classifier
- 새로운 데이터가 들어오면, 기존 데이터들과의 거리를 구함
- 가장 가까운 3개 데이터의 Label중, 가장 높은 비율의 Label이 새로운 데이터의 Label이 됨
 위 예시에서, 가장 가까운 3개는 x1, x2, x4이므로, Good 2개에 Bad 1개로, 새로운 x5는 Bad가 된다.
위 예시에서, 가장 가까운 3개는 x1, x2, x4이므로, Good 2개에 Bad 1개로, 새로운 x5는 Bad가 된다.
2. 정규화 (Normalization)
- 각 특성을 평균 0, 표준편차 1이 되도록 변환
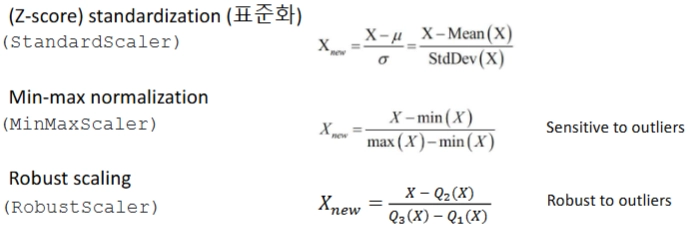
7️⃣데이터 전처리 파이프라인
✅ Step 1: 데이터 불러오기 & 탐색
import pandas as pd
df = pd.read_csv("customer_data.csv")
print(df.head())
print(df.info())- 데이터셋 로드 (
pandas) - 상위 5행 미리보기 (
head()) - 데이터 요약 정보 확인 (
info())
✅ Step 2: 결측치 & 이상치 처리
# 결측값 → 중앙값으로 채우기
df.fillna(df.median(), inplace=True)
# IQR 방법을 이용한 이상치 제거
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
df = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]- 결측값(Missing values): 중앙값(median)으로 채움
- 이상치(Outliers): 사분위수 범위(IQR) 기반으로 제거
✅ Step 3: 특성 정규화 (Normalization)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['Age', 'Income']] = scaler.fit_transform(df[['Age', 'Income']])StandardScaler를 사용하여 평균=0, 표준편차=1로 변환- 수치형 변수 간 스케일 차이 보정
✅ Step 4: 범주형 변수 인코딩
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
categorical_data = encoder.fit_transform(df[['Gender', 'Region']]).toarray()OneHotEncoder로 범주형 변수(Gender,Region)를 원-핫 인코딩(One-Hot Encoding)- 기계학습 알고리즘에서 활용 가능하게 변환

개발자를 꿈꾸는 대학생