Nemotron-CORTEXA: Enhancing LLM Agents for Software Engineering Tasks via Improved Localization and Solution Diversity Paper Review
Paper Review
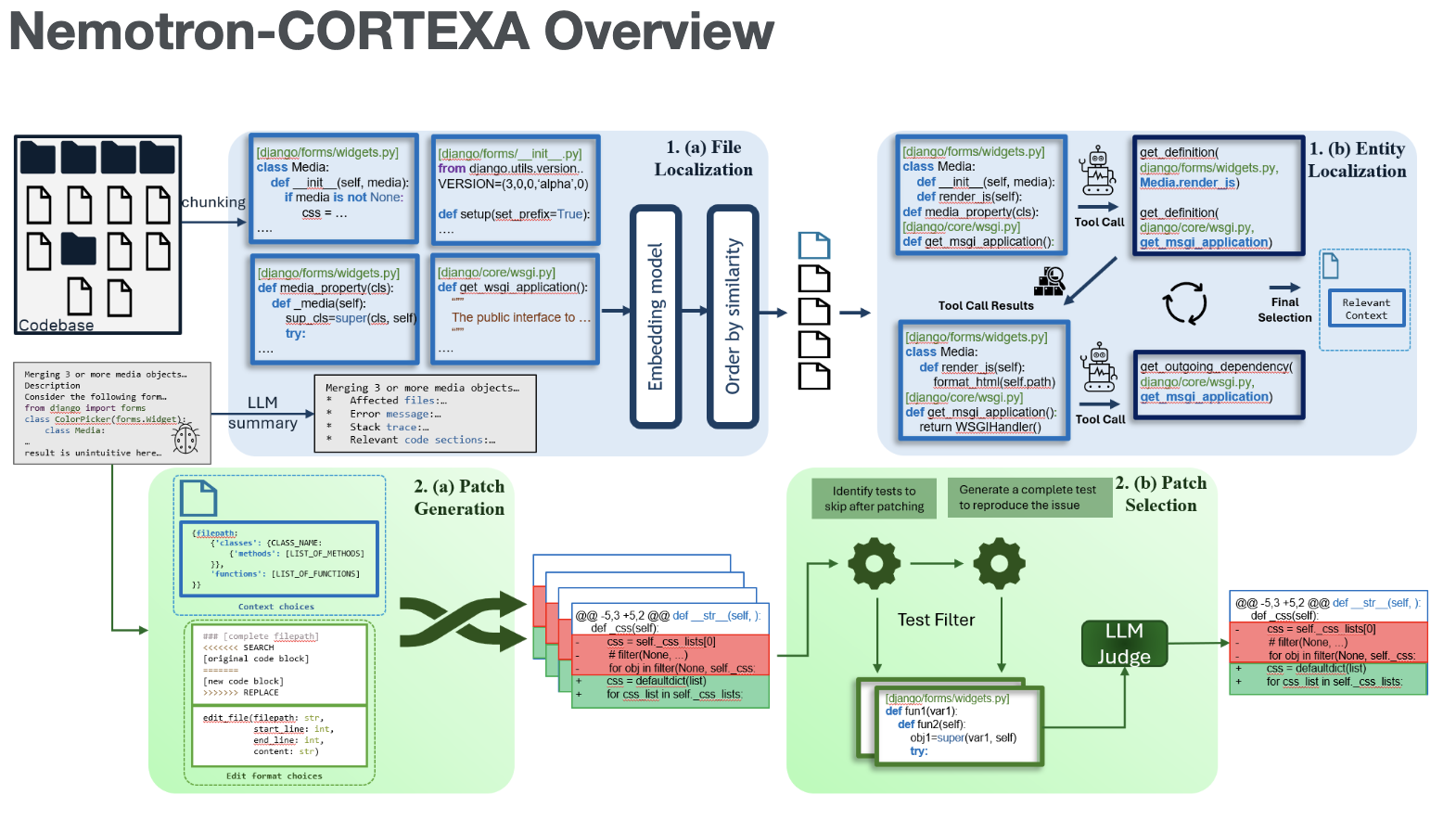
이번에 리뷰할 논문은 Nemotron-CORTEXA: Enhancing LLM Agents for Software Engineering Tasks via Improved Localization and Solution Diversity 입니다. 해당 논문은 LLM의 발전 방향성 3가지 중 2가지에 대해서 언급을 하면서 해결 방안을 새로운 관점에서 제공하고 있는 것이 특징이라고 생각했습니다.
LLM의 앞으로 미래의 연구 방향성에 대해서 크게 3가지로 많이 이야기 되고 있습니다. Multi-modal, Context window, Resoning 위와 같이 연구 방향성들이 이어지고 있습니다. 특히 해당 논문에선 Context window, Reasoning에 대해서 이야기를 하고 이를 해결하는 방법으로 새로운 관점에서 이야기를 풀어가고 있습니다. 해당 논문에서는 이를 해결하기 위해서 컨텍스트 정보를 최적화하고, 모델이 이 컨텍스트를 활용하는 방식을 개선하여 다양한 컨텍스트 정보를 제공하고 다양한 프롬프트 형식을 활용하여 문제를 해결하고자 합니다.
아래에서 Instance와 Patch, solution이라는 단어들이 나오는데 저는 이 3가지 단어들에 대한 이해가 논문을 읽으면서 어려움이 있었기 때문에 먼저 이야기해 보겠습니다. Instance의 경우 해결해야 할 개별적인 소프트웨어 문제 또는 Task 자체를 의미하고 있습니다. 즉, 코드의 버그 하나, 특정 기능 요구가 될 수 있습니다. Patch의 경우, 특정 인스턴스를 해결하기 위해 LLM이 생성한 코드 변경 사항을 의미합니다. 이는 버그를 수정하거나 기능을 추가하는 등의 동작입니다. Solution이 Patch와 같이 사용이 되는데 이는 인스턴스의 대한 해결책으로 patch와 같은 의미를 하고 있습니다.
비유를 하자면 자전거가 고장난 상황이 인스턴스를 의미하고 있으며 자전거가 앞으로 나아가게 하기 위해서 타이어 펑크를 수리했다면 이것이 Patch가 되는 겁니다. 더불어 타이어 펑크를 고쳐서 자전거가 다시 앞으로 나아간다면 타이어 펑크 수리가 솔루션이 되는 겁니다.
이제 본격적으로 논문에 대해서 리뷰해보도록 하겠습니다.
Abstract

LLM을 통해서 코드를 생성하는 분야에서 높은 수준의 잠재력을 보여줬습니다. 그러나 디버깅이나 전체 저장소(repository) 수준의 기능 구현(새로운 기능을 추가할 때, 하나의 파일만 수정하는 것이 아니라, 여러 관련 파일을 업데이트하고, 새로운 테스트 케이스를 작성하며, 기존 시스템과의 통합을 고려하는 것)과 같은 실제 소프트웨어 엔지니어링 작업은 현재 LLM의 컨텍스트 윈도우(context window) 크기를 훨씬 뛰어넘는 방대한 양의 코드를 처리해야 합니다. 이로 인해서 LLM이 문제 해결에 필요한 모든 관련 코드와 정보를 동시에 볼 수 없으므로, 정확하고 효과적인 코드 생성 및 수정이 어려운 상황에 직면한다고 생각합니다. 그 다음 문제로는 표준 자동 회귀 디코딩(standard autoregressive decoding) 방식을 사용하는 LLM은 복잡한 추론(complex reasoning)을 수행하는 데 취약합니다. 이는 모델이 한 번에 하나의 토큰을 예측하며 순차적으로 텍스트를 생성하는 방식의 본질적인 한계라고 생각합니다. 이로 인해서 모델 답변의 퀄리티와 일관성 측면에서 성능 하락으로 이어진다고 이해했습니다.
본 논문에서는 위의 두가지 문제를 해결하고자 LLM에 제공되는 컨텍스트 정보를 최적화하고, 모델이 이 컨텍스트를 활용하는 방식을 개선하며, 개발 환경을 효과적으로 탐색할 수 있는 도구를 통합하는 것으로 'NEMOTRON-CORTEXA'를 제안하였습니다.
'NEMOTRON-CORTEXA' 사전 정의된 스캐폴드에 구축된 에이전트 시스템이라고 이야기 하고 있습니다. 이는 미리 정해진 구조화된 프레임워크 위에서 작동하며, LLM이 소프트웨어 엔지니어링 작업을 효율적으로 수행할 수 있도록 합니다. 특히, 해당 제안은 크게 3가지 측면에서의 개선점이 있는데 이는 다음과 같습니다.
NEMOTRON-CORTEXA는 특히 파일 검색 정확도와 엔티티 수준의 문제 위치 파악 능력을 크게 향상시키고, 다양한 해결책 생성 전략을 통해서 문제 해결에 필요한 Cost를 낮추고 해결력을 향상 시켰습니다.
먼저, Localization part를 보면 문제 설명(issue description)을 바탕으로 가장 관련성 높은 파일들을 높은 정확도로 검색하여 기존의 임베딩 모델 혹은 프롬포트 기반 접근보다 더 우수한 성능을 보였습니다. 그 다음으로 Localiation agent를 통해 파일 단위의 검색을 넘어, 문제 해결에 필요한 특정 함수, 클래스, 메서드와 같은 코드 엔티티(entity)를 더욱 세밀하게 파악이 가능해졌습니다.
그 다음으로 Solution Diversity part를 보시면, 다양한 컨텍스트 정보와 여러 프롬프트 형식을 활용하여 모델이 더 효율적으로 문제를 식별하고 해결책을 생성합니다. 이는 기존의 온도 샘플링(temperature sampling) 방식보다 적은 추론 호출로 더 많은 문제 해결을 가능하게 합니다
Introduction
LLM의 최근 발전은 글쓰기 분야에서부터 분석적 추론에 이르기까지 다양한 영역에서 놀라운 능력을 입증했습니다. 특히, 소프트웨어 엔지니어링 분야에서 LLM의 성능은 꽤 광범위하게 인정받고 있습니다. 이러한 발전을 바탕으로 프로그래밍에 대한 LLM의 연구 방향성은 스니펫('스니펫'은 LLM이 처리할 수 있는 코드의 최소/초기 단위를 지칭하는 개념) 및 함수 수준의 생성에서 실제로 문제를 처음부터 끝까지(end-to-end) 해결할 수 있는 LLM 코딩 에이전트를 개발하는 방향성으로 전환되었습니다.
위와 같은 LLM의 발전 방향성은 디버깅 및 Repository에서 Patch 적용과 같은 중요한 작업을 수행하기 위해서 Command Line Interfaces (CLI) 및 Integrated Development Environments (IDE)를 포함하여 사람이 일반적으로 사용하는 도구를 활용할 수 있도록 하는 것을 목표로 했습니다. 이를 위해서 이전에는 코딩 에이전트 즉, 에이전트가 시스템 프롬프트에 따라 자유 형식의 액션 시퀀스를 수행하도록 하였습니다. 그러나 해당 솔루션은 넓은 액션 공간으로 인해 많은 비용이 드는 반복(costly iterations)과 디버깅의 어려움이 있습니다. 그렇기에 이를 완화하기 위해 Agentless의 경우, LLM을 미리 결정된 단계 시퀀스를 통해 안내하는 보다 구조화된 접근 방식을 사용합니다. 이러한 발전에도 불구하고, 문제를 정확하게 찾고 올바른 수정을 생성하는 데에는 여전히 어려움이 있습니다.
즉, 해당 논문에서 제안하는 'NEMOTRON-CORTEXA'는 소프트웨어 엔지니어링 분야에서 LLM 에이전트의 성능을 향상시키기 위해 NEMOTRON-CORTEXA라는 코딩 에이전트 시스템을 소개하며, 특히 문제 Localization(문제 발생 지점 식별)과 다양한 해결책 생성 강화에 기여를 하였습니다.
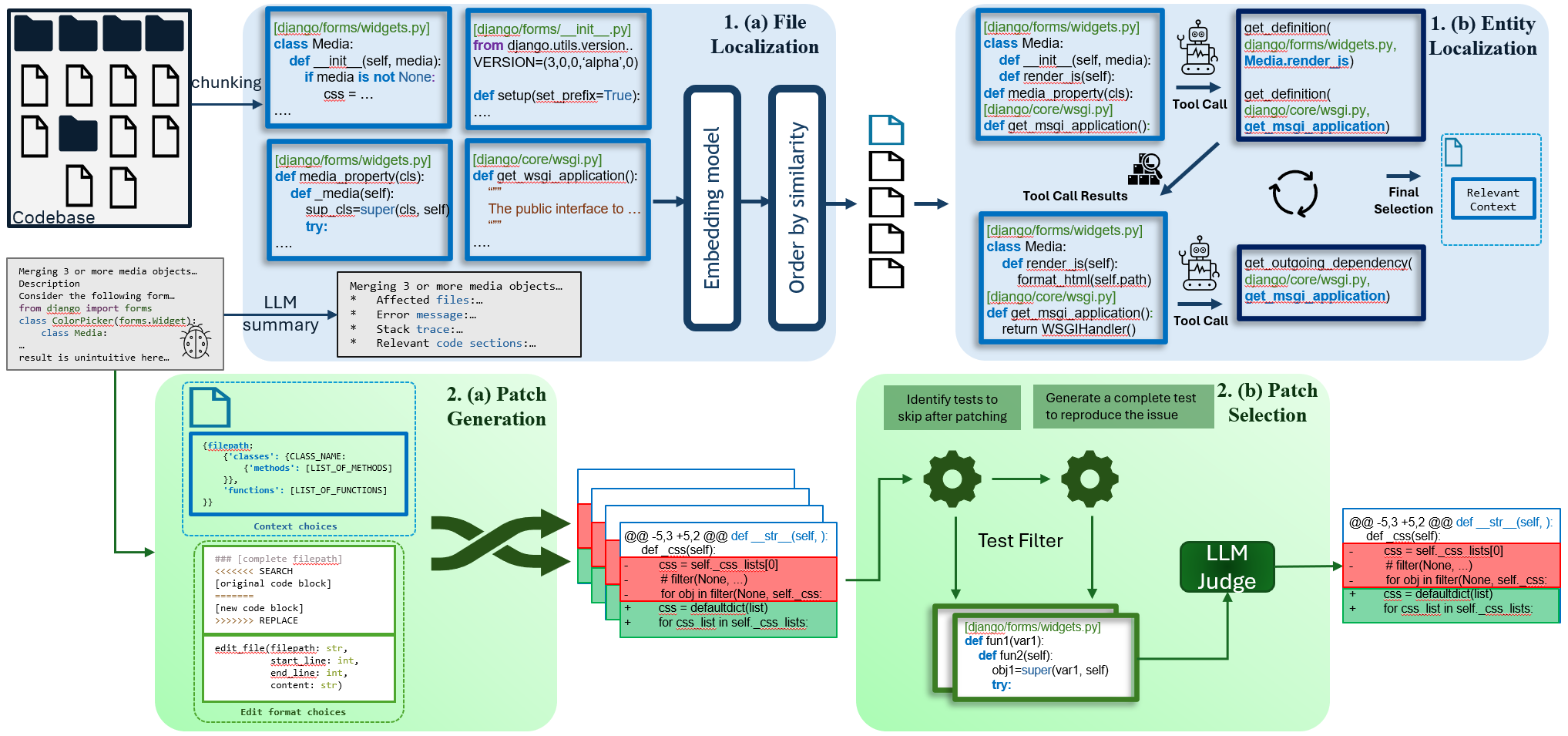
1. 향상된 Issue localization
- 해당 기여의 의의는 버그와 관련된 파일을 더욱 정확하게 검색하도록 최적화된 코드 임베딩 모델을 개발한 것입니다. 이로 인해서 파일 단위의 Localization 정확도를 높입니다.
- Abstract Syntax Tree (AST) 및 Language Server Protocol (LSP) 기반의 프로그래밍 도구를 활용하여 다단계 추론을 통해 효율적이고 간결한 코드 탐색을 가능하게 합니다.
- Localization 정확도를 높이고 수리 프로세스에 도움이 되는 추가 관련 코드 요소를 식별하기 위해 여러 LLM을 앙상블(ensemble)하는 접근 방식을 채택했습니다. 이는 서로 다른 LLM이 특정 문제 유형에서 특히 뛰어난 성능을 보인다는 관찰에서 영감을 받았습니다. 즉, 특정 LLM이 정확한 엔티티를 식별하지 못하더라도, 밀접하게 관련된 엔티티를 식별하는 경우가 많기 때문에 앙상블을 통해 안정성과 성능을 함께 챙길 수 있었다고 생각합니다.
AST는 소스 코드의 추상적인 구문 구조를 트리 형태로 표현한 것입니다. 우리가 작성하는 코드는 단순히 텍스트 문자열이지만, 컴퓨터가 이해하고 처리하기 위해서는 이 텍스트가 어떤 의미를 가지는지, 어떤 구조로 되어 있는지 파악해야 합니다. AST는 이 '의미 있는 구조'를 시각화하고 프로그램적으로 접근할 수 있게 해줍니다.
LSP는 코드 편집기나 IDE(클라이언트)와 특정 프로그래밍 언어의 "언어 서버(language server)"(서버) 간의 통신을 위한 표준화된 프로토콜입니다.
2. Repair generation -> 다양한 솔루션 생성 방법
- 패치(patch) 생성 단계에서 다양한 컨텍스트 정보와 여러 프롬프트 형식을 활용하는 간단하고 효율적인 방법을 개발했습니다.
- 이 접근 방식은 기존의 온도 조절 샘플링(temperature sampling)보다 뛰어난 성능을 보여주며, 적은 추론 호출(Agentless 대비 4.4배 감소)로 더 높은 문제 해결률을 달성합니다.
Related Works
해당 논문에서 관련 연구 소개로 3가지에 대해서 언급을 하고 있으며 이에 대해서 하나씩 리뷰해보도록 하겠습니다.
- LLMs for Code Generation
-
LLM의 코드 생성 능력은 주로 코드 데이터에 대한 지속적인 사전 학습(continued pre-training)을 통해 성능 향상을 이루어졌습니다.
-
이후에는 크게 두가지 방향성으로 코드 생성 능력을 위한 솔루션이 진행되어지고 있습니다. 강화학습(Reinforcement Learning), 명령어 미세 조정(Instruction Fine-tuning)으로 이어지고 있습니다. 일반적으로 Instruction Fine-tuning을 강화학습 전략 대신에 채택하여 활용하고 있습니다.
- 이를 통해서 솔루션 정확도 보장과 코드 검증 및 디버깅 개선에 기여하였습니다.
2.LLM Agents for Software Engineering
-
LLM의 소프트웨어 엔지니어링 연구 초기에는 단순히 코드 스니펫이나 함수를 생성하고 Interview style의 프로그래밍 문제를 해결하는 데 집중했습니다. 그러나 최근에는 end-to-end를 목표로 실제로 활용 가능한 Application에 집중하고 있습니다. 그렇기에 LLM이 사람들이 사용하는 CLI 혹은 IDE와 같은 도구를 활용하여 직접 수행할 수 있도록 하고 있습니다.
-
다양한 연구들이 이루어졌으며 언급하고 있는 이전 연구들은 4가지가 있습니다. 먼저 Free-form 에이전트의 경우, 시스템 프롬프트에 의해 가이드 되는 자유 형식의 액션 시퀀스를 허용했습니다. 하지만 이는 이전에 언급했듯이 비용이 많이 들게 되며 반복을 초래하여 디버깅이 어렵다는 한계가 존재하였습니다. 두 번째로는 미리 정해진 단계 별 프로세스를 통해서 LLM을 통해 문제를 해결하고자 한 Structured 에이전트가 있었습니다. 세 번째로는 Abstract Syntax Tree(AST) 기반의 코드 검색 도구를 구축하고 멀티 에이전트 시스템은 각 서브테스크에 특화된 에이전트를 개발하여 문제를 분할 해결하는 전략을 가져갔습니다. 마지막으로는 반복적인 접근 방식과 Self-Reflection 프레임워크 내에서 자기 피드백을 통합하는 연구가 이어졌습니다.
- Code retrieval
-
Code retrieval의 경우, 코드 요약 및 문서 조회(code summarization, documentation lookup) 등 다양한 소프트웨어 개발 경역에서 매우 중요한 작업이며 최근에 더욱 강조되어지고 있습니다.
-
BERT 기반 모델들이 코드 전용 임베딩 모델 개발의 초기 노력에 해당합니다. 하지만 코드 검색 그 자체를 목표로 하는 모델들은 상대적으로 연구들이 적어졌으나 Voyage AIdhk OpenAI의 경우엔 주목할 만한 연구들입니다.
-
최근에는 텍스트 검색 작업을 위해서 Decoder-only LLM 기반 임베딩 모델 개발에 대한 관심이 증가하고 있습니다. 특히 CodeXEmbed의 경우 범용 코드 임베딩 모델 패밀리가 등장하게 되었으며 다양한 코드 검색 작업에서 뛰어난 성능을 보여줬습니다.
위의 3가지 관련 연구를 설명하면서 본 논문이 제안된 배경에 대해서 정리해봤습니다.
1. LLM의 코드 생성력에 대한 강력한 잠재력에 대해서 실제 복잡한 문제 해결로 확장 필요성에 대해서 이야기했습니다.
-
에이전트의 발전과 Issue localizaion과 Repair generation 분야에서의 정확성과 효율성에 대한 필요성에 대해 언급했습니다.
-
이전에 이루어진 일반적인 코드 검색의 한계성에 대해서 이야기하며 Issue를 식별하기 위해서 다른 접근이 이루어져야 한다고 이야기했습니다.
NEMOTRON-CORTEXA
1. Overview of the Pipeline
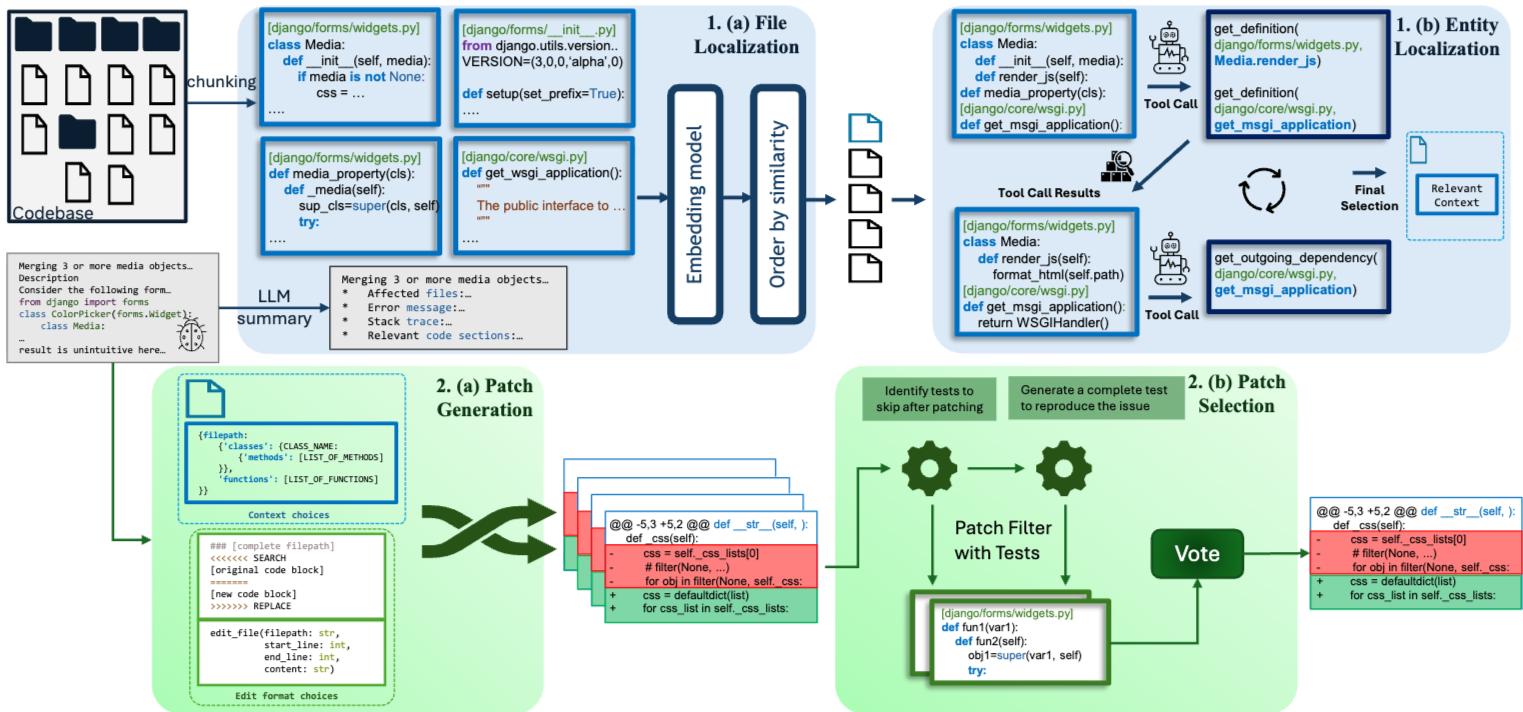
현존하는 LLM의 Context window는 소프트웨어 엔지니어링 분야에서 전체 코드베이스를 처리하기에는 너무 작은 상황입니다. 특히 Issue 해결에 적합하면서도 충분한 Context를 제공하기 위해서 관련 파일에 대한 Sub-Sampling이 이루어져야 합니다. 일반적으로 Issue description의 경우, 1000개 미만의 토큰을 요구하는 반면에 Repository 코드베이스의 경우 훨씬 더 많은 토큰을 처리해야 합니다. 예를 들어, SWE-bench의 Issue Description은 평균 1000 토큰 미만이지만, 관련 코드베이스는 평균 195단어의 Issue decription에 438,000라인의 코드 갖습니다. 따라서 Issue Desciption과 Solution에 적합한 Context를 형성하는 관련 Sub Samplig이 중요합니다. 이 방식은 모델의 올바른 Context 생성과 함께 관련이 없는 정보를 필터링하는데 많은 도움이 됩니다. 따라서 Agentless와 유사하게 위 사진을 보면 Localization과 Repair Generation 두 가지 주요 단계로 볼 수 있습니다.
먼저, Localization의 경우, 두 가지의 주요 단계로 나뉘게 됩니다. 먼저 Issue와 가장 관련성이 높은 파일을 식별하는 Step을 수행하게 됩니다. 이때, 본 논문에서 제안하는 특화된 코드 임베딩 모델이 사용이 되며 'NV-EmbedCode'가 활용됩니다. 그런 다음 특정 함수, 클래스 또는 메서드와 같은 더 세분화 된 엔티티로 문제의 위치에 집중하도록 검색의 세분성을 조정하게 되고 이를 위해서 Localization Agent가 활용됩니다.
그 다음 Repair Generation 단계에서는 Patch의 다양성을 높이기 위해서 Localization에서 얻은 정보와 다양한 Context와 Prompt를 결합하여 여러 후보 Patch를 생성하게 됩니다. 이후, 가장 적합한 Patch를 선택하기 위해서 필터링 과정을 수행하게 됩니다.
위 두 가지 단계를 통해서 기존 LLM 기반 에이전트들이 겪는 컨텍스트 부족 및 복잡한 추론 문제를 해결하고 실제 소프트웨어 엔지니어링 작업에서의 효율성과 정확성을 향상시키는 것을 목표로 합니다.
2. File Localization with Code Embedding Model

Issue와 관련된 파일을 정확하게 Localization하는 것은 전체 파이프라인의 성공에 필수적인 요소로 동작하게 됩니다. 특히, 해당 단계에서 실패하게 되는 경우 모델은 효과적인 Patch를 생성할 수 없으므로 파이프라인의 나머지 부분은 무의미해지게 됩니다. 이를 해결하기 위해서 기존의 Agentless 방식에서는 Linux tree 명령어와 유사하고 간경한 Repository representation을 생성하고 LLM에 제공하여 상위 N개의 의심스러운 파일을 식별합니다. 또한 Embedding model을 사용하는 연구들도 이어졌으나 Embedding 기반 접근 방식이 프롬포트 기반 접근 방식보다 성능이 떨어지는 결과들이 존재하였습니다. 그러나 Prompt 기반 접근 방식에는 자체적인 제한 사항들이 존재했습니다. LLM은 파일 이름만을 기반으로 결정을 내리도록 동작하기에 정확도가 낮아지거나 이러한 Repository에 대한 사전 지식에 의존할 수 있습니다. 반면에 전체 코드베이스를 처리하고 각 파일의 전체 내용을 전달하는 것은 매우 큰 비용을 요구하게 됩니다. 이를 해결하기 위해서 Issue Description을 기반하여 가장 관련성이 높은 파일을 검색하도록 특별히 훈련된 Code Embedding model을 개발하였습니다. NV-EmbedCode1이라고 하는 Code Embedding model은 양방향 어텐션과 평균 풀링을 사용하는 기존 텍스트 기반 임베딩 모델에서 미세 조정되어 제안하게 되었습니다.
NV-EmbedCode1의 작동 방식에 대해서 알아보도록 하겠습니다.
-
먼저, Oracle File을 식별하게 됩니다. 이슈를 해결하기 위해서 편집이 필요한 파일을 찾는 것을 목표로 수행합니다.
-
그 다음으로 File에 대한 Chunking 및 Meta data를 생성합니다. 파일을 통째로 전부 활용하기에는 어려움이 존재하기 때문에 LLM이 감당하고 이해할 수 있는 범위 내로 파일을 작은 Chunk 단위로 나누게 됩니다. 이때, 각 chunk에 대해서는 chunk에 대한 컨텍스트를 유지할 수 있도록 전체 파일 경로와 같은 메타 정보가 접두사로 붙게 됩니다.
-
이후, Issue와 Code Compile을 수행하게 됩니다. 이슈와 코드 편집을 매핑하는 데이터셋을 구축하게 되며 이때, Issue 관련성이 있는 Oracle file의 chunk와 meta data를 기반으로 수행하게 됩니다.
-
이후, LLM이 issue description을 생성하게 됩니다. 이때, Issue description에 불필요한 정보가 있거나 불충분한 정보(패키지 버전 및 모호한 버그 코드)가 존재할 수 있습니다. 이들을 해결하기 위해서 LLM을 통해서 파일 이름, 함수, 에러 메시지 등 다양한 관련 정보를 담은 간결한 summary를 생성하게 됩니다. 만들어진 summary와 이전에 이슈와 코드 편집을 매핑하는 데이터셋과 함께 모델 학습에 활용하게 됩니다.
-
훈련 데이터셋에 대한 증강을 수행합니다. 이 과정에서는 모델의 코드 데이터 이해도를 높이기 위해서 text-to-code, code-to-cod 등의 검색 작업을 위한 공개 데이터셋을 추가합니다.
-
다음으로 Instruction Template(“Instruct: {dataset instruction}\n Query: {query}”)를 사용하게 됩니다. 모델이 다양한 데이터셋을 구분할 수 있도록 Query 앞에 데이터셋 별 지시 사항을 추가합니다. 이 과정에서 Average Pooling을 수행하게 되는 경우 Instruction tokens을 masking 처리를 하게 됩니다.
-
마지막 단계로 Constastive Leanring을 수행하게 됩니다. Query와 관련이 있는 부분에 대한 유사성을 최대화 하고 관련이 없는 부분에 대해서는 유사성을 최소화하도록 모델을 훈련하게 됩니다. FN 가능성을 낮추기 위해서 'positive-aware hard-negative mining' 기법을 활용하게 됩니다. 더불어 각 batch는 모든 데이터 세트의 샘플을 포함하지만 positive와 negative sample 간의 충돌을 방지하기 위해서 in-batch negative 사용은 피하게 됩니다. 이는 oracle 파일을 chunking하여 positive passage를 생성할 때 발생하며, 단일 쿼리가 여러 positive passage에 해당할 수 있기 때문입니다. 이러한 쿼리-positive 쌍이 동일한 batch에 나타나면 오해의 소지가 있는 negative 샘플과 positive 샘플로 이어질 수 있기에 in-batch negative 전략을 사용하지 않음으로 피하게 됩니다.
3. Entity Localization with Localization Agent
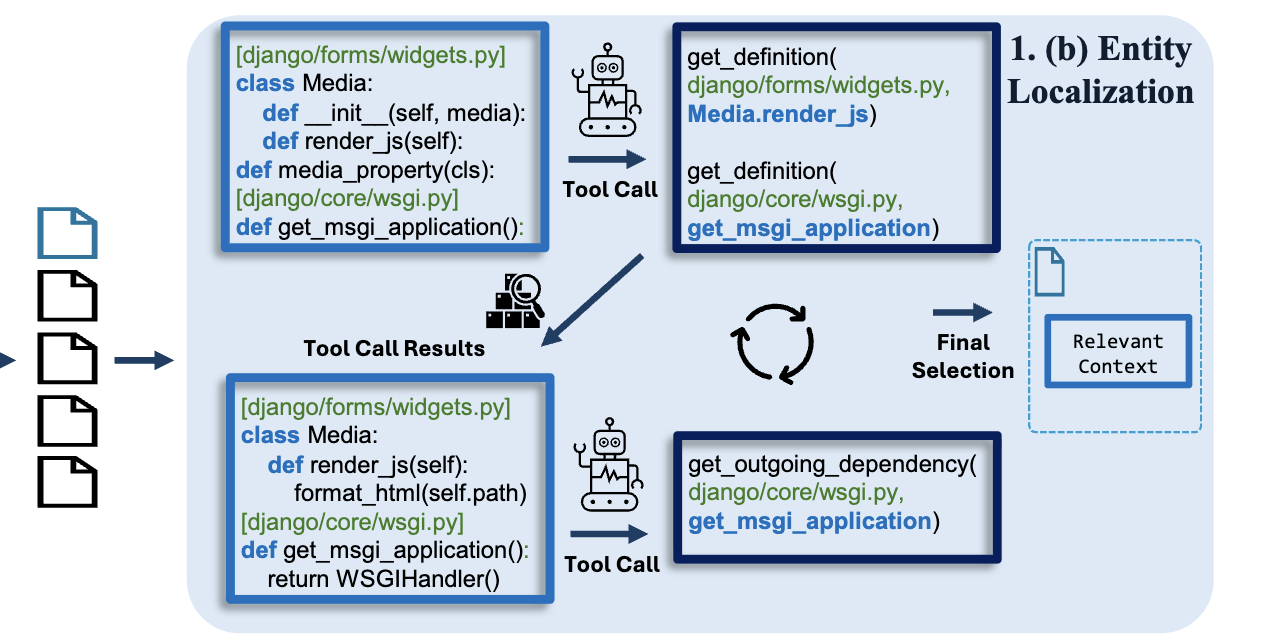
Code Embedding model을 사용하면 문제와 관련된 파일 목록을 짧게 얻을 수 있습니다. 그러나 이러한 파일의 전체 Text는 종종 모델의 context window를 초과합니다. 그렇기에 Issue 위치를 더 좁혀야 할 필요가 있습니다. 코드 파일은 클래스 및 함수와 같은 high-level entity로 구성되므로 localization의 다음 단계는 상위 순서 파일에서 후보 entity를 식별하는 것을 목표로합니다. Agentless는 각 파일의 skeleton 형식을 제공하고 관련 항목을 선택하도록 LLM에 요청하는 Direct propmting 방식을 사용합니다. 그러나 해당 방식의 경우 코드 내용에 Access하지 않으면 모델에 정확하게 응답할 수 있는 충분한 Context가 없는 문제가 발생하게 됩니다.
위의 문제를 해결하기 위해서 Information foraging theory에서 영감을 받아 definitions와 call stacks를 조회하고 추척하는 것과 같은 일반적인 작업을 수행하여 Repository를 반복적으로 탐색하는 Localization Agent를 개발했습니다.
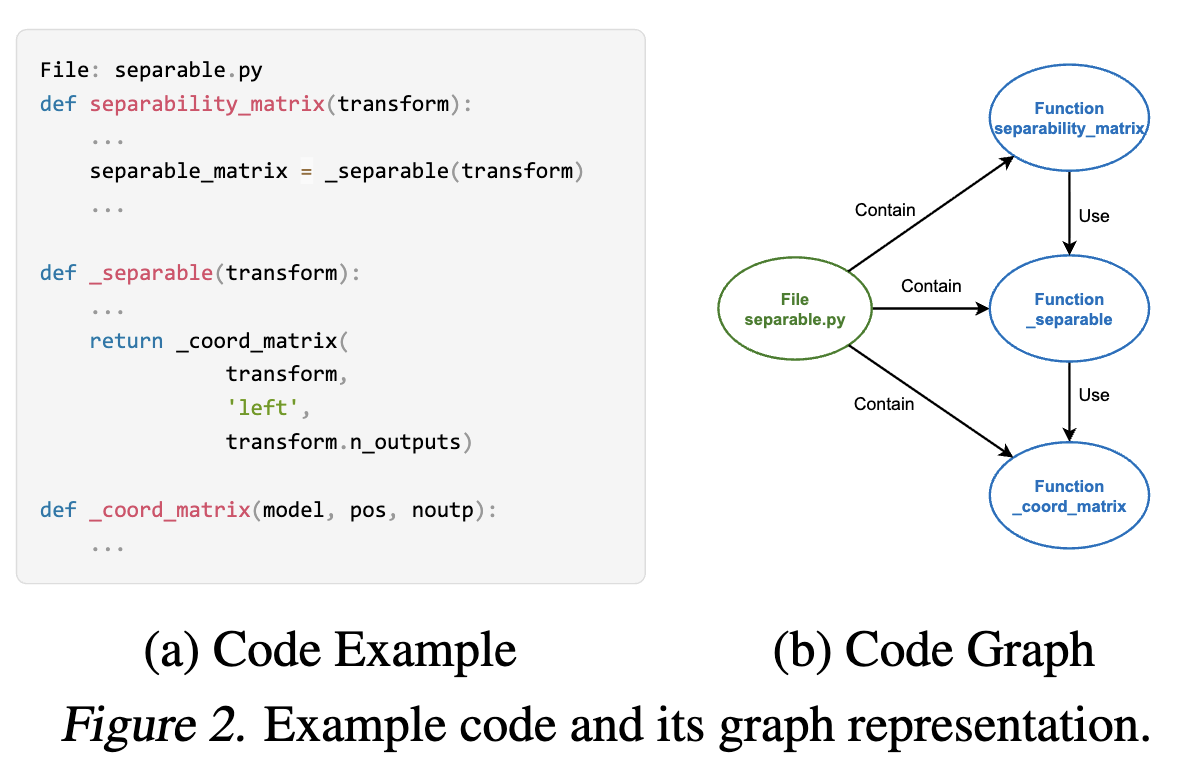
-
저장소의 구조화된 탐색을 용이하게 하기 위해 그래프 표현을 구축하는 것으로 시작하게 됩니다. 노드는 AST를 활용하여 추출된 코드 파일 및 entity(함수, 클래스, 메서드 등)를 나타냅니다. 각 노드는 해당 코드 텍스트와 해당 위치의 메타데이터를 저장하게 됩니다. edge의 경우에는 contain 및 use의 두가지 유형의 directed edge를 설정하게 됩니다. contain edge는 계층 적 관계를 설정하여 파일과 해당 함수 및 클래스를 연결하고 클래스와 해당 메서드를 연결하여 에이전트에게 repository의 구조적 보기를 제공하게 됩니다. 더불어 use edge를 통해서 함수 호출 및 클래스 인스턴스화를 포함한 기능적 종속성을 캡쳐하여 서로 두 edge의 상호 보환적으로 동작하게 됩니다.
-
위에서 만든 그래프를 탐색할 수 있는 세가지 도구를 Localization agent에 추가합니다. 이러한 도구들을 구현하기 위해서 LSP 서버를 활용했으며 3가지 도구들은 다음과 같습니다.

- get definition(파일 이름, 엔티티 이름): 요청된 파일에서 지정된 엔티티의 코드 정의를 반환합니다.
- get incoming dependency(파일 이름, 엔티티 이름): 들어오는 edeg list를 사용하여 지정된 엔티티의 소스 노드의 정의 코드를 반환합니다.
-
get outgoing dependency(파일 이름, 엔티티 이름): 나가는 edge list를 사용하여 지정된 엔티티의 대상 노드의 정의 코드를 반환합니다.
해당 논문이 제안되는 시기에 동시에 다른 연구에서는 AST와 LSP를 사용하여 repository에서 코드 지식 그래프를 구축하게 됩니다. 해당 논문에서 제안하는 방식의 경우엔 high-level entity(함수, 클래스, 메서드 등)에만 집중하고 표준 LSP 함수를 기반으로 구축된 3가지의 추가 도구를 제공한다는 점에서 차이가 존재합니다.
-
Localization agent는 code embedding model의 파일 순쉬 지정 결과를 활용하여 상위 순위의 파일에 집중합니다. 이러한 파일에 대한 high-level entity(함수, 클래스, 메서드 등)의 definition signature들만 포함하는 간결한 표현을 만들게 됩니다. 이러한 definition signature와 Issue description과 결합되어 Issue Description과 관련된 몇 가지 entity를 식별하기 위해 LLM에 입력됩니다. 이 단계는 의심스러운 파일을 식별한 후 Agentless의 Direct propmting 방식과 유사합니다.
-
다음으로, Localization agent는 선택한 entity의 전체 코드를 검사하고 도구를 사용하여 관련된 entity에 대한 질문을 합니다. 각 도구 호출은 에이전트가 향후 쿼리를 위해 컨텍스트에 저장하는 새로운 코드 스니펫 모음을 반환하게 됩니다. 에이전트는 충분한 컨텍스트를 수집하기 위해 repository와의 여러 상호 작용을 반복적으로 수행하게 됩니다. 이때, 과도한 도구 호출의 경우 context 과부화로 이어질 수 있으므로 에이전트는 컨텍스트를 필터링하고 관련 항목만 memory-buffer에 유지하는 것으로 합니다. 몇 번의 반복 후, localization agent는 문제를 해결하기 위해 수정해야 하는 최종 entity 집합을 선택하라는 메시지가 표시됩니다.
위에서 설명한 동작 과정에 대해서 간략하게 표현하자면 아래 사진과 같습니다.

4. Diverse Patch Generations
Issue를 Localize하고 특정 의심스러운 entity로 좁힌 후 다음 단계는 문제를 해결하는 패치를 생성하는 것입니다. 해당 단계에서는 LLM에 제공된 Code context를 기반으로 patch를 생성하라는 메시지가 표시됩니다. 전체 코드를 생성하는 대신 LLM은 일반적으로 generate only the edit, search/replace format, git diff format 으로 편집 내용만 생성하라는 메시지가 표시됩니다. 이는 Context 및 Prompt 형식의 선택은 생성된 patch의 정확성에 상당한 영향을 미쳐 다양한 해결된 인스턴스 집으로 이어지기 때문에 해당 방식을 채택하였습니다. 특히, LLM은 요청된 편집 형식에 매우 민감하여 다른 요소를 일정하게 유지하더라도 patch만 변경하면 종종 다른 solution을 생성할 수 있게 됩니다.
이에 대해서 더 자세히 알아보도록 하겠습니다. SWE-bench의 인스턴스에 대한 두 가지 특정 편집 형식의 효과에 대해서 집중하여 보도록 하겠습니다.
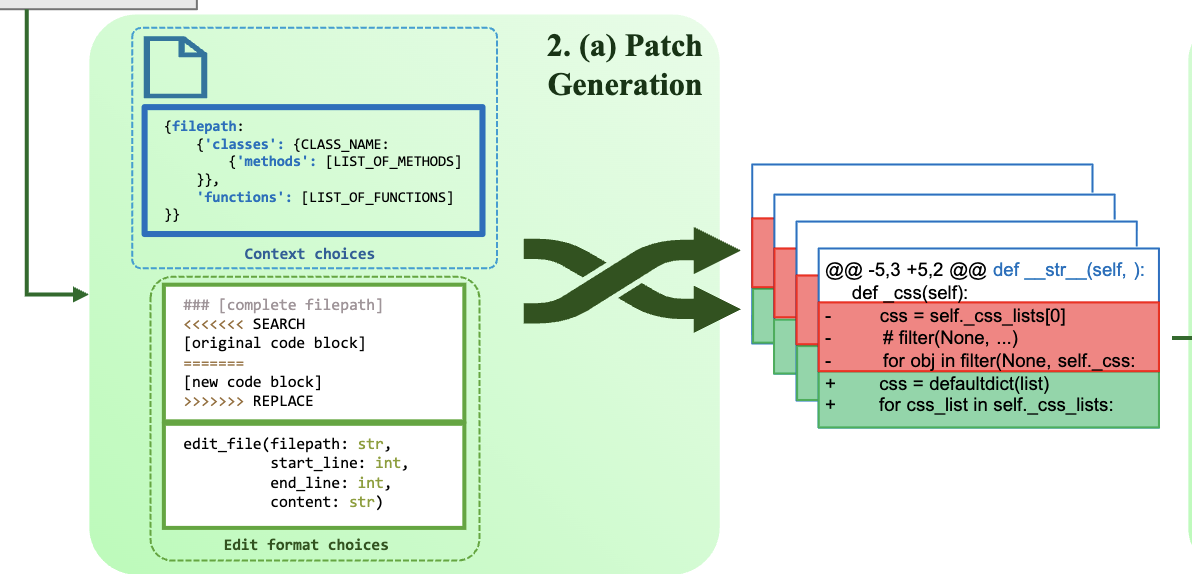
먼저, Search/replace 형식이라고 하는 첫 번째 형식은 대체될 원래 코드 스니펫을 포함하는 검색 구성 요소와 대체 contents를 지정하는 바꾸기 구성 요소로 구성됩니다. 두 번째는 편집할 file의 파일 경로, 코드의 시작 및 끝 line의 대한 번호, 삽입 및 수정할 contents를 지정하는 편집 파일 API입니다. 또한, 프롬프트의 코드 섹션 내에서 두 가지 다른 context의 효과에 대해서 형가를 수행했습니다.
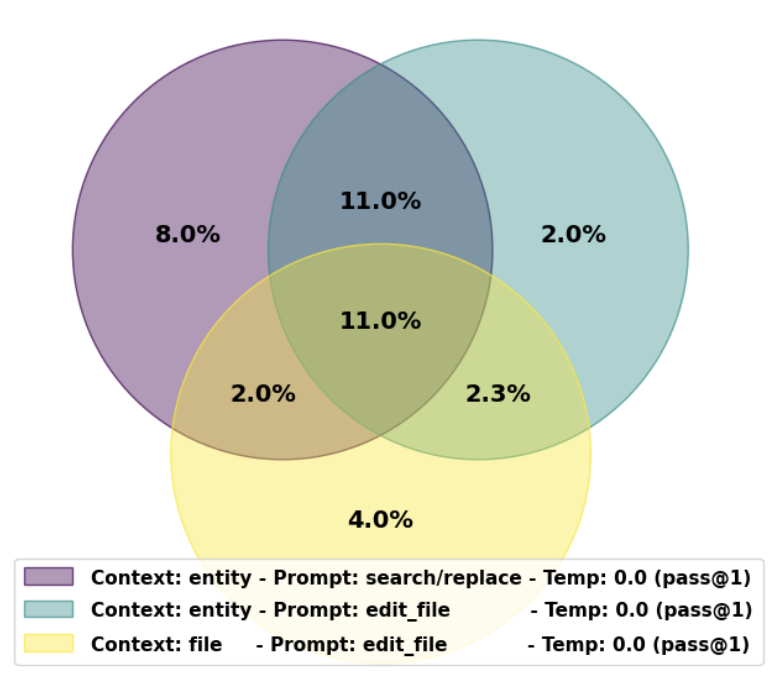
해당 사진은 위에서 언급한 context 및 edit 형식 선택을 변경할 때 해결된 인스턴스의 벤 다이어그램을 보여줍니다. 각 섹션의 숫자는 해당 하위 집합에 속하는 SWE-bench Lite에서 해결된 인스턴스의 백분율을 의미합니다. 먼저, Context 변경으로 인해 다른 인스턴스가 해결될 것으로 예상되었지만 다이어그램은 최종 수정 사항이 편집 형식 선택에 매우 민감하다는 점을 확인할 수 있습니다. 더불어 Context와 edit format의 다양한 조합은 서로 다른 인스턴스 해결에 다양한 강점을 나타내며 매우 효과적임을 시사하고 있습니다. 기존 접근 방식은 가장 효과적인 단일 선택을 식별하는 데 중점을 두고 Temperature sampling에 의존하여 다양한 솔루션을 생성하는 방식이 이루어졌습니다. 하지만 본 논문에서는 대조적으로 Temperature sampling 외에도 context와 edit format을 모두 변경할 것을 제안하고 있습니다. 해당 방식은 solution의 다양성을 높여 patch 생성에서 필요한 추론 호출 수를 줄이면서도 다양한 문제들에 대한 해결을 증가할 수 있습니다.
Context의 다양화는 LLM이 patch를 생성할 때 참조하는 코드 및 Issue와 관련된 정보입니다. Context의 다양화를 통해서 Issue에 대한 다양한 관점을 가질 수 있도록 합니다.
-
File: NV-EmbedCode라는 Code Embedding model을 통해 Issue 설명에 가장 관련성이 높다고 판단된 상위 1개 파일의 전체 내용을 의미합니다. 해당 방식은 가장 넓은 범위의 정보를 제공하지만 특정 문제에 대한 초점은 덜할 수 있습니다.
-
Localization Agent(LA) Entity: AST(Abstract Syntax Tree) 및 LSP(Language Server Protocol) 기반 도구를 사용하여 버그와 직접적으로 연관된 것으로 식별된 특정 함수, 클래스, 메서드와 같은 코드 엔티티들을 의미합니다. File 전체보다 훨씬 더 세분화되고 집중된 context를 제공할 수 있습니다.
-
Direct Prompting(DP) Entity: 지역화 에이전트의 첫 번째 반복에서 LLM에서 파일 내 entity 헤더(정의)만 제공하여 관련 entity를 직접 선택하게 하는 방식으로 Agentless와 유사하게 동작하여 얻은 entity를 의미합니다. LA가 여러 단계를 거쳐 얻는 결과라면 초기 추론에 기반한 관련 Entity들을 포함합니다.
-
LA+DP(LA 및 DP 엔티티 결합): LA 엔티티와 DP 엔티티를 모두 결합하여 제공하는 컨텍스트로 Localization의 넓이와 깊이를 모두 고려하여, 더 많은 관련 entity를 포괄할 수 있습니다.
Edit format의 다양화는 LLM이 생성해야 하는 patch의 출력 형태를 의미합니다. 해당 다양화를 통해서 솔루션의 다양성을 확보합니다.
-
Search/Replace format: 특정 코드 스니펫(원래 코드 블록)을 찾아 이를 새로운 코드 블록으로 대체(replace)하라는 지시와 함께 패치를 생성하는 형식입니다.
-
Edit File API (파일 편집 API) format: 특정 filepath(파일 경로), start_line(시작 줄 번호), end_line(끝 줄 번호), 그리고 content(삽입 또는 수정할 내용)를 명시하여 코드를 직접 편집하는 API 호출 형태로 패치를 생성하는 형식입니다.
5. Patch Selection
다양한 patch 집합을 생성한 후, 일련의 필터링 단계를 적용하여 가장 적합한 patch를 최종 solution으로 식별합니다. 이를 위해서 필터링 단게를 적용하고자 합니다.
먼저, 유효한 편집 지침을 생성하지 못하거나 구문 오류를 발생시키는 솔루션들을 제거합니다. 다음으로, 주석 , docstring 및 빈 줄을 제거하고 변수, 함수 및 클래스 이름을 표준화하여 편집된 코드를 정규화를 수행하게 됩니다. 이러한 정규화 과정을 통해서 반복되는 솔루션의 빈도를 기록합니다.
이후, regression tests와 생성된 reproduction tests를 사용하여 이러한 테스트에 통과하지 못한 솔루션들을 필터링하게 됩니다. 이러한 접근 방식은 Agentless에서 설명된 방법론을 밀접하게 따르고 있으며 artifacts2를 직접 활용합니다. 이 과정에서 Agnetless는 먼저 repository에 있는 모든 기존 테스트를 실행하여 원래 코드베이스에서 성공적으로 실행되는 complete 테스트의 하위 집합을 식별하게 됩니다. Complete test는 LLM에 의해 분석되어 Issue가 올바르게 수정되었는지 확인하는데 적합하지 않은 테스트들에 대해서 필터링을 수행하게 됩니다.
Regression Test의 경우, 먼저 repository 내 모든 기존 테스트를 실행하여 원본 코드에비스에서 성공적으로 통화하는 테스트들을 선별합니다. 해당 테스트들을 Agentless LLM이 분석하여 현재 해결하려는 이슈가 정확히 수정되었는지 검증하기에 적합하지 않는 테스트들을 제외하게 됩니다. 해당 과정을 통해서 남은 통과 테스트들이 Reproduction Tests로 지정됩니다. Regression Test의 목적은 새로운 패치가 기존 기능을 손상시키지 않는지를 확인하는 것입니다.
Reproduction Test의 경우, Agentless LLM을 활용하여 complete test 파일을 새로 생성합니다. 해당 test 파일은 두 가지 목적이 있습니다. 먼저, 원본 Issue를 재현할 수 있는지를 확인합니다. 이후, 패치가 적용된 다음에 Issue가 성공적으로 해결되었는지를 검증하게 됩니다. 이러한 Reproduction Test들은 original repository에 실행되어 원본 이슈를 탐지하는 데 실패하는 테스트들을 걸러냅니다. 즉, 아직 수정되지 않은 코드에서 버그를 찾지 못하는 테스트는 유효하지 않다고 판단하여 제외하는 과정을 수행하게 됩니다. 이러한 과정을 통과하면 유효하다고 판단된 모든 Reproduction Test들은 유지가 됩니다.
최종적으로 구문 오류 검사 및 코드 정규화와 더불어 Regression Test, Reproduction Test를 통과하지 못하는 솔루션(Patch)들은 필터링 됩니다. 만약 모든 필터링 과정을 거친 후 남은 솔루션이 전혀 없다면, 테스트 적용 이전에 유효했던 모든 솔루션들을 다시 포함시키게 됩니다. 이는 테스트 자체의 불완정성이나 너무 엄격한 필터링 기준으로 인해서 올바른 솔루션이 실수로 제외될 수 있는 상황에 대한 안전 장치입니다. 마지막으로 모든 테스트에 통과하여 남아있는 솔루션에 대해서는 다수결 Voting을 적용합니다. 이는 정규화된 버전의 솔루션들 중 가장 자주 반복되는 즉, 가장 많이 생성된 솔루션을 최종 patch로 선택하는 방식입니다.
이러한 동작 방식은 소프트웨어 엔지니어링에서 버그 수정 시 중요한 단계인 기존 기능의 유지와 문제 해결의 정확성을 각각 Regression Test와 Reproduction Test로 수행하여 LLM이 생성한 다양한 patch들 중에서 가장 신뢰할 수 있는 것을 선별하기 위해서 사용됩니다.
Experiments
1. Experiment Setup
임베딩 모델을 훈련하기 위해서 Low-Rank Adaptation이라는 PEFT 기술을 사용합니다. 특히, Contrastive Loss를 사용하여 Text Embedding model을 미세 조정하고 rank 16, alpha 32, dropout rate 0.1로 LoRA를 적용합니다. 200회의 warm-up steps와 1e-6의 learning rate, 비선형성을 추가하고자 optimizer로 Adam을 적용하였습니다. 훈련은 최대 시퀀스 길이 512개의 토큰으로 Bfloat16으로 사용하였으며 모델의 batch size는 64로 각 batch는 하나의 긍정적인 문서, 7개의 hard negative로 구성 되어 있으며 앞서 언급한 대로 in-batch negative는 사용하지 않았습니다. 비교하고자 한 모델들은 DeepSeek-v3, GPT4o, Llama-3.3 70B, Qwen2.5-72B-Instruct의 LLM으로 Localization agent를 인스턴스화 합니다. 최종 결과는 ensemble로 수행했습니다.
2. End-to-end Issue Resolution Results
SWE-bench Lite and Verified 각각 300개와 500개의 인스턴스를 통해서 검증하고자 문제 해결력에 대해서 분석하고자 하였습니다.
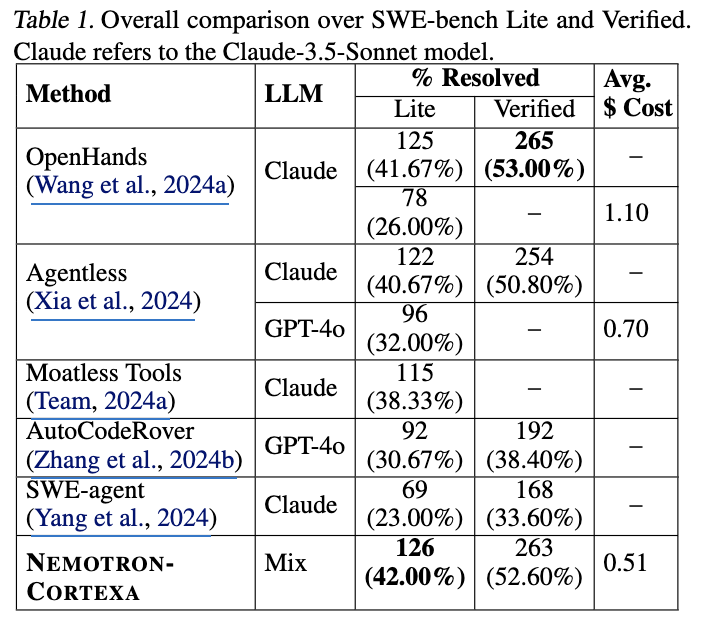
본 눈문에서 제안하고 있는 NEMOTRON-CORTEXA는 Lite에서 42% (126 / 300)의 가장 높은 해결률과 Verified에서 두 번째로 높은 비율인 52.60% (263 / 500)를 달성했습니다. 특히, NEMOTRON-CORTEXA는 문제당 평균 0.51의 비용으로 달성한 결과입니다. 즉, 테스트 시간 연산량을 추가로 확장하면 더 높은 해결률을 얻을 수 있으며 최소한의 비용으로 강력한 성능을 이끌었음을 확인할 수 있었습니다. 즉, 논문에서 제안하고 있는 Embedding model과 localization agent는 LLM에서 더 정확하고 효과적인 context를 제공하고 다양한 솔루션 생성 전략은 필요한 후보 생성 수를 크게 줄여 cost를 획기적으로 낮출 수 있었습니다.
3. Embedding Model Analysis
오라클 파일을 식별하기 위한 ground truth로 SWE-bench에서 제공하는 golden solution을 활용합니다. 코드베이스의 다른 부분을 편집하여 문제를 해결할 수도 있지만, 이 GT는 다양한 접근 방식을 비교하기 위한 신뢰할 숭 있는 기반을 제공합니다. 이 localization 작업을 위해서 lexical-based (즉, BM25), prompt-based, embedding-based 방법의 세 가지 접근 방식을 평가하였습니다. prompt-based rufrhksms Agentless의 로그에서 가져왔습니다. Embedding-based 접근 방식의 경우, 파일을 450개의 토큰으로 chunk하고 overlap은 없습니다. 이러한 선택은 기존 임베딩 모뎅을 사용한 실험에서 비롯되었으며, 여기서 450개에서 4096까지의 토큰 길이와 context window의 0 또는 절반의 overlap을 테스트 했으며, 모델은 더 작은 context window에서 더 나은 성능을 보이는 것을 확인했습니다. 이러한 결과는 두 가지 요인에서 비롯되었다고 볼 수 있습니다. 먼저, 이러한 모델은 종종 짧은 문서에 대해서 학습 되어져 있고 두 번째로는 더 작은 context window를 통해 모델은 전체 파일에서 vector embedding으로 정규화하는 대신 개별 코드 chunk에 더 집중하고 해당 의미에 집중할 수 있습니다. 각 chunk에는 추가 메타 데이터로 전체 파일 경로가 접두사로 붙습니다.
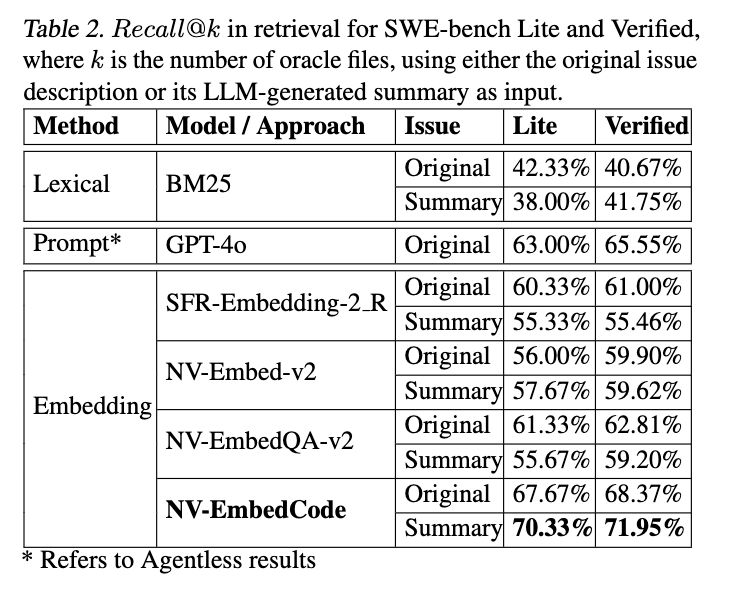
위 사진은 SWEbench Lite 및 Verified 세트에서 이러한 방법을 비교한 것입니다. 주어진 인스턴스에 대한 오라클 파일의 수를 k로 설정하여 올바르게 식별된 오라클 파일의 비율을 측정하고자 하였습니다. 결과는 기존 embedding model이 LLM description으로 잘 수행하는 데 어려움을 겪고 원래 설명을 선호한다는 것을 나타냅니다. 이는 이러한 요약의 언어 스타일과 어휘가 모델이 원해 학습된 자연어 쿼리와 다르기 때문일 수도 있습니다. 이러한 성능 저하는 정확한 용어 일치 및 키워드 빈도의 감소를 시사합니다. code embedding model을 개발함으로써 상단한 개선을 달성할 수 있었습니다. 원래 문제 설명으로 기존 embedding model보다 성능이 뛰어날 뿐만 아니라 LLM 생성 요약으로 훨씬 더 나은 결과를 얻었습니다. 이러한 요약은 중복성을 제거하고 관련없는 세부 정보를 제거하여 Issue description을 개선하여 검색 효과를 향상시킬 수 있습니다. NV-EmbedCode의 개선은 학습 세트에 다양한 코드 및 합성 데이터를 포함하고 모델이 다양한 언어 스타일을 인식하고 적응할 수 있도록 하는 instruction template을 사용했기 때문입니다. 그러나 이전의 Prompt-based 방법은 기존 임베딩 모델과 함께 사용될 때 임베딩 기반 방법보다 성능이 뛰어날 수 있지만, 본 논문에서 제안하고 있는 방식에 비해서는 성능이 부족함을 볼 수 있었습니다.
4. Entity Localization Analysis
정확한 Entity localization은 집중된 context를 제공하여 LLM이 올바른 패치를 생성할 가능성을 높입니다. NEMOTRON-CORTEXA는 Issue와 관련된 entity를 식별하기 위해서 Localization agent를 사용합니다. Agentic search 궤적의 끝에서 첫 번째 iteration과 마지막 iteration 응답을 결합하여 localization의 폭과 깉이의 균형을 맞추는 entity를 추출합니다. 첫 번째 iteration 결과를 Direct Prompting(DP)이라고 하고, 마지막 iteration 결과를 Localization Agent(LA)라고 합니다. 본 논문의 제안은 그들의 로그에서 추출한 결과를 사용하여 Entity localization 정확도를 Agentless와 비교하고자 합니다. SWE-bench의 golden solution을 사용하여 ground truth 엔터티 (오라클 엔터티)를 추출합니다.
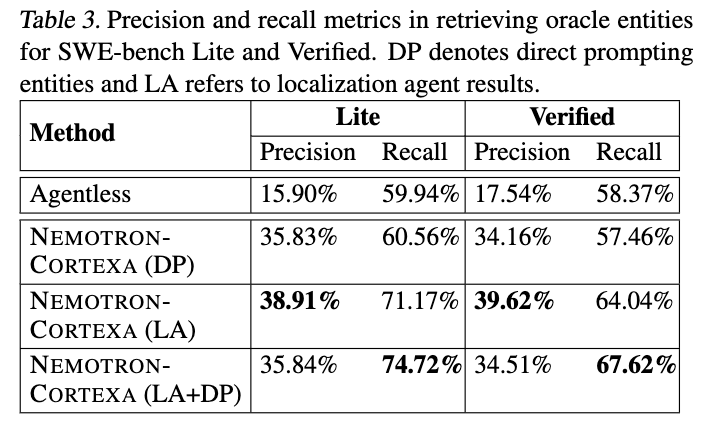
위 Table은 Agentless와 NEMOTRON-CORTEXA, 그리고 NEMOTRON-CORTEX의 첫번째 iteration 결과인 Direct prompting과 마지막 iteration 결과인 Localization Agent에 대한 평균 precision과 recall 결과를 보여줍니다. 전반적으로 NEMOTRON-CORTEXA는 SWE-bench Lite와 Verified 모두에서 Agentless보다 더 높은 precision과 recall을 달성했음을 확인할 수 있었습니다. NEMOTRON-CORTEXA의 localization 단계는 Agentless의 인스턴스당 0.15에 비해 인스턴스당0.11로 비용이 적게 듭니다. 향상된 Localization Agent 결과는 전문화된 도구와 다단계 추론을 결합하는 것의 이점을 보여줍니다. Direct Prompting 결과를 추가하면 에이전트의 후반부의 더 집중된 반복 과정에서 간과될 수 있는 Issue 관련 entity를 캡처하여 recall을 더욱 향상시킵니다. 또한 Direct propmting과 Localization Agent의 이중 접근 방식은 Repair Geneation 측면에서 다양한 고품질의 context를 제공하고 보다 더 효율적인 생성을 가능하게 해줍니다.
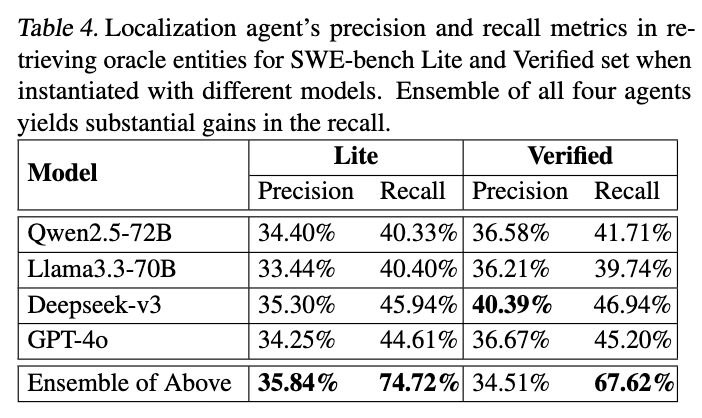
NEMOTRON-CORTEXA는 각각 다른 LLM으로 인스턴스화된 4개의 localization agent(DeepSeek-v3, GPT-4o, Llama-3.3 70B, Qwen2.5-72B-Instruct)의 앙상블을 사용합니다. 위의 테이블은 ensemble 결과를 개별 에이전트의 결과와 비교한 결과입니다. Lite 및 Verified 세트에서 각각 NEMOTRON-CORTEXA이 recall 및 Precision에서 더 높은 성능을 기록했으며 이는 훨씬 더 많은 관련 엔티티를 검색이 가능했음을 시사합니다. 또한 앙상블이 서로 다른 문제 하위 집합을 해결하는 모델의 강점에서 이점을 얻기 때문에 더 넓은 범위의 관련 entity를 찾아낸 것을 시사함과 동시에 Lite 세트의 precision 증가를 통해서 확인할 수 있었습니다. 이 결과는 여러 모델을 사용하여 Inference-time scaling을 위한 대안적인 축을 제시합니다. 여기서 말하는 추론은 이미 학습된 모델을 사용하여 새로운 데이터에 대한 예측이나 출력을 생성하는 과정으로 해당 Task에서는 Issue 파악 및 솔루션 생성을 의미합니다. Scaling의 경우, 모델의 성능이나 처리 능력을 확장하는 것을 말합니다. 즉, Inference-time scaling은 모델의 학습단계가 아닌 실제 활용에서 결과를 내는 추론 단게에서 성능을 향상 시키는 것을 의미합니다. 위에서 대안적인 축을 제시한단 것은 일반적으로 LLM의 성능을 스케일링 하는 방법은 단일 LLM의 크기(파라미터 수, context window 등)를 키우거나 아키텍처를 개선하는 것입니다. 하지만 본 논문에서 제안한 단일 모델을 개선하는 대신 여러 개의 다른 모델을 동시에 활용하여 각 모델의 강점을 결합한 Ensemble이 성능을 스케일링할 수 있음을 보여준단 의미가 되겠습니다.
5. Repair Generation
3.4절 Diverse Patch Generations에서 이야기한 듯 LLM 에이전트가 Patch를 생성할 때, Context와 Edit format을 다양하게 변경하는 것이 서로다른 문제 해결(resolved instances)로 이어질 수 있음에 대해서 이야기 했습니다. 여기서 한 가지 접근 방식은 Context와 Edit format의 가장 효과적인 조합을 식별한 다음 temperature sampling을 사용하여 여러 솔루션을 생성하는 것입니다. 예를 들어 Agentless는 4개의 edit location을 sampling하고 각각에 대해서 search/replcae 형식으로 10개의 patch를 생성하여 인스턴스 당 40개의 패치를 생성합니다. (greedy sampling을 사용하여 1개, temperature sampling을 사용하여 9개)이들은 해결된 인스턴스 수가 40개의 패치까지 증가하지만 그 이상에서는 정체된다고 이야기하고 있었습니다.
그러나 해당 논문에 따르면 Patch가 생성되는 방식의 다양성을 높임으로써 더 적은 수의 patch로 유사하거나 더 나은 성능을 달성할 수 있다고 이야기하고 있습니다.
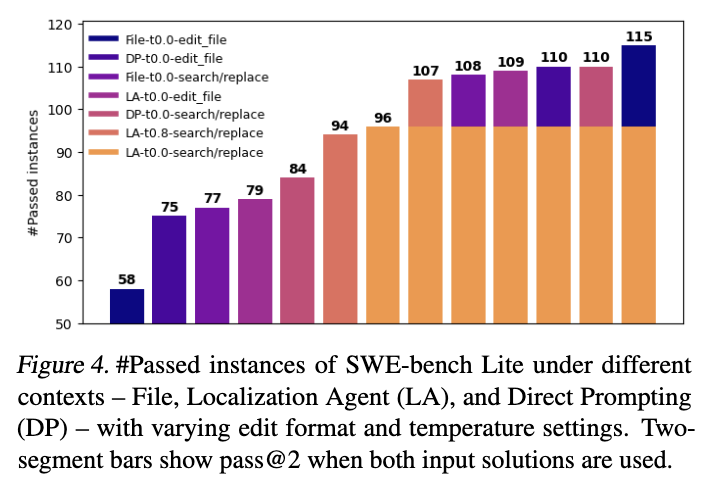
해당 figure를 보면 다양한 context와 edit format 및 temperature 설정에서 SWE-bench Lite에 대해 통과된 인스턴스 수를 보여줍니다. 여기서 세 가지의 context를 고려하게 됩니다. 첫 번째로는 NV-EmbedCode로 검색된 상위 1개 파일, 두 번째로는 Localizatio agent, 마지막으로는 Direct Prompting을 고려합니다.
Greedy sampling (temperature 0.0), LA 컨텍스트 및 search/replace 형식을 사용하면 이미 96개의 인스턴스의 높은 통과율을 달성할 수 있으며, 이는 localization 단계의 효과를 강조합니다. Temperature sampling을 통해 생성된 패치를 추가하면 올바르게 해결된 인스턴스 수가 107개로 증가합니다. 이러한 두 가지 전략이 개별적으로 가장 높은 통과율을 갖지만 다른 대안에 비해 이들의 조합은 많은 새로운 해결된 인스턴스를 도입하지 않습니다. 예를 들어 context를 file로 변경하고 prompt format을 edit file로 변경하면 전체적으로 115개의 해결된 인스턴스가 발생하며 이 새로운 조합들은 개별적으로 가장 낮은 통과율을 갖습니다. 이러한 패턴은 다른 context 및 edit format 조합에서도 이어지며 이는 다양하게 변경하면 솔루션 다양성이 증가하여 궁극적으로 더 높은 총 정답 솔루션 수를 얻는 동시에 필요한 추론 호출 수를 줄일 수 있음을 의미합니다.
Temperature sampling은 다른 요소를 변경하는 것보다 효과가 떨어지지만 새로운 패치를 생성하는 데 유용한 전략으로 남아 있습니다. 최종 patch 생성 과정에서는 4개의 context(File, LA, DP, LA + DP), 2개의 edit format(search/replace 및 edit file), 2개의 temperature 설정(greedy sampling의 경우 0.0, temperature sampling의 경우 0.8)을 고려합니다.
먼저 File 및 LA를 컨텍스트로 사용하고 두 편집 형식을 모두 사용하여 greedy sampling으로 4개의 솔루션을 생성합니다. 그런 다음 LA+DP를 컨텍스트로, edit file 프롬프트를 사용하여 greedy sampling으로 단일 추가 솔루션을 생성합니다. 마지막으로 temperature sampling을 통해 4개의 컨텍스트를 모두 포함하여 4개의 솔루션을 더 생성하며, 두 개는 search/replace 형식을 사용하고 두 개는 edit file 형식을 사용합니다. 이러한 9개의 솔루션은 각가의 세트에서 Agentless의 성능을 능가함을 확인할 수 있습니다. 즉, 해당 논문의 제안 방식은 9개의 솔루션으로 Lite 세트에서 126, Verified 세트에서 263의 해결력을 보여줬으며 Agentless의 경우 40개의 패치로 112개와 254개의 해결력을 기록하였기에 Agentless를 능가하여 솔루션의 다양화가 더 많은 수의 올바른 Patch로 이어질 수 있음을 보여줍니다.
6. Ablation on Localization
Localization에 대한 두 가지 측면에서의 기여에 대해서 보겠습니다. 먼저 첫 번째로는 미세 조정된 NEMOTRON-CORTEXA 임베딩 모델과 엔티티 지역화를 위한 지역화 에이전트에 대한 SWE-bench Verified에 대해서 확인하도록 하겠습니다.
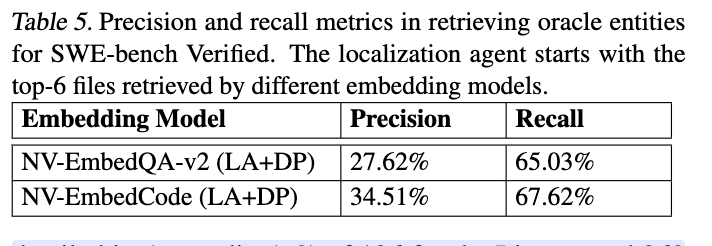
위 표를 보시게 되면 NV-EmbedCode가 더 높은 recall@k를 달성함을 확인할 수 있습니다. 이는 Localization agent가 더 정확한 entity localization 결과를 생성함을 시사합니다. 이러한 개선은 더 정확하고 관련성 높은 파일로 시작하면 Oracle Entity를 식별하는 데 에이전트의 성능이 향상됨을 보여줍니다.
두 번째로는 entity localization이 최종 solution에 미치는 영향에 대한 연구로 Patch 생성을 위한 Context로 Entity 결과(LA + DP)와 상위 1개 검색된 File을 사용한 것을 비교하고자 합니다. Edit format과 temperature sampling을 모두 사용하여 9개의 패치를 생성하고 섹션 3.5에 설명된 필터링 단계를 적용합니다.


Pass@1은 생성된 여러 후보 패치 중에서 필터링 과정을 거쳐 최종적으로 하나만 선택된 패치가 문제를 해결했는지에 대한 여부를 나타내고 있습니다. 즉, 시스템이 최종적으로 제시한 단일 솔루션의 성공률을 의미합니다. 여기서 수행한 필터링은 앞서 언급했던 필터일 과정으로 유효성 검사, 구문 오류 검사, 코드 정규화, 회귀 테스트, 재현 테스트를 적용하고 마지막으로 다수결 투표를 통해서 하나의 패치를 최종 솔루션으로 선택한 것을 의미합니다. Pass@9는 생성된 9개의 패치 후보 중 적어도 하나라도 문제를 성공적으로 해결했는지에 대한 여부를 나타냅니다. 이는 모델의 다양한 시도를 통해서 문제를 해결할 수 있는지에 대한 성능을 평가하고자 하였습니다.
해당 결과를 보면 entity localization 결과를 context로 사용하면 Issue 해결력이 크게 향상되어 Entity의 localization에 대한 중요성을 확인할 수 있었습니다.
7. Ablation on Solution Diversity
- Repair Generation 섹션에서 단순히 temperature sampling만을 사용하는 것보다 솔루션 생성 전략을 다양화하는 것(context, edit format의 다양한 조합)이 문제 해결률을 높일 수 있음에 대해서 입증하였습니다. 이에 대해서 더 자세히 알아보도록 하겠습니다. 기존의 Agentless 방식처럼 단일 최적 조합을 찾고 temperature sampling으로 여러 패치를 생성하는 대신, NEMOTRON-CORTEXA는 9가지의 '다양화된 패치' 생성 전략을 사용합니다. 먼저, LA(Localization Agent) 엔티티를 컨텍스트로 사용하고 'search/replace' 편집 형식만을 사용하며 온도 샘플링으로 패치를 생성하는 경우, 두 번째로는 LA 엔티티를 컨텍스트로 사용하고 '두 가지 편집 형식' (search/replace 및 edit file API)을 모두 사용하며 온도 샘플링으로 패치를 생성하는 경우, 마지막으로 위의 '두 가지 편집 형식 + 온도 샘플링' 방식을 File, LA, DP(Direct Prompting), LA+DP의 '네 가지 컨텍스트 유형' 모두에 적용하는 경우에 대해서 실험을 진행했습니다.
Context와 Edit format이라는 두 가지 요소를 모두 다양화하는 것이 더 많은 올바른 패치를 생성하는 데 기여하며, 각 구성이 고유한 강점과 약점을 가지고 있어 서로 보완적인 역할을 함을 명확히 보여주고 있습니다.
Conclusion & Feature Work
본 논문에서 제안한 NEMOTRON-CORTEXA는 Issue Localization & Repair Generation을 통해서 LLM이 소프트웨어 엔지니어링 분야에서 성능을 향상하는데 기여했습니다. 특히 최첨단 파일 검색에 대해서 정확도에 크게 기여하였으며 이전보다 Localization 부분에서 크게 성능 향상을 수행했습니다. 더불어 솔루션을 생성하는 과정에서도 다양한 솔루션 생성이 가능했으며 더 낮은 비용으로 성능 향상을 기록하였습니다.
향후에는 문제 해결을 위한 패치들 가운데 선택하는 과정에서 현재는 voting 방식을 활용하는데 이는 하나의 정확한 솔루션이 여러 잘못된 솔루션에 의해서 묻힐 수 있기 때문에 해당 프로세스의 비효율성에 대해서 언급하며 이를 개선해야 한다고 이야기 하고 있습니다. 더불어 패치 생성 단계에서 Reasoning model을 함께 활용하여 보다 더 복잡하고 정확한 수정을 생성해낼 수 있도록 할 수 있습니다.
이렇게 Nemotron-CORTEXA: Enhancing LLM Agents for Software Engineering Tasks via Improved Localization and Solution Diversity에 대한 리뷰를 수행했습니다. 부정확한 부분들도 있고 많이 부족한 내용들도 있을텐데 많은 이야기 남겨 주세요!!
