이번에 리뷰할 논문은 'AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE'입니다. 해당 논문은 너무나도 유명한 ViT에 대한 논문으로 기존의 Transformer가 NLP 분야에서 엄청 큰 기여를 한 것을 Vision에서도 수행하고자 한 논문입니다. 해당 논문 이전에 Transformer를 Vision 분야에서 활용하고자 다양한 노력들이 이루어졌습니다. CNN을 Transformer와 함께 활용하는 등의 다양한 연구들이 이루어졌으나 해당 논문의 ViT 제안으로 인해서 vision 분야에서도 큰 기여를 하게 된 계기가 되었습니다.
이제 본격적으로 본 논문에 대해서 리뷰해보겠습니다. 추가적으로 유튜브 '거꾸로 읽는 SSL' 님의 ViT Review 영상에서 나온 내용들과 함께 해보도록 하겠습니다.
Abstract

Transformer가 NLP 분야에서 큰 기여를 하였으나 아직 Vision 분야에서의 활용은 여전히 제한적인 상황입니다. 앞서서 이야기 했듯이 본 논문 이전에 Attention을 CNN과 함께 적용하거나 CNN 계열의 모델에서 Conv 연산을 attention으로 변경하는 등의 다양한 접근들이 이어졌으나 Convolution에 대한 의존선은 여전히 높았습니다. 이러한 제한점들을 해결하고자 본 논문에서는 이미지를 작은 단위의 Patch로 나눠 Vision 분야에 Transformer를 도입하게 되었습니다. 해당 결과는 저희가 이미 너무나도 잘 알고 있듯이 Vision에서도 놀라운 기여를 기록했습니다.
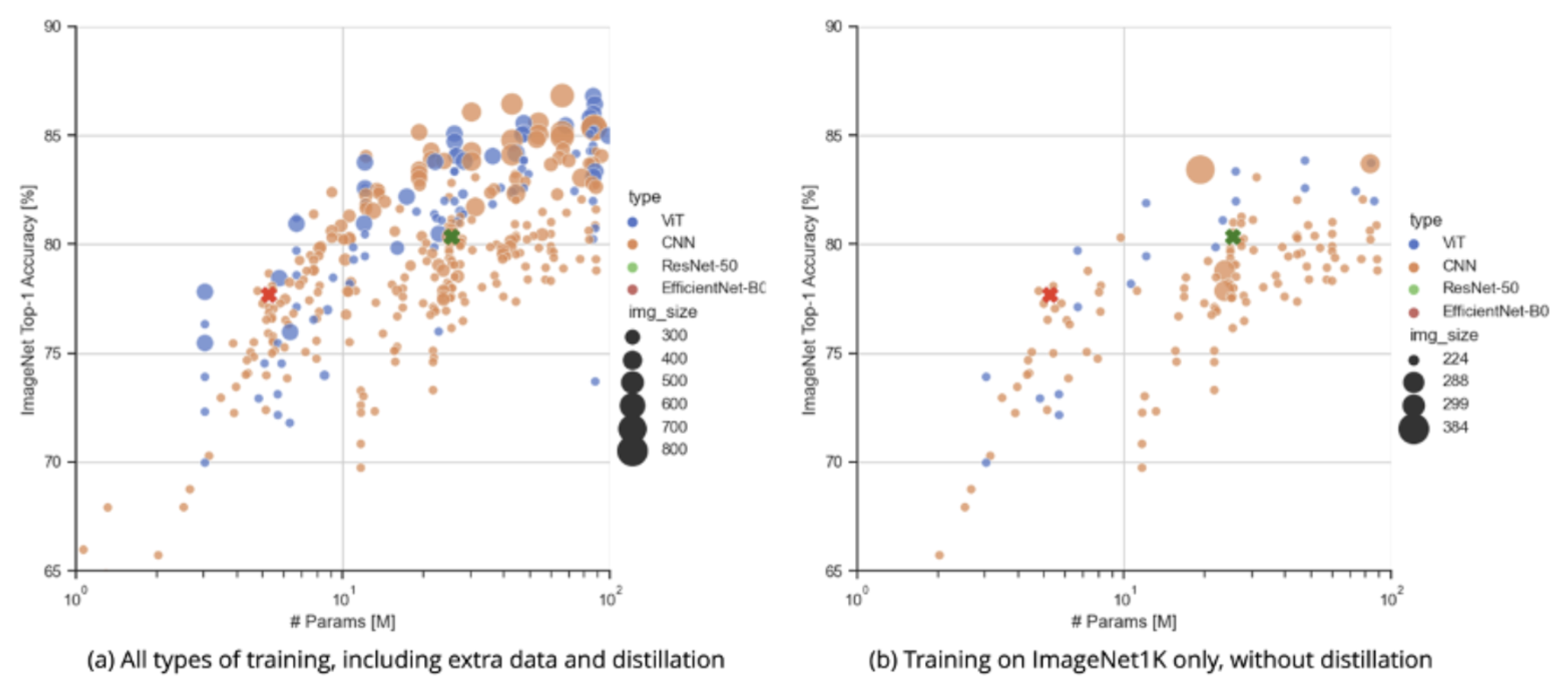
위 사진에서 주황색은 CNN을 의미하고 있으며 파란색은 ViT를 의미하고 있습니다. 즉, ViT의 등장으로 인해서 기존까지의 Vision 분야에서 CNN으로 시도한 수많은 연구들과 동등한 혹은 그것보다 더 높은 성능들을 기록하고 있음을 확인할 수 있습니다.
Introduction
Transformer가 NLP에서 큰 기여를 했었으며 Transformer는 계산 효율성과 확장성 덕분에 모델의 사이즈 또한 이전에는 없었던 수준의 크기 달성과 이로 인해서 더 많은 대규모 데이터셋에서 과잉적합 없이 준수한 성능을 보여주고 있습니다. 그러나 Vision 분야에서는 아직까지는 Convolution이 여전히 지배적인 접근 방식이었습니다. NLP 분야에서의 성공에 큰 영감을 받아 이를 Vision 분야에서도 활용하고자 하였습니다. 그러나 ViT 이전의 접근 방식에서는 당시의 HW 기술이 따라와주지 못해 연구에 한계점들이 존재하였습니다.
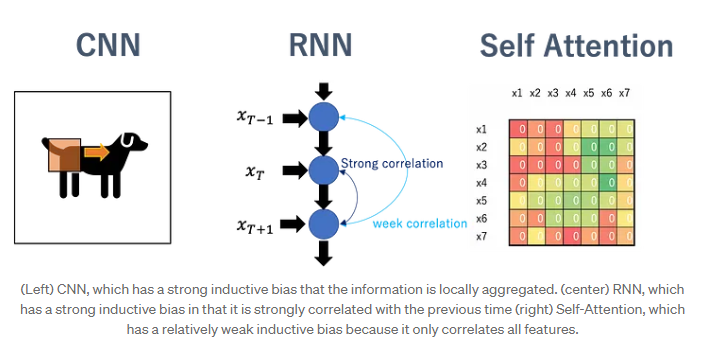
Introduction 의 마지막 문단에서 Inductive bias에 대해서 이야기하고 있습니다. Inductive bias는 쉽게 말해서 '가설(Hypothesis)'이라고 이해할 수 있습니다. 즉, 이러한 가설을 통해서 문제 해결에 접근을 하고 설계를 해왔던 점들에 대해서 이야기하고 있습니다. 흔히 CNN에서의 Inductive bias의 경우, '어느 한 픽셀에 대한 정보는 주변 픽셀과 유사할 것 혹은 가장 멀리 떨어진 픽셀의 경우엔 완전히 다른 정보를 가지고 있을 것' 이와 같은 가설을 세우고 접근하여 모델에 대한 설계를 수행했습니다. NLP 분야에서의 RNN Inductive bias는 'Sequence 정보의 흐름이 왼쪽에서 오른쪽으로 흐를 것이다.'란 가설을 세우고 수행했습니다. 하지만 ViT에서는 이러한 Inductive bias가 훨씬 약합니다. 그렇기 때문에 CNN 혹은 RNN 계열의 모델들 보다 feature에 대한 관계를 스스로 학습하도록 설계가 강하게 되어있음을 의미하며 이는 곧 모델 성능의 유연성과 확장성을 높일 수 있지만 이에 따른 대규모 데이터셋이 필수적임을 이야기하고 있습니다. 더불어 ViT에서의 핵심 주장 중 하나는 '대규모 데이터가 Inductive bias를 압도한다.'라고 할 수 있을 정도로 해당 관점은 본 논문에서 상당히 중요한 정보입니다.
Related Work
1. NLP에서의 Transformer 성공
Transformer는 NLP 분야에서 사실상의 표준 모델이 되었습니다. Transformer의 경우 대규모 텍스트 Task에서 사전학습 된 다음 이를 특정 Task에 맞는 fine-tuning을 수행하며 활용되어지고 있습니다. 특히, BERT 계열 모델은 denoising self-supervised pre-training을 사용하며 GPT 계열 모델은 언어 모델링을 사전 학습 작얼으로 활용했습니다.
2. Vision 분야에서의 Transformer 연구
이미지에 self-attention을 직접 적용하는 것은 각 픽셀이 다른 모든 픽셀에 attention을 적용해야 하므로 픽셀 수에 대해서 연산량과 이에 따른 비용이 급증하는 문제들이 존재하여 input size에 대해서 한계가 존재했습니다. 이를 해결하고자 다양한 연구들이 이어졌습니다.
-
로컬 어텐션(Local Attention): Image Transformer와 같이 각 쿼리 픽셀의 로컬(local) 영역 내에서만 self-attention을 적용한 연구가 수행되어졌습니다.
-
Convolution 대체: 로컬 멀티헤드 self-attention 블록으로 합성곱 계층을 완전히 대체하는 시도도 있었습니다(Stand-Alone Self-Attention in Vision Models 등).
-
Sparse Attention: Sparse Transformers는 글로벌 self-attention의 확장 가능한 근사치를 사용하여 이미지에 적용하는 노력도 있었습니다..
-
Axial Attention: Axial Attention in Multidimensional Transformers와 같이 다양한 크기의 블록이나 개별 축(individual axes)을 따라서 어텐션을 적용하는 방법도 있었습니다.
이외에도 hybrid modeling 접근도 이루어졌습니다. 즉, CNN과 self-attention을 함께 활용하는 연구들이 이어졌으며 이는 CNN의 출력에 self-attention을 적용하는 연구들이 이어졌습니다.
그러나 위의 다양한 연구들에도 불구하고 당시에는 HW 기술력의 부족으로 인해서 효율적으로 구현하기 어려운 한계점들이 존재 하였습니다.
Method
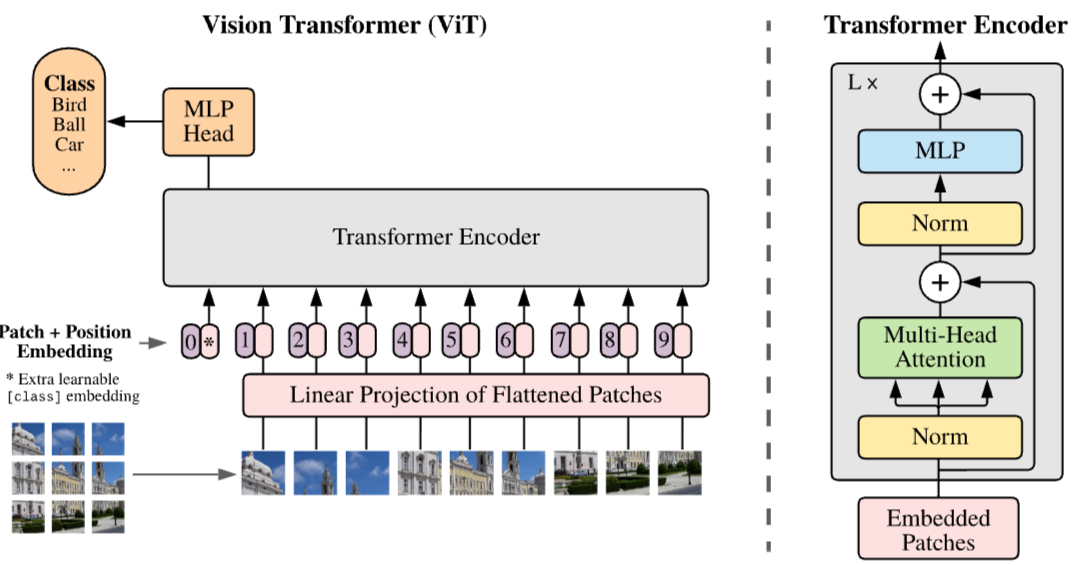
해당 ViT는 이전에 먼저 제안되어진 Transformer의 기본 동작 방식을 그대로 최대한 동일하게 동작하게 설계하였습니다. 이러한 접근이 NLP 분야에서 큰 기여를 한 것처럼 Vision 분야에서도 또한 바로 적용하여 사용이 가능할 수 있다고 이야기하고 있습니다.
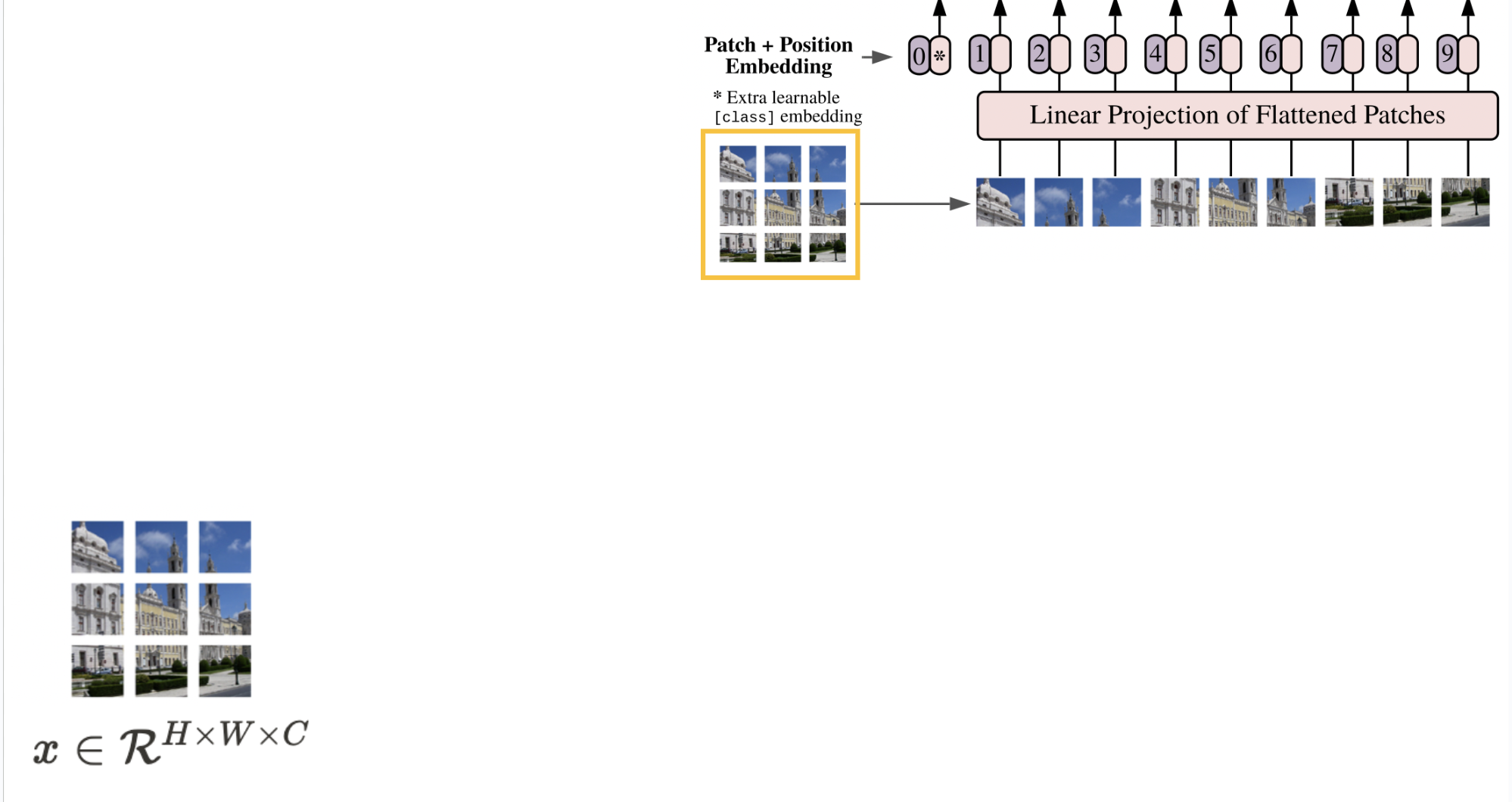
먼저 이미지를 입력받게 됩니다. 이러한 이미지를 그대로 사용하는 것이 아닌 이것보다 작은 Patch 단위로 쪼개서 활용을 하게 됩니다. 이때, 본 논문에서는 16x16 사이즈가 제일 성능이 좋았음을 이야기하고 있으며 rough하게 하는 경우 오히려 성능 하락의 요인이 될 수 있으며 너무 local하게 설정하는 경우 그만큼의 컴퓨터 연산량 증가로 인한 비용 증가 문제가 따라온다고 이야기하고 있습니다. 그래서인지 후속 연구들에서 대부분 16x16 연산을 수행하고 있습니다.
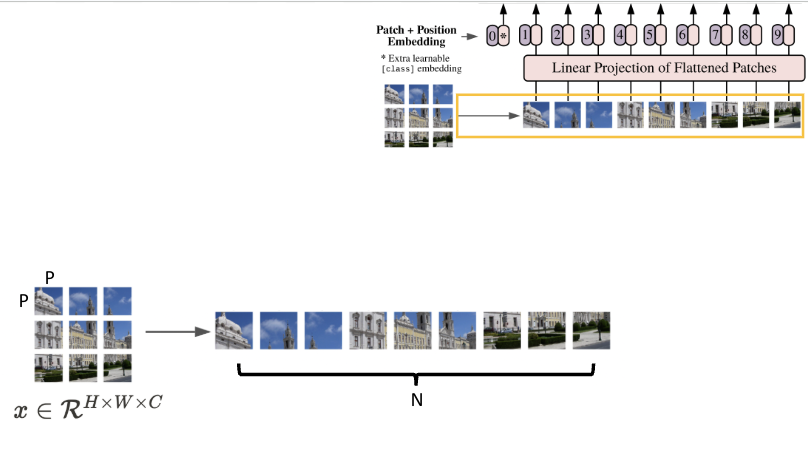
위 사진 처럼 Patch size를 기준으로 N개의 patch를 생성하게 됩니다. 이때, 본 논문에서는 이미지의 채널 값을 RGB이기 때문에 3차원 채널로 수행을 하게 되는데 Patch 생성 이후, 이를 1차원으로 Flatten을 수행하게 됩니다. 해당 step의 결과는 아래 사진과 같습니다.
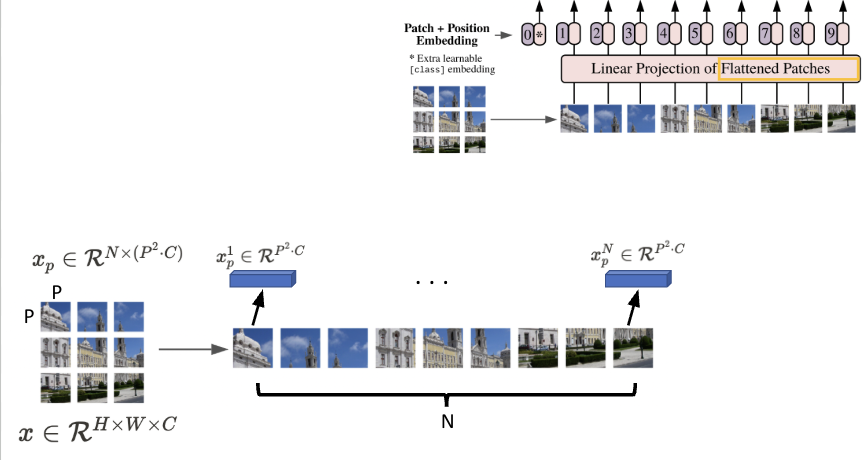
그 다음으로는 Flatten한 Patch에 대해서 Linear projection을 수행하게 됩니다. Linear projection한 결과가 아래 사진에서 핑크색 부분에 해당하게 됩니다.
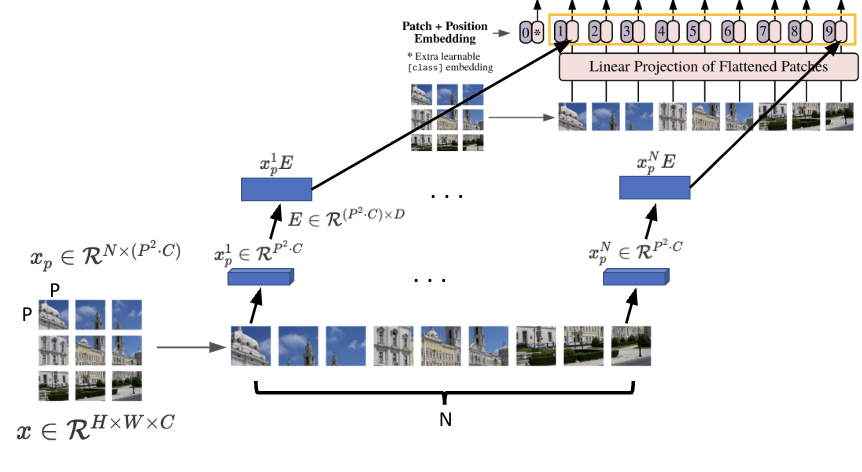
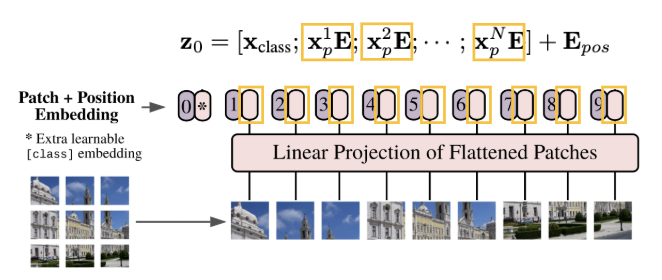
이때, 위의 사진을 자세히 보시면 여태까지 수행한 Linear projection 한 결과 앞에 token이 하나 더 존재하고 있음을 볼 수 있습니다. 해당 토큰은 수행하고자 하는 Task가 Classification이기 때문에 이에 해당하는 class 정보가 붙어 있는 class token이 되겠습니다. 그리고 이들 각각의 토큰에 대하여 Positional Embedding을 수행하게 됩니다.
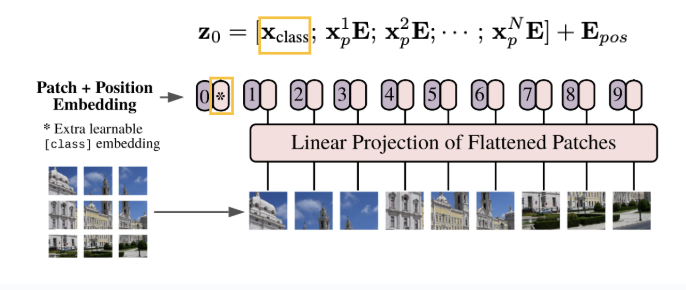
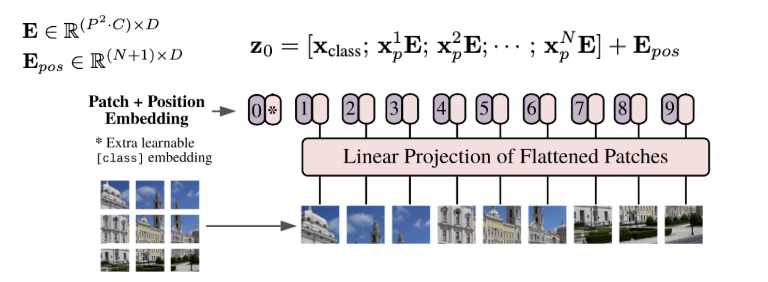
위의 과정을 수행해서 현재 아래 사진의 Embedded Patches까지 생성했습니다.

이제 순차적으로 Layer Normalization을 수행하고 이후 Multi-Head Attention을 수행하게 됩니다.

이때, 앞서서 이야기했듯이 Transformer의 동작 방식과 유사하게 동작하는 것을 목표로 설계했음을 확인할 수 있습니다. 그렇기 때문에 여기서 이야기하는 Multi-Head Attention은 저희가 아는 Transformer의 메커니즘과 동일하게 수행되어집니다.
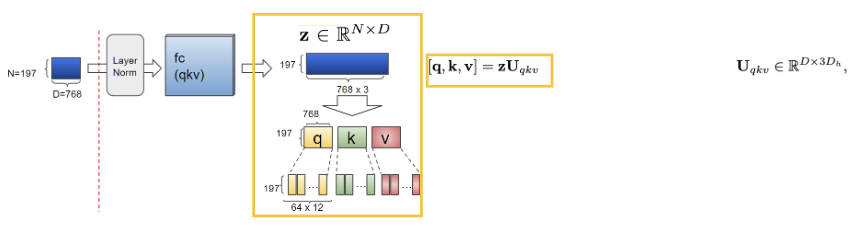
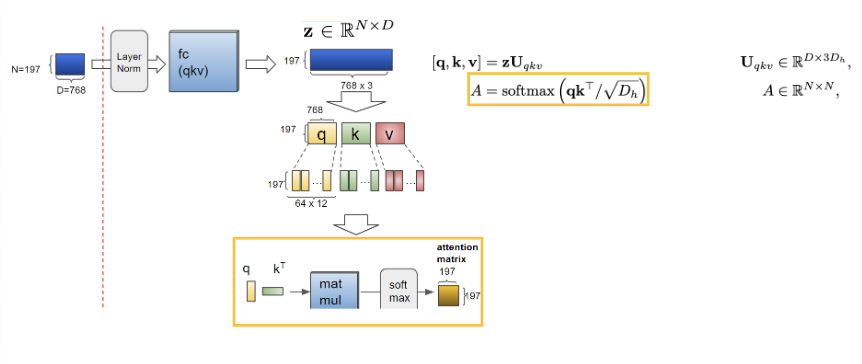
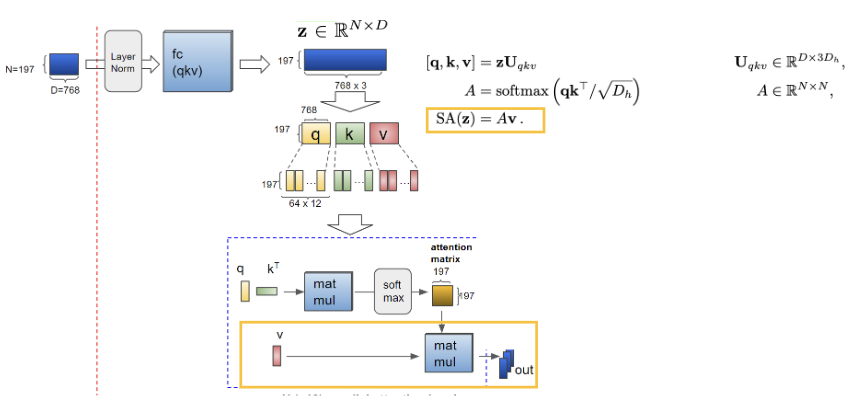
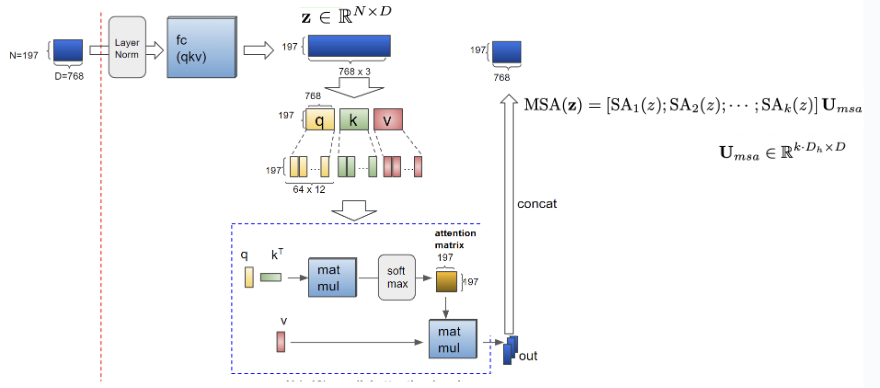
위 사진들은 각 순서대로 attention 연산 과정을 step 별로 보여준 것으로 query와 key를 통해서 Attention score를 구하게 되고 이를 Value와 함께 곱하는 과정을 수행하게 됩니다. 이후엔 처음의 attention 연산 이전의 차원수를 맞춰주기 위한 작업이 이루어지게 됩니다.
그 다음 스텝으로는 Layer Norm과 MLP(2-layer)를 수행하게 됩니다. 여기서 MLP는 GELU를 갖는 비선형성 레이어 두 개를 의미하고 있습니다.

이렇게 총 L번을 위에서 말한 스텝을 반복해서 동작하게 됩니다. 더불어 사진을 자세히 보시면 skip connection이 있음을 꼭 유의해주시길 바랍니다!!
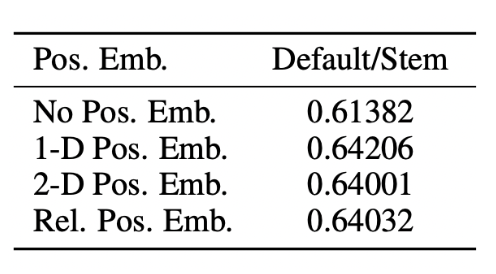
이때, Positional Emedding을 raster order 방식으로 1차원으로 부여하고 있습니다. 하지만 2차원으로 주는 방식들도 존재할 것이며 patch와의 거리에 따른 상대적으로 부여할 수도 있습니다. 하지만 본 논문에서 실험을 수행하였을 때, Positional Embedding을 적용하징 않았을 때보다 적용했을 때가 성능이 더 좋았으며 1차원으로 raster order로 부여하는 것이 제일 준수한 성능을 보여줬음을 확인하였습니다.
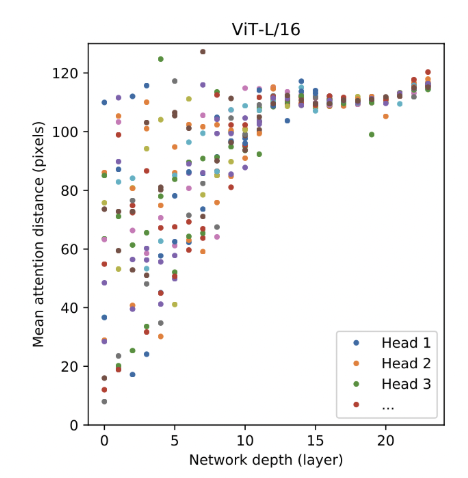
특히, ViT는 모델의 layer가 깊어짐에 따라 local한 정보와 global 정보에 따른 학습 능력이 상대적으로 얕은 layer에서도 이 둘의 정보가 잘 수용되는 것을 볼 수 있습니다. 이는 CNN에서 레이어가 깊어질 수록 글로벌 정보를 학습하는 것과 다른 점을 보여줍니다.
더불어, 모델 사이즈가 커질 수록 패치 사이즈를 조금 크게 주어도 성능을 동일하게 혹은 더 향상 시킬 수 있음에 대해서도 이야기 하고 있습니다.
Experiments
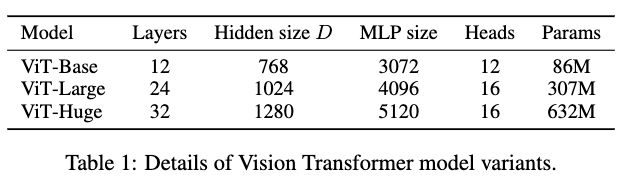
모델의 크기에 따라서 위와 같이 ViT 볼 수 있습니다. 특히 실험 환경에서 집중해야 할 점으로는 Adam을 활용하였으며 배치사이즈가 4096으로 엄청 큰 것을 확인할 수 있습니다. 특히, Vision 분야에서 당시 Adam이 ResNet에 대해서 SGD보다 더 다은 성능을 보여주었기에 Adam을 활용했다고 이야기하고 있습니다.
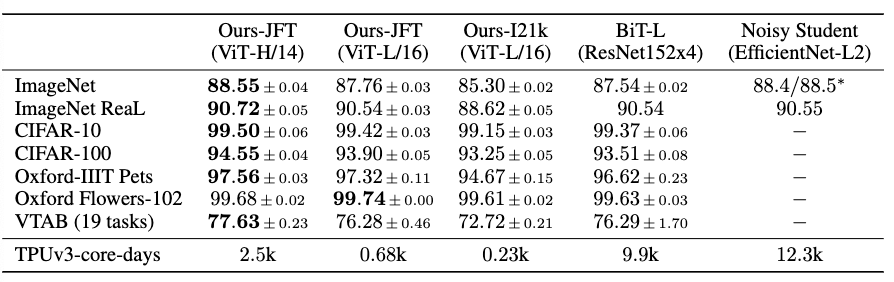
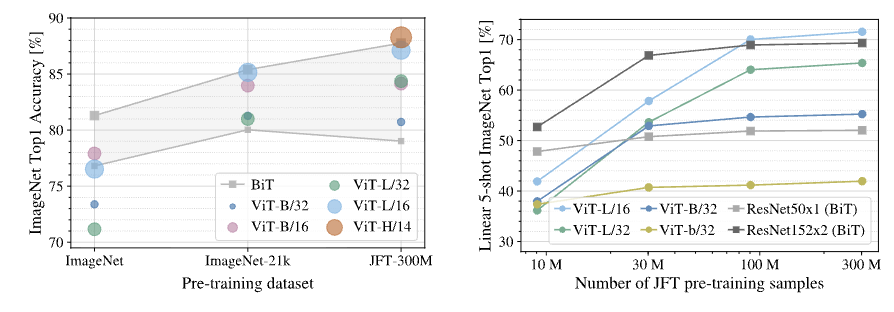
대규모 데이터셋에서 ViT 성능이 이전에 CNN 계열의 연구들보다 더 나은 성능을 보였음을 확인할 수 있습니다. 하지만 이는 데이터셋의 크기에 따라서 모델의 적절한 사이즈를 고르는 것이 가장 중요함을 이야기해주고 있습니다.
Conclusion
ViT는 Vision 분야에서 상당히 성공적인 기여를 하였습니다. 특히, 기존의 CNN 계열보다 더 좋은 성능 결과를 보이기도 하고 Inductive bias가 작기 때문에 스스로 관계성에 대해서 많은 학습을 해야 하기에 대규모 데이터셋이 갖춰지기만 한다면 유연성과 일반성에 서 큰 장점을 이끌어낼 수 있습니다. 특히 모델의 추가 스케일링을 통해서 성능 향상이 이어지기 때문에 추후 연구로 성능 개선을 위한 스케일링 연구와 단순히 classification task에서 벗어나 detection과 segmentation으로 확장이 추가적으로 이어져야 할 것을 이야기 하고 있습니다.
이렇게 ViT 논문에 대해서 다뤄보았습니다. 대규모 데이터셋 환경만 갖춰지기만 한다면 꼭 ViT를 한 번 활용해보고 싶네요.ㅎㅎ
