가상환경 만들기
<Tensorflow 로컬 설치>
순서대로 !
- 아나콘다 설치
- 통합환경에서 개발하기 위해 파이참 이용!
https://learn.microsoft.com/en-US/cpp/windows/latest-supported-vc-redist?view=msvc-170
--> Visual Studio 2015, 2017, 2019, and 2022에서 세번째꺼 설치 - 자바 설치
- 윈도우에서 anaconda powershell을 오른쪽 클릭 -> 관리자 권한으로 실행
-
conda list 보고 어떤 라이브러리가 설치되어 있나..
-
conda create –n chatbot python=3.7 설치
-
conda activate chatbot
-
아래의 사진의 빨간 밑줄 부분이 설치되어 있는 지 확인!
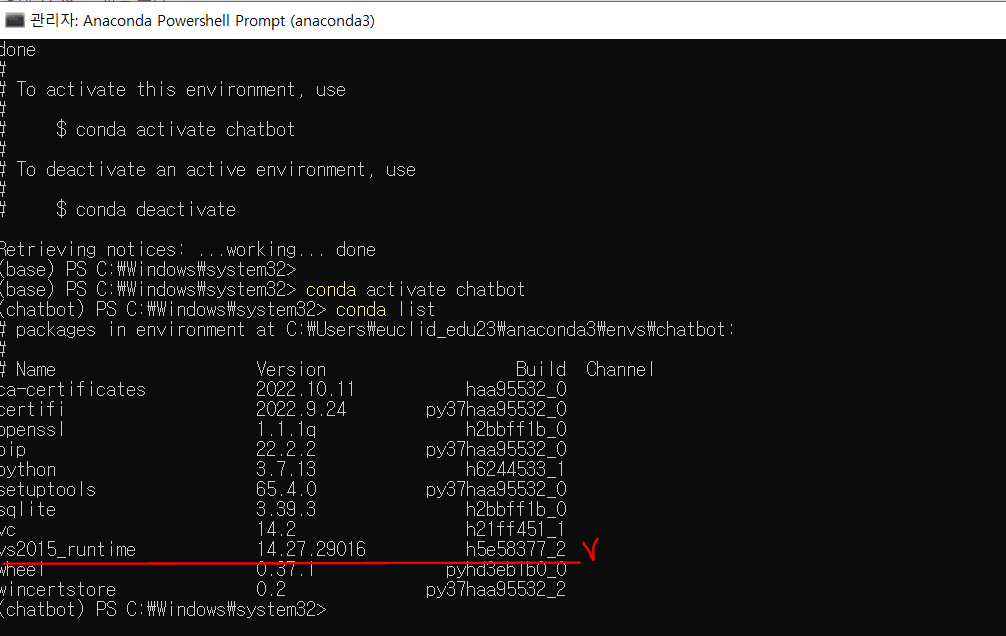
- 가상환경에서 python 을 쳤을 때 실행이 되는 지 확인(exit해주고)
- Tensorflow설치 pip install --ungrade tensorflow-cpu
- 가상환경 activate된 상황에서 라이브러리 설치 시작!
pip install konlpy
pip install PyKomoran
pip install gensim
pip install sklearn
pip install seqeval
pip install PyMySQL
pip install openpyxl
pip install xlrd
pip install matplotlib
pip install flask
pip install requests
- 파이참에서 새로운 프로젝트 생성
자연어 처리
-
기계에게 인간의 언어를 이해시킨다.
-
KoNLPy 서울대에서 만든 한국어 자연어 처리할 때 도움이되는 라이브러리 ** 꼬꼬마 형태소 분석기,코모란 형태소 분석기 ( 철저하게 언어학적으로 분석)
-
토큰(Token): 문법적으로 더 이상 나눌 수 없는 언어요소
-> 토큰화(Tokenizer)
토크나이징Tokenizing
--> 전처리~
-
단어는 표기는 같지만 품사에 따라서 단어의 의미가 달라진다.
-
단어의 의미를 제대로 파악하려면 그 단어의 '품사'가 무엇인지 봐야한다! (9품사 잘 알아야 하겠죠?)
-
Okt : 트위터 코모란 형태소 분석기
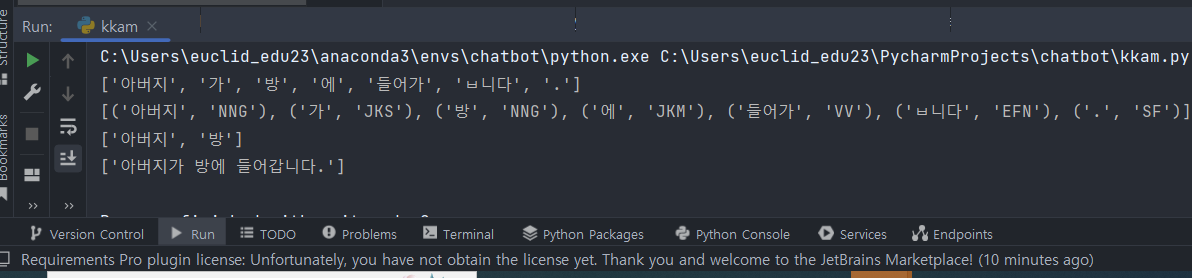
1. 꼬꼬마 분석기
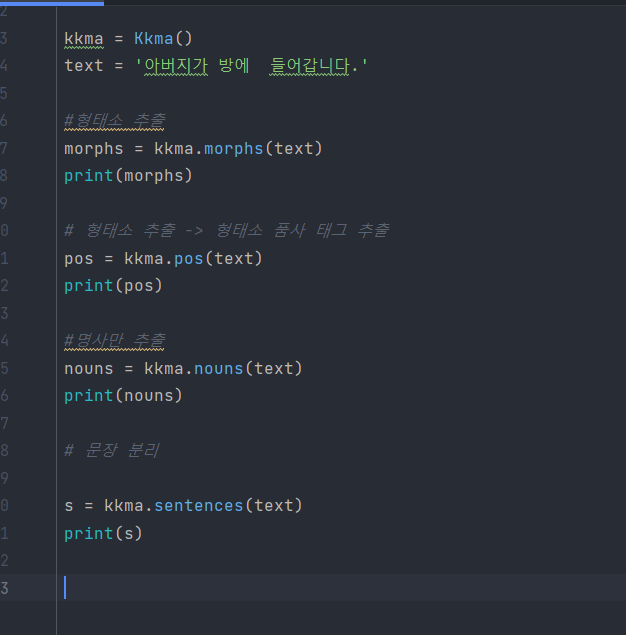
형태소 분석 결과
태그 참고
http://kkma.snu.ac.kr/documents/?doc=postag
2. Okt (트위터 기반)
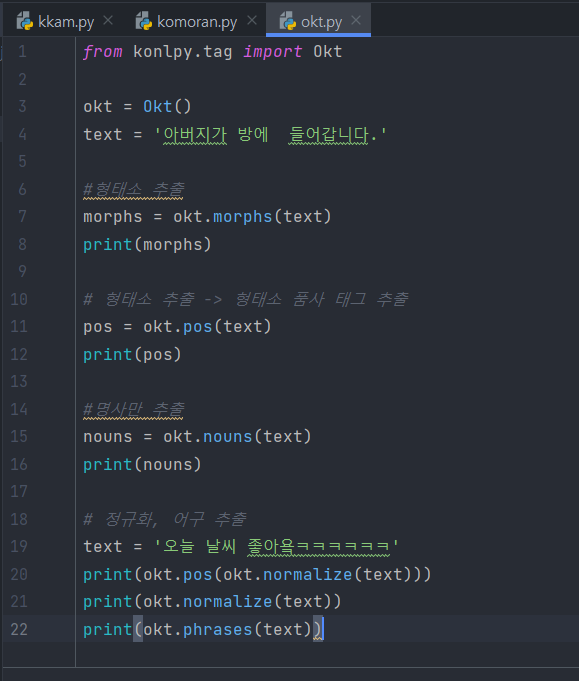
결과 : 정확도는 떨어짐

3. 형태소 분석 안되는 경우 따로 지정해서 분석하기
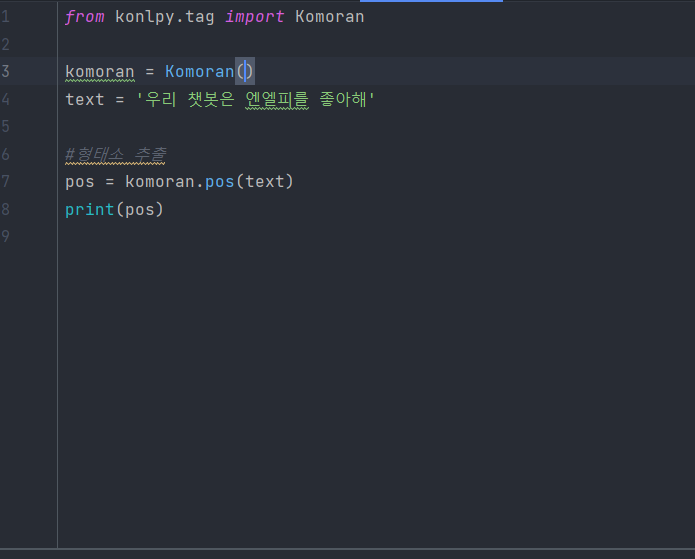
엔엘피는 명사인데 인식을 못함!

그래서 따로 지정해서 파일을 만들고
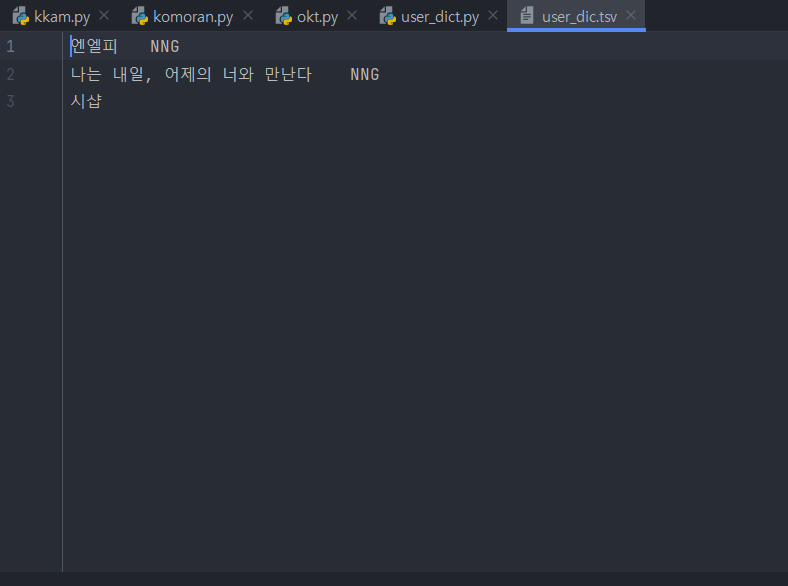
다음과 같이 엔엘피를 명사로 분류할 수 있도록 파일을 넣어주면
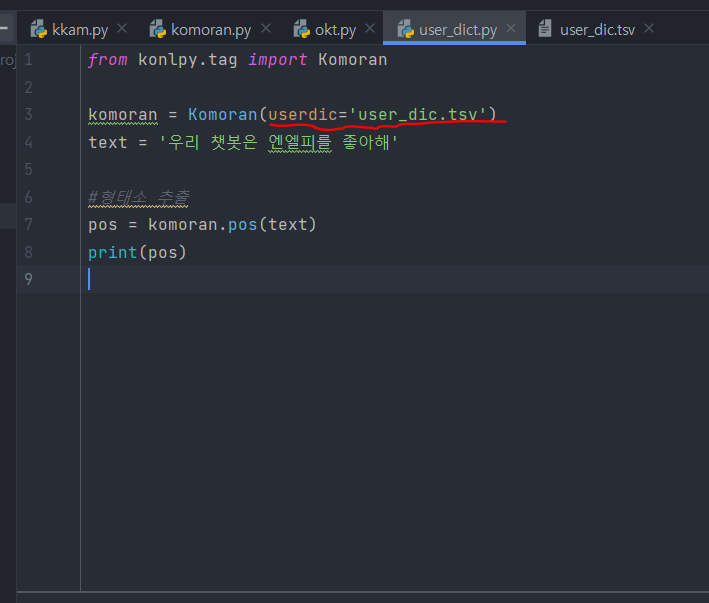
다음과 같이 명사로 인식해서 결과가 나온다. 
임베딩(embedding)
-
텍스트 -> 모델에 적용하기 위해 언어적 특성을 반영하여 단어를 수치화하는 방법을 찾는 것
-
컴퓨터는 텍스트보다는 숫자를 잘 처리할 수 있다.
-
원핫 인코딩은 1,0으로 인코딩되어서 1500개의 단어의 데이터를 넣으면 벡터의 크기가 너무 크고, 단어의 의미나 특성을 전혀 표현할 수 없다..
--> 연속 표현(Continuous Representation) 으로 대체
- 예측방법
신경망 구조 혹은 어떠한 모델을 사용해 특정 문맥에서 어떤 단어가 나올지를 예측하면서 단어를 벡터로 만드는 방식
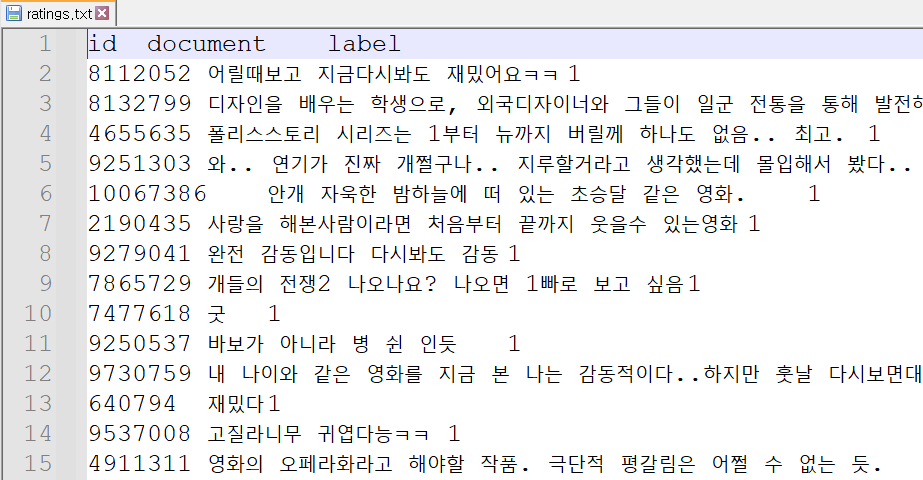
네이버 영화리뷰 데이터로 자연어 처리 , 파일은 다음과 같이 구성되어 있다.
예측 방법 종류 : Word2Vec -1
-
CBOW : 문맥 안의 주변 단어들을 통해 어떤 단어가 올지 예측하는 방법 → 맥락으로부터 타깃을 예측
-
Skip-Gram : 어떤 단어를 가지고 특정 문맥 안의 주변 단어들을 예측하는 방법
from gensim.models import Word2Vec from konlpy.tag import Komoran import time
네이버 영화 리뷰 데이터 읽어오는 사용자 정의 함수
with open(filename, encoding='UTF-8') as f: data = [line.split('\t') for line in f.read().splitlines()] data = data[1:] #header제거 return data
측정 시작
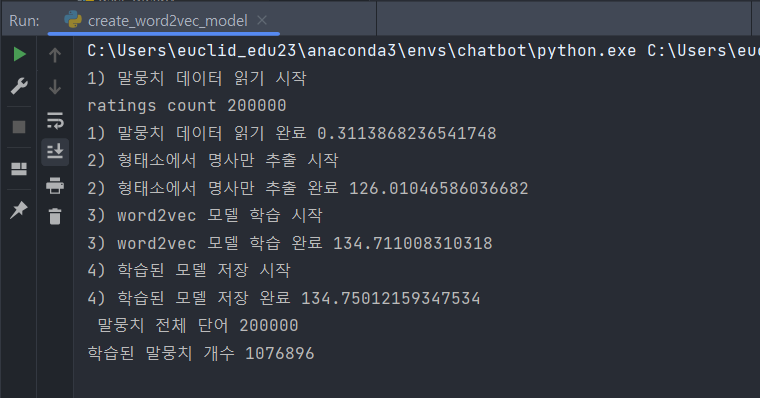
start = time.time() print('1) 말뭉치 데이터 읽기 시작') review_data = read_review_data('ratings.txt') print('ratings count',len(review_data)) #리뷰 데이터 전체 개수 print('1) 말뭉치 데이터 읽기 완료', time.time()-start)
위의 파일을 보면 (0번째 ID)1번째에 리뷰가 담겨 있다.
print('2) 형태소에서 명사만 추출 시작') komoran = Komoran() docs = [komoran.nouns(sentence[1]) for sentence in review_data] print('2) 형태소에서 명사만 추출 완료', time.time()-start)
- sentence=모델 학습에 필요한 데이터, vector_size=단어 임베딩 차원, window=주변 단어 윈도우 크기
- 나랑 비슷한 200개의 단어만, window는 얼마나 보고 비슷하다고 판단할래
- sg= 0 -> 비슷한 여러개를 통해 하나를 예측(여러개의 단어중 하나를 타깃으로 설정), sg=1 '나'를 기준으로 나와 비슷한 여러 개의 단어 찾기 (window를 4로 설정했으므로 나와 비슷한 4개의 단어들을 찾는다)
print('3) word2vec 모델 학습 시작') model = Word2Vec(sentences=docs, vector_size=200, window=4, sg=1) print('3) word2vec 모델 학습 완료', time.time()-start)
model.save('nvmc.model') print('4) 학습된 모델 저장 완료', time.time()-start) print(' 말뭉치 전체 단어', model.corpus_count) print('학습된 말뭉치 개수',model.corpus_total_words)
Word2Vec로 유사한 단어 임베딩 -2
from gensim.models import Word2Vec
모델 로딩
model = Word2Vec.load('nvmc.model') print('corpus_total_words', model.corpus_total_words)
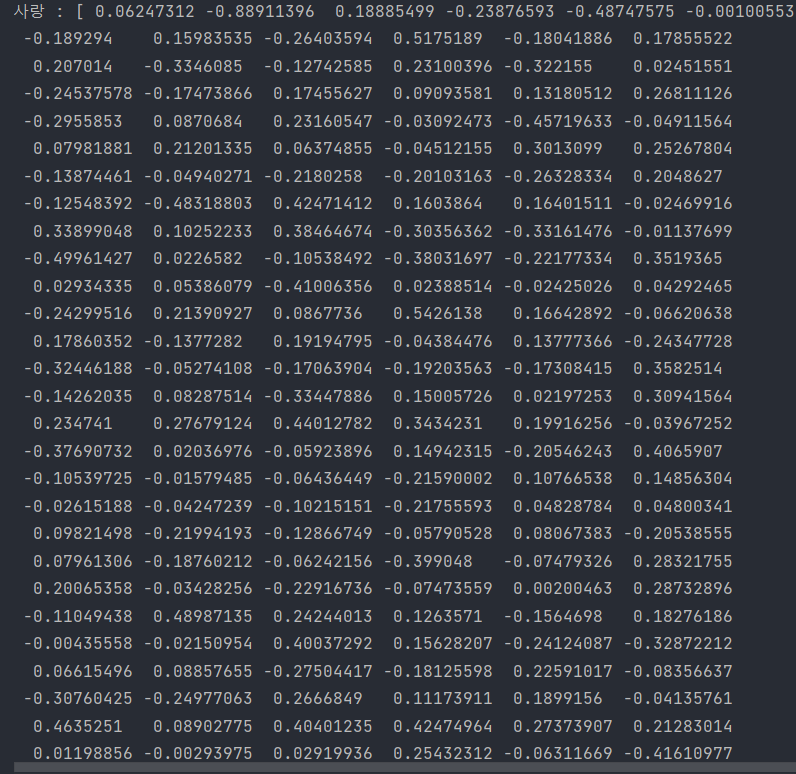
사랑이라는 단어로 생성된 단어 임베딩 벡터 -> 200개
print('사랑 :', model.wv['사랑'])
단어 유사도 계산 -> 벡터 공간에서 가장 가까운 거리에 있는 단어를 반환 (0~1)
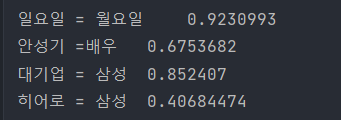
print('일요일 = 월요일\t',model.wv.similarity(w1='일요일', w2='월요일')) print('안성기 =배우\t',model.wv.similarity(w1='안성기', w2='배우')) print('대기업 = 삼성\t',model.wv.similarity(w1='대기업', w2='삼성')) print('히어로 = 삼성\t',model.wv.similarity(w1='히어로', w2='삼성'))
유사한 단어 추출
print(model.wv.most_similar('안성기', topn=10)) # 안성기와 가장 가까운 벡터구간의 10개 print(model.wv.most_similar('시리즈', topn=10))

Word2vec 장점
- 기존의 카운트 기반 방법으로 만든 단어 벡터보다 단어 간의 유사도를 잘 측정 단어들의 복잡한 특징까지도 잘 잡아냄
- 단어 벡터는 서로에게 유의미한 관계를 측정할 수 있다는 점 벡터 연산을 통해 대상 간의 의미 관계를 추론
#ABC부트캠프 #유클리드소프트 #2022청년ESG지원사업 #코딩 #대전부트캠프 #대전청년 #ESG경영 #파이썬 #빅데이터 #대전IT교육 #프로그래밍 #개발자 #진로탐색 #데이터교육 #ESG교육

다정~ 태그 어디갔죠?
태그도 같이 써주세요