Lookahead
- optimizer보다는 기존 optimizer에 덧붙여서 사용하는 기법이라고 볼 수 있다.
- 개념은 간단합니다. k번의 업데이트를 미리 진행하고, 최종 weight는 k번 업데이트된 weight를 따라가도록 업데이트됩니다.
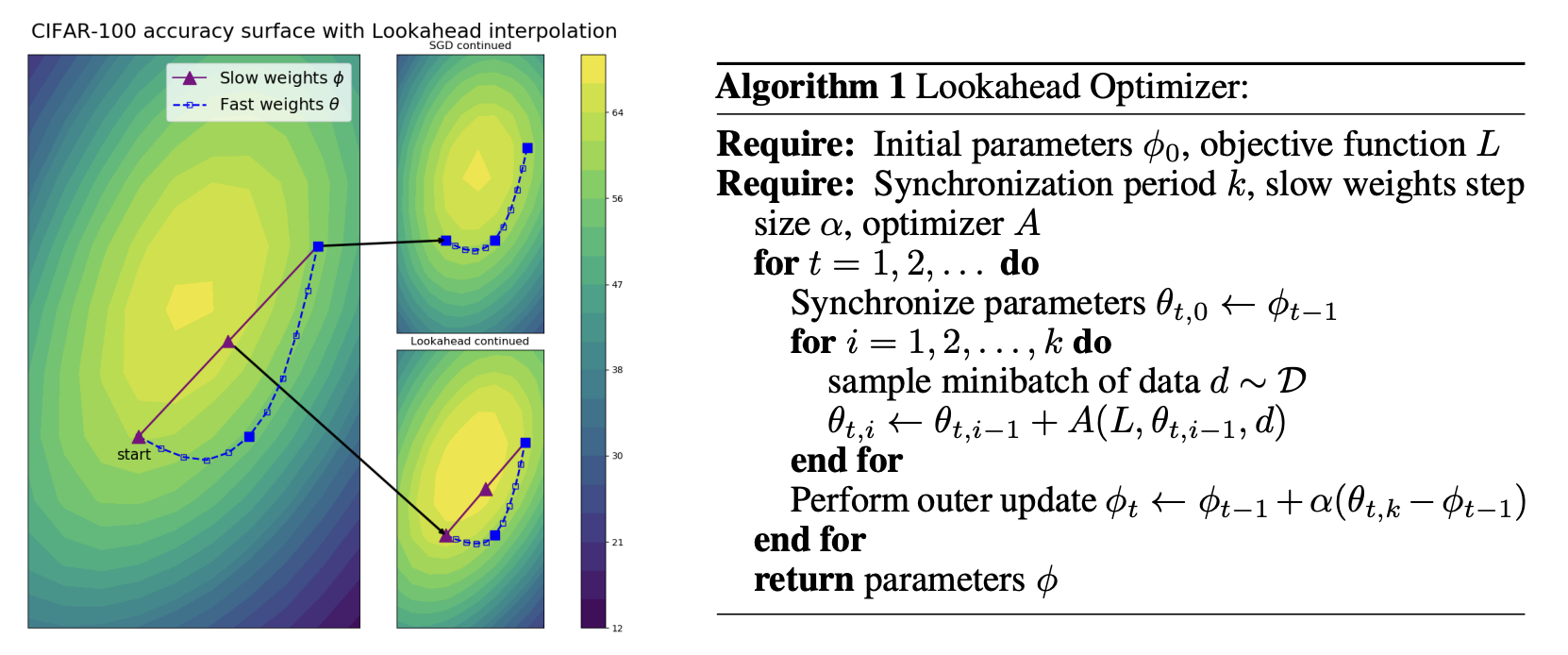
- 그림에서 theta와 파이가 각각 fast weight, slow weight라고 명시되어 있습니다.
- fast weight는 k번의 step을 미리 가볼, 즉 미리 업데이트해보는 weight이고, slow wegiht는 최종으로 사용할 weight입니다.
- k번의 업데이트를 먼저 수행하고, 최종 weight는 그것을 따라가게 함으로써, weight 업데이트에서 겪는 진동현상을 겪지 않고 안정적인 방향으로 나아갈 수 있습니다.
- 그림에서 보이듯이 파란색의 업데이트 과정들을 수행하고, 최종 weight는 k번 이후의 목적지 방향으로 바로 움직일 수 있기때문에 학습 과정의 진동이나 local minima 문제를 피할 수 있습니다.

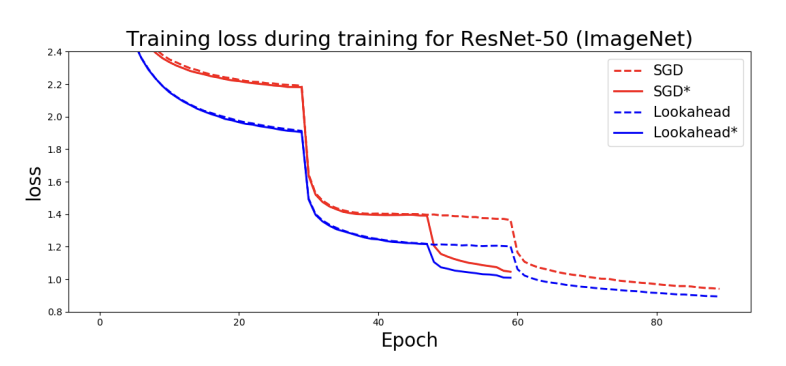
- 논문의 실험으로 보이듯이, lookahead를 사용했을 때 train loss로 보아 학습이 더 잘되는 것을 알 수 있습니다.
- 또한, 기존 Adam보다 성능도 좋아지는 것을 볼 수 있습니다.
RANGER optimizer
- RAdam optimizer에 대해서는 다룬 적이 있는데요, Adam의 분산문제를 보완한 optimizer입니다.
- RANGER는 이러한 RAdam과 Lookahead를 결합한 optimizer로 현재 가장 자주 쓰이는 optimizer조합 중 하나입니다.
Reference
https://arxiv.org/pdf/1907.08610#page=10&zoom=100,144,604
