Adam optimizer 단점
-
Adam optimizer는 준수한 성능을 보이지만, 이동 평균을 이용하기 때문에 batch sample이 충분히 쌓이지 않은 학습 초기에는 문제가 있을 수 있습니다.
-
특히 분산의 이동 평균에서 문제가 생길 수 있는데, sample이 충분히 쌓이지 않으면 분산 값이 매우 커지는 문제가 있습니다.
-
그렇게 되면 Adam의 수식 상 learning rate가 매우 작아지게 되고, local optima에서 학습이 종료될 수 있습니다.
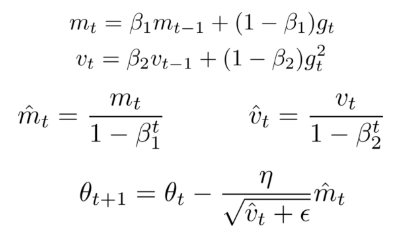
-
RAdam 논문의 실험을 살펴봅시다.
-
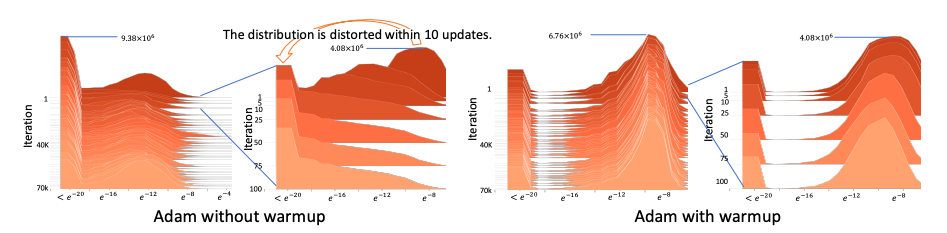
일단은 warmup을 신경쓰지 않고 왼쪽 그림을 살펴봅시다. x축이 gradient value이고, y축이 iteration 그리고 z축이 파라미터 개수라고 생각하면 됩니다.
-
10 update만에 gradient값들이 매우 작은 값들로 수렴되는 것을 볼 수 있습니다. 이처럼 Adam은 초기에 분산이 매우 크기때문에 learning rate가 매우 작아져 local minima에 빠져 학습이 종료될 수 있음을 보여줍니다.
-
이를 해결하기 위해 보통은 warm-up 방식을 사용하게 되는데요, 이는 학습 초기에 sample들이 쌓이기 전까지 작은 learning rate들을 적용하는 것을 말합니다. 예를 들어, adam의 이동평균 식을 사용하지 않고, learning rate를 linear하게 매우 작은 값에서 시작할 learning rate값까지 상승시키면서 sample 수를 쌓을 시간을 가지는 것입니다.
-
그러한 warm-up을 거치게 되면 오른쪽 그림처럼 안정적인 학습 과정을 볼 수 있지만, 실험하는 입장에서는 hyper parameter가 하나 더 늘어난셈이 됩니다.
RAdam (Rectified Adam)
-
RAdam은 이러한 adam의 초기 분산 문제를 해결하기 위해 rectification term을 추가한 optimizer입니다.

-
위 그림이 전체 알고리즘입니다.
-
자유도라는 개념이 등장하는데요, 이는 통계학에서 많이 사용되는 용어로 여기서는 학습이 얼마나 진행되었는지를 판단하는 값으로 생각하시면 됩니다.
-
이 자유도라는 값이 4이하일 때에는 sample이 많이 쌓이지 않았기 때문에, 분산값을 사용하지 않고 momentum만으로 학습을 진행합니다.
-
그 후, 충분한 sample이 쌓인 자유도_t가 4 초과일 때에는 rectified term을 곱해주게 됩니다.
-
위의 수식과 같은 rectified term을 추가합니다.
-
여기서 p_t는 step t에서의 자유도로 4초과의 값을 가지는 값입니다. 그리고 p_infinity는 학습이 충분히 되었을 때의 자유도로 beta값을 이용해 도출되며, 0.999의 경우 2000이라고 합니다.
-
즉, 해당 식은 충분히 학습이 진행될수록 1에 가까워 지는 값이라고 생각하면 됩니다. 그 전에는 step에 따라 가중치를 부여한다고 생각하면 됩니다.
-
이러한 과정을 통해 초기 분산값에 대한 대처를 하고, 충분히 학습되었을 때(수식이 1이 되었을 때)부터는 기존의 Adam과 같은 식으로 learning rate가 설정됨을 알 수 있습니다.
