Gradient Descent
- 전체 데이터에 대해서 미분값 계산 및 업데이트
Stochastic Gradient Descent
- 전체 데이터가 아니라, 하나하나의 sample마다 업데이트를 진행하는 방식입니다.
- 하나씩 계산하기 때문에 학습 속도가 빠르다는 장점이 있지만, 기울기가 매번 달라 학습 방향이 잘못될 수 있어, 학습이 진동하고 수렴이 더딜 수 있습니다.
Mini-batch Gradient Descent
- GD와 SGD의 장점을 합친 방식으로 여러 개의 sample을 합쳐 mini-batch 형태로 미분값을 계산해 업데이트합니다.
- 학습 속도가 GD보다 빠르며, 기울기가 SGD보다 안정적이기 때문에 진동이 덜하고 수렴도 빠릅니다.
- 하지만, batch 크기마다 성능이 다를 수 있습니다.
- 요즘은 mini-batch GD를 그냥 SGD라고 부릅니다.
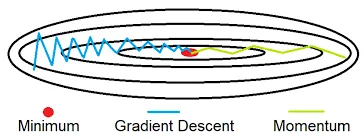
Momentum
- 말 그대로 관성을 이용하는 방식으로, 이전 기울기와 현재 기울기의 가중 평균을 통해 업데이트 하는 방식입니다.
- 이전 기울기도 사용하기 때문에, 기울기의 방향이 많이 바뀌지 않아 진동이 적고 기울기에 가속을 가하기 때문에 local minima에 빠지는 문제를 보완할 수 있습니다. 또한 수렴 속도도 더 빠르게 됩니다.
Nesterov Accelerated Gradient
- momentum은 이전 기울기가 잘못되었을 경우, 학습이 망가질 가능성이 있습니다.
- 이러한 문제를 해결하기 위해 NAG가 등장했습니다.
- momentum을 이용해 parameter를 업데이트한 위치에서 다시 미분값을 구해 현재 파라미터를 업데이트 하는 방식으로, 잘못된 기울기를 다시 바로잡는 방향으로 움직인다고 생각하면 됩니다.
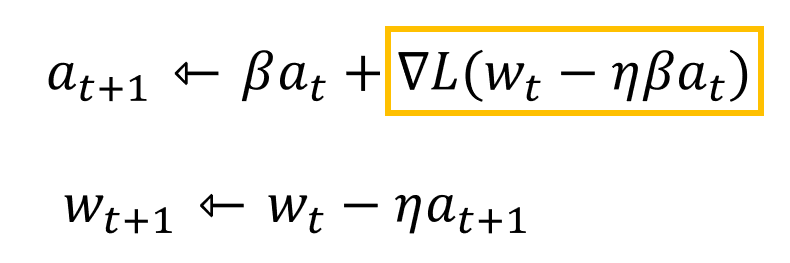
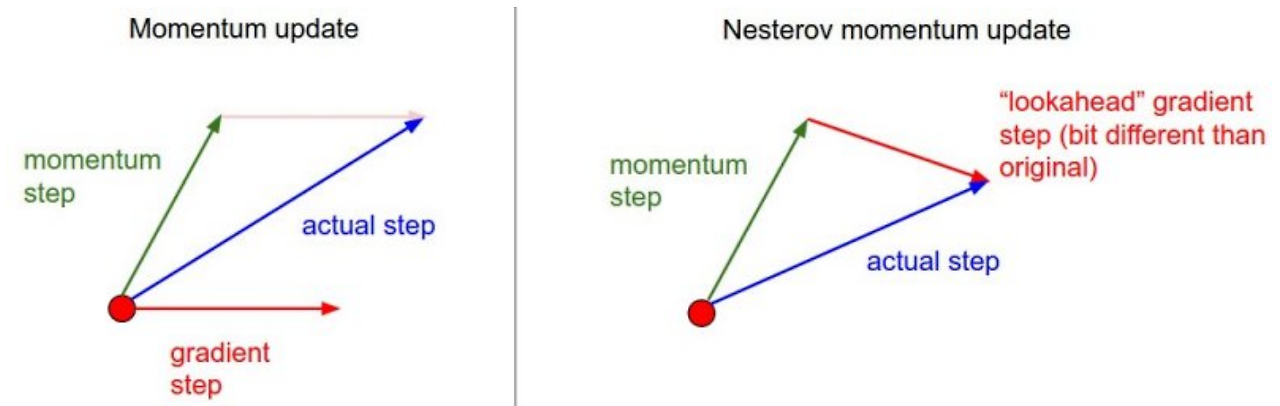
AdaGrad
- 여기부터는 learning rate 관련 방식들입니다.
- 기울기의 방향도 중요하지만, learning rate의 설정에 따라 학습의 결과는 매우 달라질 수 있습니다.
- AdaGrad는 하나의 learning rate로 모든 파라미터를 업데이트하는 것이 아닌, 파라미터별로 다른 learning rate를 두어야 한다는 아이디어입니다.
- 파라미터별로 얼마나 학습되었는지의 대한 양을 기록해두고, 많이 학습된 파라미터는 이미 수렴이 되었을 가능성이 있으니 learning rate를 줄이고, 반대는 늘리는 방식입니다.
- 따라서 지금까지 변화한 양(기울기의 제곱 누적합)을 저장해두고, 각 파라미터마다 이를 활용해 learning rate를 조절합니다.
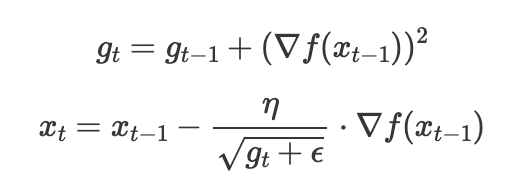
RMSProp
- AdaGrad의 기울기 누적합은 계속해서 커질 것이고, 그에 따라 learning rate는 대부분 0이 될 것입니다.
- 이를 해결하기 위해 RMSProp이 나왔으며, 누적합이 아니라 이동평균을 사용함으로써 현재 기울기에 맞게 일정 수준으로 learning rate를 바꿉니다.
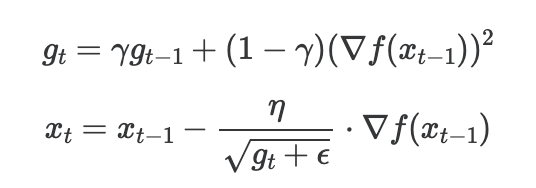
Adam
- momentum과 RMSProp을 조합한 방식입니다.
- 기울기를 momentum처럼 이동 평균으로 구하고, learning rate도 기울기 누적의 이동 평균을 통해 수정합니다.
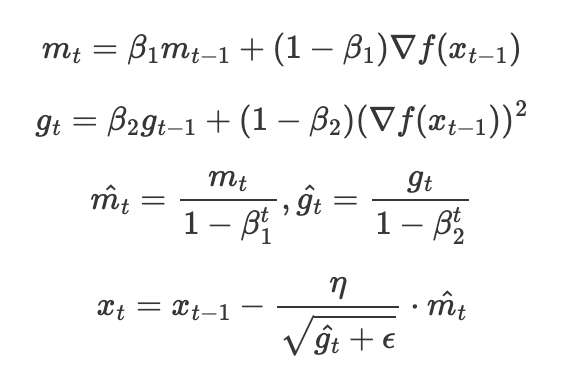
- 초기에는 이전 기울기가 없기 때문에 m과 g가 0이 될 가능성이 많으므로, m_hat과 g_hat을 사용합니다.
Reference
https://medium.com/analytics-vidhya/welcome-to-the-second-part-on-optimisers-where-we-will-be-discussing-momentum-and-nesterov-c2698d5590e
