Overfitting 감지
overfitting은 학습 데이터에 너무 fit해서 unseen data에 대해 일반화되지 않는 현상을 말합니다. 이러한 overfitting을 방지하기 위해서는 먼저 현재 모델이 overfitting되어 있는지 확인할 줄 알아야 합니다.
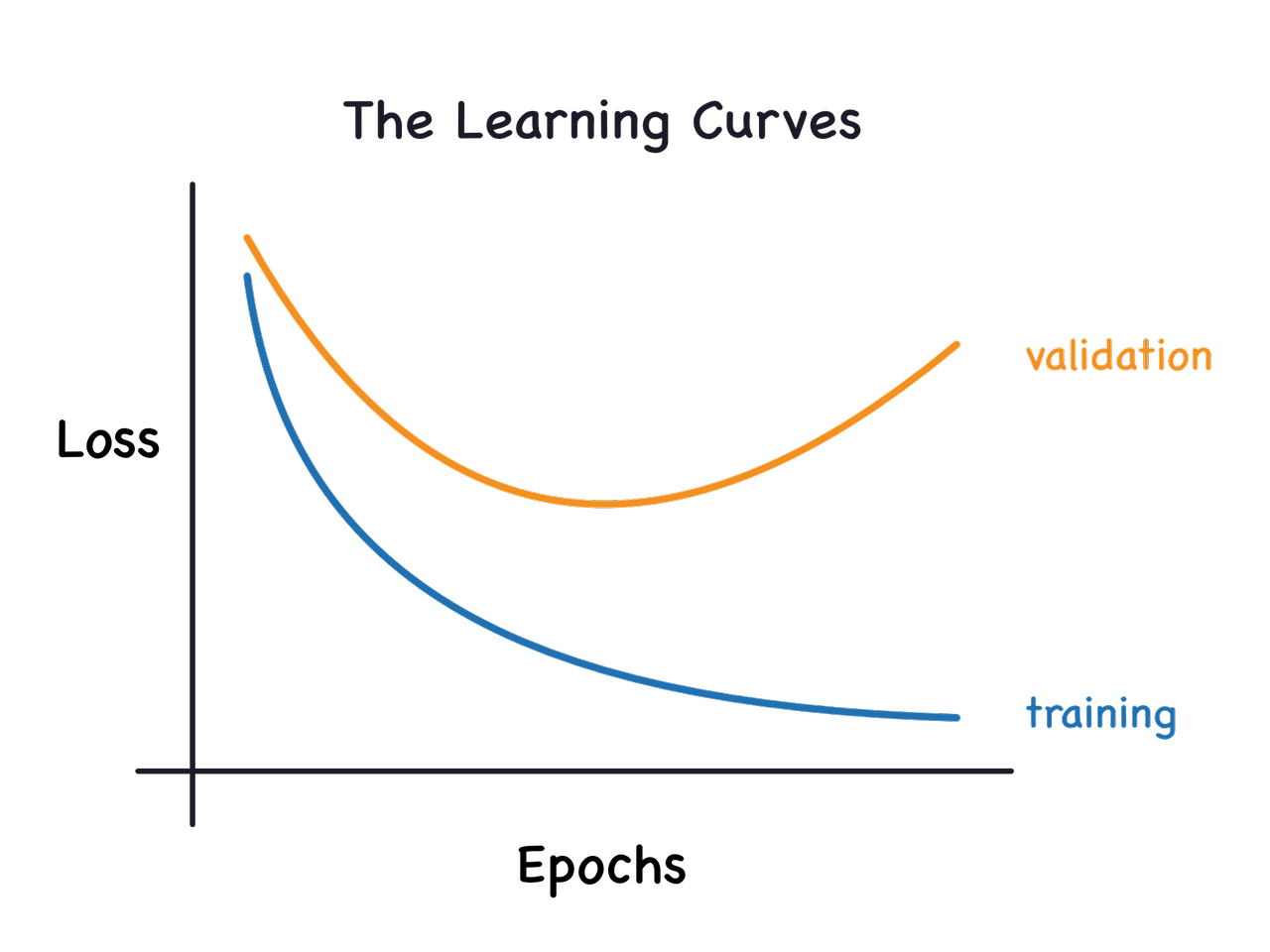
보통은 아래의 learning curve를 통해 유추가능합니다.
- training loss는 계속해서 떨어지지만, unseen data인 validation set에 대해서 loss가 다시 상승하는 구간이 일반화 성능이 떨어지는 overfitting 구간입니다.
Overfitting 방지 기법들
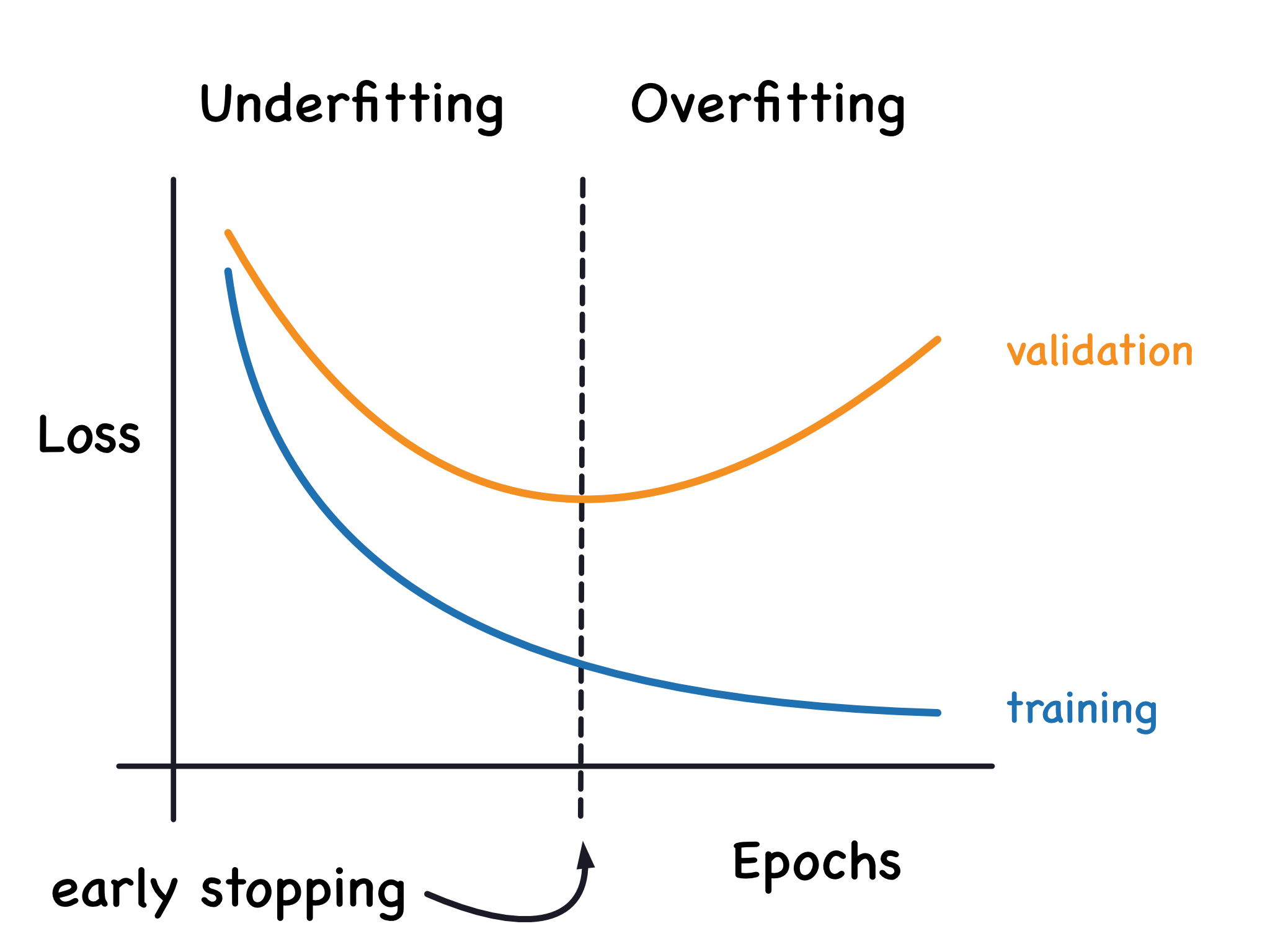
- Early Stopping
- 위의 learning curve에서 overfitting 구간에 진입하기 전에 모델 학습을 종료시키는 기법입니다. 아래 그림과 같습니다.
- Regularization
-
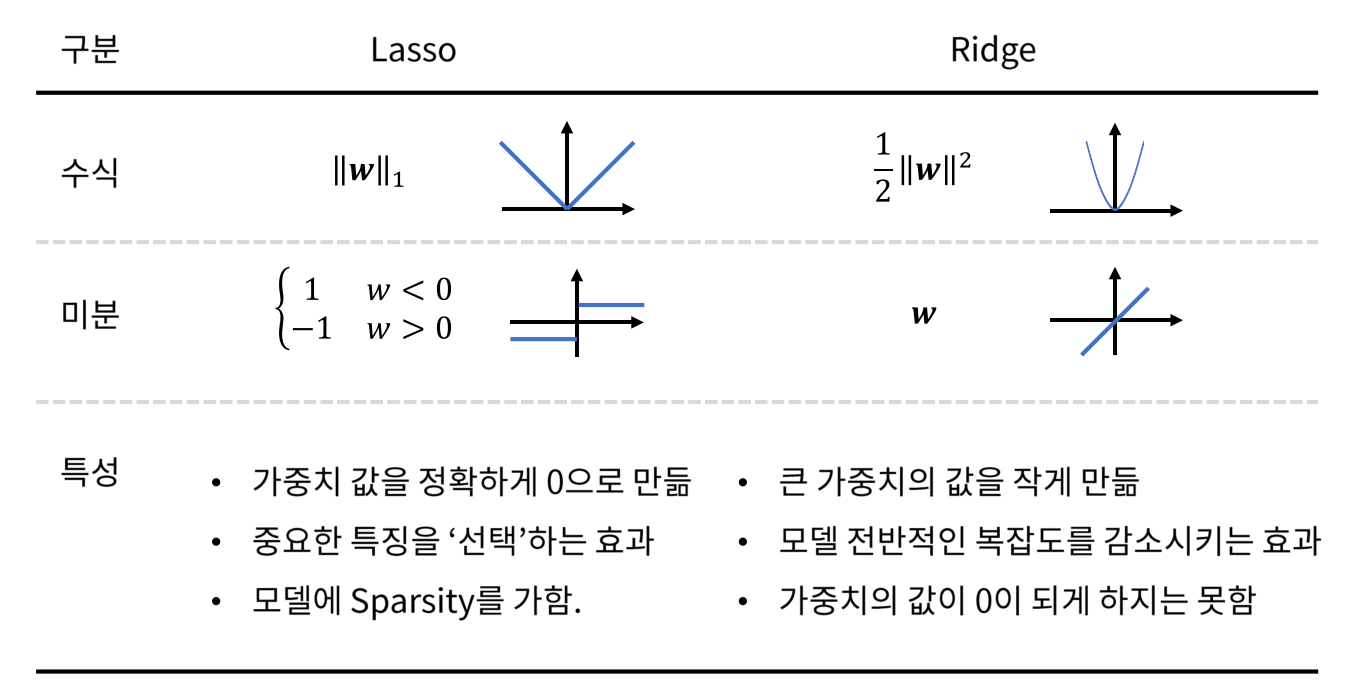
대표적으로 L1, L2 regularization이 있으며, loss function에 각각 L1 norm, L2 norm term을 추가하는 방식입니다. norm은 벡터 크기를 측정하는 방식으로 아래 수식과 같습니다.
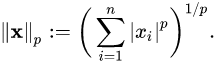
-
모델의 weight값을 작게 만들면 모델을 간단하게 만드는 효과를 갖습니다. 예를 들어, polynomial regression에서 각 변수의 계수가 0에 가깝거나 0이 된다면 해당 차수에 대한 식이 사라지는 효과를 보게 되므로 모델의 복잡도가 줄어듭니다.
-
이처럼 L1, L2 regularization은 weight에 대한 l1, l2 norm을 loss function에 추가함으로써 모델을 간소화시키는 regularizing 효과를 제공합니다.
-
L1 regularization이 포함된 loss function을 w에 대해 편미분하면 아래와 같습니다. C0는 기존 cost function이고, sgn() 는 부호를 의미합니다.
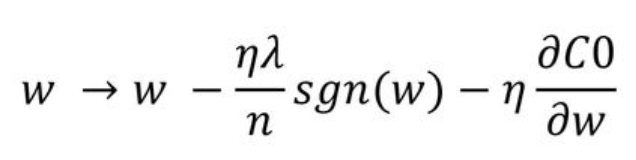
-
즉, L1 regularization은 weight의 크기에 관계없이 지속적으로 weight를 상수값만큼 update합니다. 따라서, weight가 0이 될 수 있으며, 이는 feature가 사라지는 것을 의미합니다.
-
L2 regularization은 편미분을 해도 weight가 남아있기 때문에 weight를 0으로 만들기는 어렵습니다. 따라서 필요없는 feature를 제거하는 효과보다는 전반적인 모델의 복잡도를 줄여주는 역할이 가능합니다. 정리해보면 아래 표와 같습니다.
- Dropout
- Dropout은 아래 그림처럼 일정 확률로 각 layer의 activation을 0으로 만드는 것을 의미한다.
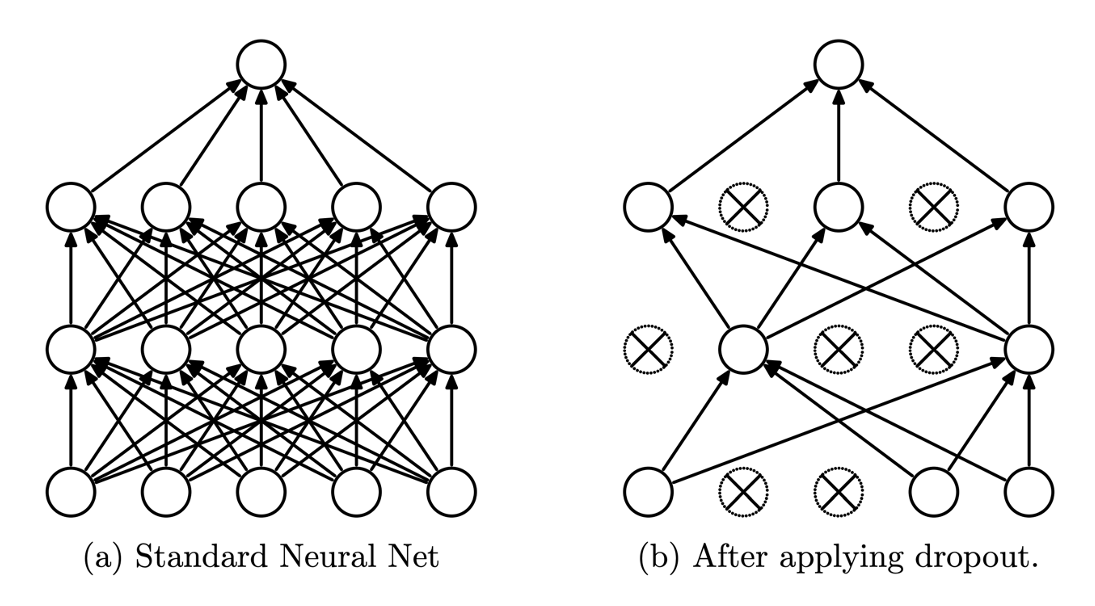
- 매번 다른 layer들의 조합으로 학습이 진행되기 때문에, 하나의 layer에 의존하지 않도록 학습되어 모델의 복잡도를 줄이는 효과와 더불어 모델의 일반화 성능을 높일 수 있습니다.
- 데이터 다양화
- overfitting은 데이터에 비해 모델이 복잡해서 나타나는 현상이므로, 데이터 자체를 더 복잡하고 다양하게 넣어주면 보완이 가능하다.
- 데이터를 더 수집해서 넣거나, data augmentation을 통해 다양한 상황의 데이터들을 학습에 추가해주면 overfitting을 방지할 수 있다.
- data augmentation이란 아래 그림처럼 학습 데이터를 조작해 새로운 데이터처럼 만들어서 모델에 넣어주는 것을 의미합니다.

Reference
https://www.kaggle.com/code/ryanholbrook/overfitting-and-underfitting
https://wooono.tistory.com/221
https://gaussian37.github.io/dl-concept-regularization/
https://kh-kim.github.io/nlp_with_deep_learning_blog/docs/1-14-regularizations/04-dropout/
https://www.analyticsvidhya.com/blog/2023/12/mosaic-data-augmentation/
