Perceptron
- 아래 그림과 같은 인간의 뉴런을 모방해 만든 아주 작은 인공 신경망입니다.
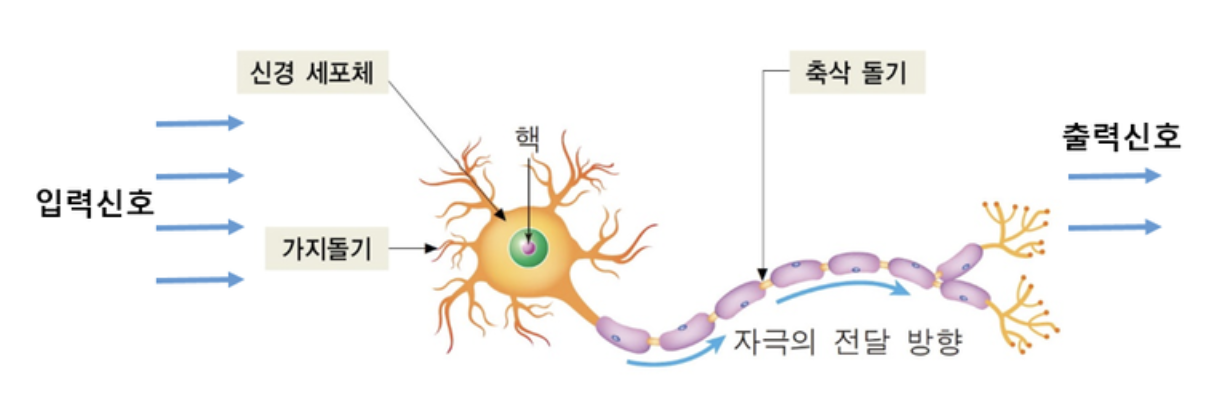
- 입력신호들이 가지돌기에 도착한 후, 신경 세포에서 이들을 하나의 신호로 통합하고, 어떤 임계값을 넘으면 단일 신호가 생성되어 출력신호로 나가는 이러한 구조를 모방했습니다.
- 퍼셉트론의 구조는 아래와 같습니다.
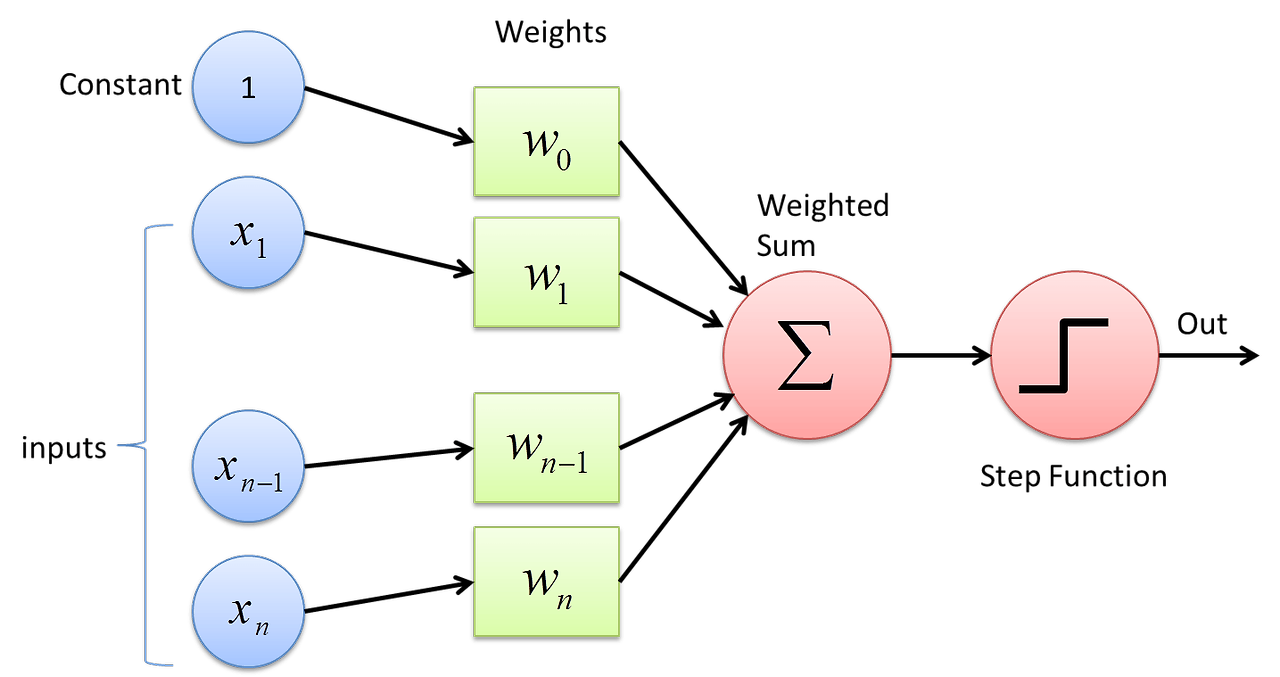
- 입력 신호들을 가중치의 weight sum으로 합치고 bias constant를 더한 뒤, step function을 통해 threshold를 넘는 지의 여부를 출력하는 구조입니다.
- Rosenblatt는 이러한 퍼셉트론 구조와 함께 정답과의 차이를 통해 weight를 학습하는 방식을 고안했으며, 선형 결합에 대한 좋은 예측 성능을 보여주었습니다.
Multi Layer Perceptron
- 위에서 언급한 퍼셉트론은 선형 연산입니다. 따라서 위에서 설명한 구조를 하나의 층만 사용한다면 비선형성 문제를 풀 수 없다는 문제가 생깁니다.
XOR 문제
- 단층 퍼셉트론은 선형연산이기때문에 하나의 직선 혹은 초평면으로 그려집니다. 만약 AND, OR, XOR 연산의 결과를 예측하는 모델을 만든다고 하면 문제가 생깁니다.
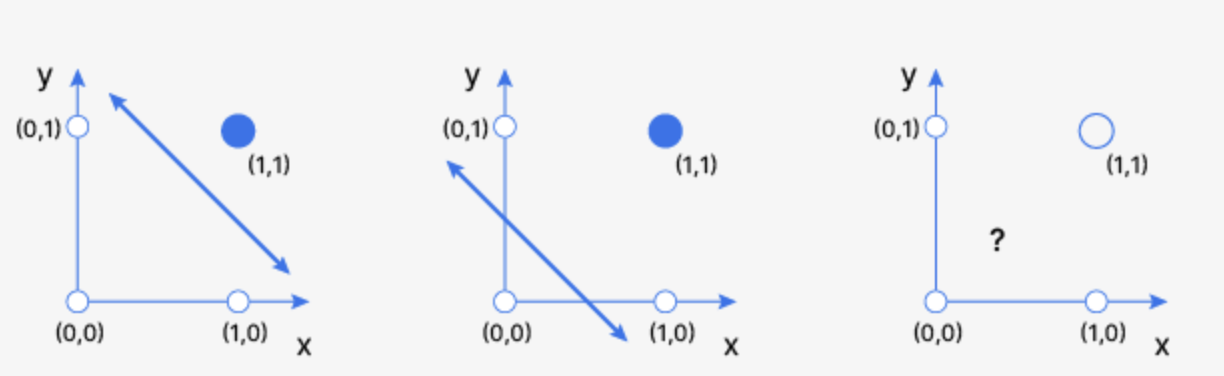
- 왼쪽의 AND 나 가운데의 OR 연산에 대해서는 선형 모델로도 예측이 가능합니다. 하지만, 다른 두 값은 1, 같은 두 값은 0으로 출력하는 XOR연산의 경우 하나의 직선으로는 decision boundary를 만들지 못합니다.
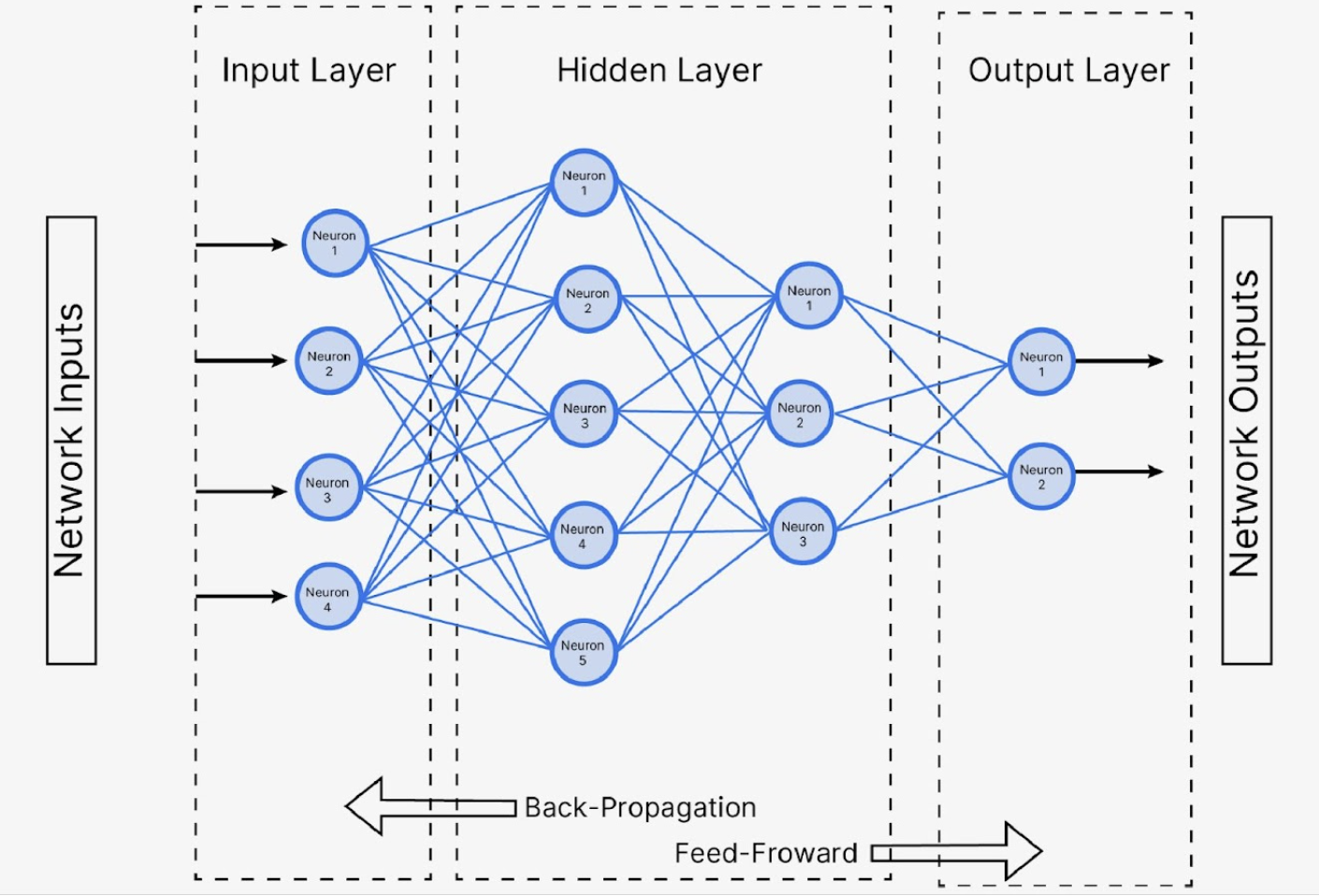
- 퍼셉트론의 XOR문제를 해결하여 우리가 보통 알고 있는 위의 그림과 같은 인공 신경망 구조가 생겨나게 됩니다.
- 비선형 함수를 포함한 퍼셉트론을 다층으로 쌓음으로써 복잡한 문제들을 모델링할 수 있었고, backpropagation 기법을 이용해 에러를 기반해 hidden layer parameter도 학습하게 되어 탄생할 수 있었습니다.
Convolutional Neural Network
- MLP(multi layer perceptron)은 다양한 복잡한 문제들을 해결할 수 있지만, 이미지같은 고차원의 문제를 해결하기에는 문제가 있었습니다.
- 파라미터 수가 너무 많음. 이미지의 모든 픽셀을 입력 신호로 사용한다면 파라미터 수가 많아집니다. 예를 들어, 100x100 이미지에서 각 픽셀들이 입력으로 들어간다면 mlp의 입력은 10000개가 됩니다.
- 공간적 정보 소실. 이미지의 경우 주변 픽셀들과의 관계가 중요한데, 단순 픽셀값의 나열로는 이러한 특성을 찾기 어렵습니다. 예를 들어, 50x50 픽셀은 51x50픽셀과 매우 인접한데, 단순 나열로 입력을 넣는다면 매우 멀리 떨어져 있을 수 있습니다. (50x50, 50x51, 50x52, ... 51x0, 51x1, ...51x50) 따라서 고차원 데이터의 구조적 특성을 학습하기 어렵습니다.
- 그에 따라 convolution filter를 사용하는 CNN이 등장했고, 장점은 아래와 같습니다.
- Convolution filter를 이용해 국소적인 특징 추출. 3x3, 5x5 등의 크기를 가지는 필터를 이미지 영역에 적용해 이미지의 구조적 정보를 살린 local feature를 얻을 수 있게 되었습니다.
- 필터를 공유해 파라미터 수 줄임. 이러한 convolution filter를 공유해서 하나의 filter로 이미지 전체 영역에 대한 feature를 추출하여 파라미터 수를 줄였습니다. 예를 들면, 3x3짜리 엣지를 검출하는 filter라고 하면, 이를 이미지 전체 영역에 모두 적용해 이미지에 있는 엣지 정보들만 추출한 하나의 feature map을 만드는 방식입니다.
Translation invariance
- 이러한 CNN은 하나의 특성이자 장점을 가지고 있습니다. 해석하면 이동불변성으로 이미지 내의 정보들이 이동한다고 해도 특징들을 동일하게 잘 추출한다는 것입니다.
- 예를 들어, 이미지에 고양이가 있는지 판별하는 모델을 만든다고 하면, 고양이가 왼쪽 위에 있든, 오른쪽 아래에 있든 판별이 가능합니다.
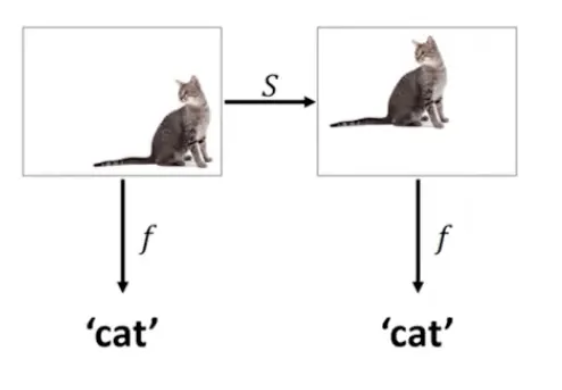
- 이미지의 모든 영역에 대해 공유된 필터 사용. 하나의 필터를 이미지의 다른 영역에도 동일하게 사용하기 때문에, 위치가 변형된 이미지에 대해서도 feature들을 추출할 수 있습니다.
- pooling layer.
- 필터가 학습한 특성을 축소시키는 layer로, 패턴의 세부적인 위치 정보를 희석시킵니다. 예를 들면, max pool이 있고 feature들 중 최대값을 가지는 feature만 output으로 뱉는 layer입니다.
- 이미지의 공간적 크기를 줄이고 위치변화에 민감성을 줄여줍니다.
- 예를 들어 max pooling의 경우 최댓값만을 output으로 뱉기 때문에 위치가 변화하더라도 중요한 특성만을 추출해낼 수 있고, 그에 따라 translation invariance 특성을 가지게 해줍니다.
Reference
https://blog.naver.com/samsjang/220948258166
https://medium.com/@sue.sk.guo/all-you-should-know-about-translation-equivariance-invariance-in-cnn-cbf2a2ad33cd
https://bunnycode.tistory.com/20
https://www.analyticsvidhya.com/blog/2024/01/xor-problem-with-neural-networks-an-explanation-for-beginners/
