Triton Inference Server
Triton Inference Server 는 NVIDIA 에서 공개한 open-source 추론 지원 소프트웨어입니다.
그렇다면 굳이 사용하는 이유는?
개인적으로 생각하기에 가장 큰 이유는 편해서입니다.
따로 backend 라이브러리를 공부할 필요 없이, 학습된 모델 파일+config파일 몇개+전후처리 코드 정도만 구성해주면 바로 추론 서버를 제작할 수 있습니다.
또한 아직 다 사용해보진 않았지만, 다이나믹 배치 추론, multi-gpu 지원, Prometheus 메트릭 지원 등등 이미 제공하는 좋은 기능들도 많이 존재합니다.
Triton 서버 제작
제가 작성한 example code를 토대로 간단한 Triton 서버를 제작하는 과정을 보여드리겠습니다.
flow는 대충 아래와 같습니다.
1. model 파일 제작 (serialize)
2. config 파일 작성
3. 전/후처리 코드 작성
4. Triton image pull & run!
1~3을 완료하면 하나의 모델 폴더 를 만들 수 있는데요, 구조는 아래와 같습니다.
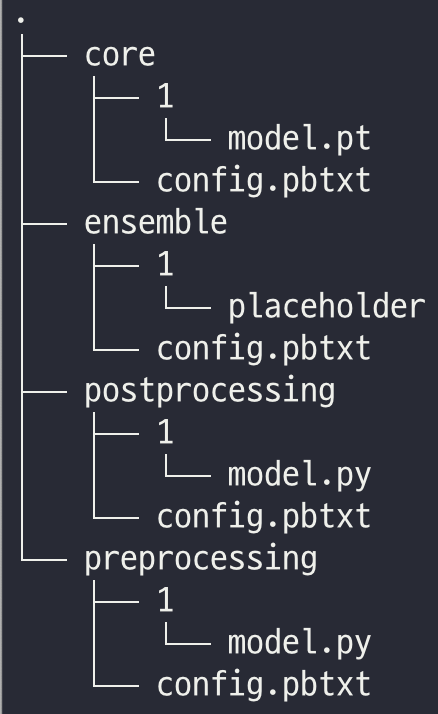
이렇게 만들어진 폴더를 triton docker image에 binding해서 컨테이너를 띄우면 서버 제작완료입니다.
Model 파일 제작
Training이 완료된 모델을 배포하기 위해서는 serialize작업이 필요한데요, 저의 경우에는 PyTorch로 모델링을 주로 하기때문에, torchscript를 사용했습니다. 방법은 코드 두 줄이면 끝입니다!
script_model = torch.jit.script(PYTORCH_MODEL)
torch.jit.save(script_model, SAVE_PATH)물론 Triton은 torchscript 이외에도 tensorRT, onnx 등등 다양한 framework를 지원하기 때문에 편한 방식을 사용하면 됩니다.
config 파일 작성
자세한 내용은 Triton model configure docs 를 참고하세요.
Triton의 모델 폴더에 존재하는 폴더들은 각각 하나의 모델 취급을 받게 되는데요, 각각의 모델들은 모두 config.pbtxt 파일을 가지고 있어야 합니다.
config 파일에서 꼭 포함해야 할 내용은 platform 그리고 input/output 설명 입니다.
platform 은 이 모델이 어떤 framework를 기반으로 작성되었는지를 명시합니다. pytorch인지, tensorflow인지 혹은 그냥 python(전후처리 코드) 인지요.
input/output 설명은 input output의 data type, dimension 등을 명시합니다.
아래는 이를 기반으로 작성한 예시 config 파일입니다. resnet50 모델을 추론하는 config입니다. -1 값은 값 미정 을 의미합니다.
name: "core"
platform: "pytorch_libtorch"
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [-1, 3, -1, -1]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [-1, -1]
}
]일반적인 모델들은 위와 같은 식으로 작성을 하면 되는데요, 가장 중요한 config 파일이 하나 남았습니다.
바로 전체 flow를 지정하는 ensemble 모델 입니다.
제가 작성한 모델 구조는 전처리 > 모델 추론 > 후처리 이렇게 간단한 구조인데요, 이러한 flow를 ensemble에서 명시해주어야 합니다.
아래는 그 예시입니다.
platform은 ensemble을 사용해주고, step 부분에 flow를 순서대로 작성해주면 됩니다.
name: "ensemble"
platform: "ensemble"
input [
{
name: "image",
data_type: TYPE_STRING,
dims: [-1],
}
]
output [
{
name: "result",
data_type: TYPE_STRING,
dims: [-1],
}
]
ensemble_scheduling {
step [
{
model_name: "preprocessing",
model_version: -1,
input_map {
key: "image",
value: "image
},
output_map {
key: "input_image",
value: "input_image"
}
},
{
model_name: "core",
model_version: -1,
input_map {
key: "INPUT__0",
value: "input_image"
},
output_map {
key: "OUTPUT__0",
value: "scores"
}
},
{
model_name: "postprocessing",
model_version: -1,
input_map {
key: "INPUT__0",
value: "scores"
},
output_map {
key: "result",
value: "result"
}
}
]
}전/후처리 코드 작성
사실 모델링을 할때 이미 전/후처리 코드는 작성하는 경우가 대부분이기 때문에, Triton python backend 사용법만 알면 됩니다.
python backend 코드는 TritonPythonModel class를 구현해야 합니다. 이 class는 4개의 멤버 함수를 제공하는데, 보통 execute함수만 잘 구현하면 됩니다.
execute함수는 model에 request가 들어왔을 때 실행되는데요, 여기에 전/후처리를 잘 적용해서 response로 묶어서 return 해주기만 하면 됩니다.
python backend에 대한 자세한 내용은 docs를 참고하세요.
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
"""
preprocessing main logic
"""
def execute(self, requests):
responses = []
for request in requests:
## get request
raw_images = pb_utils.get_input_tensor_by_name(request, "image").as_numpy()
## make response
input_image = gen_input_image(raw_images) ## 전/후처리 수행하는 함수
input_image_tensor = pb_utils.Tensor(
"input_image", input_image.astype(np.float32)
)
response = pb_utils.InferenceResponse(
output_tensors=[input_image_tensor]
)
responses.append(response)
return responsesTriton image pull & run
이제 만들어진 모델 폴더를 실제로 Triton 에 적용시켜서 컨테이너를 띄워봅시다.
일단 자신의 환경에 맞는 Triton 버전을 확인해야 합니다. 이 docs에 지원하는 cuda 버전, framework 버전 등등 명시가 되어 있습니다.
그 이후 해당 버전의 triton image를 pull합니다. 여기에 이미지 tag 리스트가 있습니다.
docker pull nvcr.io/nvidia/tritonserver:21.10-py3그 이후 아래 명령어로 컨테이너를 띄워줍니다.
docker run --gpus='"device=0"' -it --rm --shm-size=8g -p 8005:8000 -v ${MODEL_FOLDER_PATH}:/model_dir nvcr.io/nvidia/tritonserver:21.10 tritonserver --model-repository=/model_dir --strict-model-config=false --model-control-mode=poll --repository-poll-secs=10 --backend-config=tensorflow,version=2 --log-verbose=1