Confusion matrix
- binary classification metric들을 알려면 가장 먼저 confusion matrix에 대해 알아야 합니다.
- binary classification은 모델이 결과를 True 혹은 False로 뱉을 수 있는 문제이고, confusion matrix는 이 모델 결과와 실제 정답과의 관계를 matrix 형태로 표현한 것입니다.
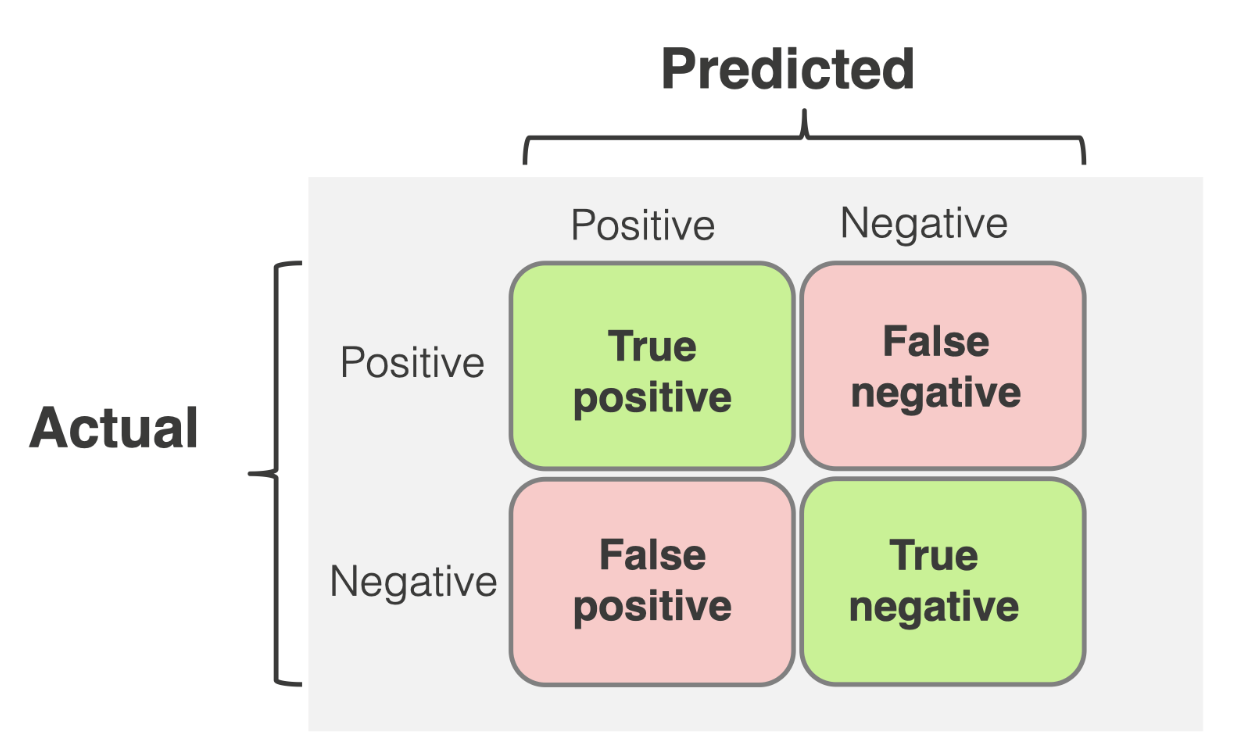
- 정리해보면 {맞춤or못맞춤}_{모델결과} 로 나타낼 수 있습니다.
- True Positive: 모델 True, 레이블 True
- False Positive: 모델 True, 레이블 False
- False Negative: 모델 False, 레이블 True
- True Negative: 모델 False, 레이블 False
Accuracy
- 전체 샘플들 중 맞춘 샘플의 비율입니다.
- (TP + TN) / (TP+TN+FP+FN)
- 데이터에 불균형이 있을 경우 문제가 됩니다.
예를 들어, 레이블 중 True가 99%, False가 1%라고 한다면, 모델은 모든 데이터에 대해 무지성으로 True값을 뱉어도 accuracy는 99%로 매우 높지만 False 레이블에 대해서는 아예 못 맞추는 상태입니다.
Precision
- 모델이 True라고 예측한 샘플들 중, 실제로 맞춘 샘플의 비율입니다.
- TP/(TP+FP)
- False positive를 잡는게 중요한 문제에서 사용됩니다.
예를 들어, 스팸 메일을 예측한다고 할 때, 스팸이 아닌데 스팸이라고 한다면(false positive) 문제가 됩니다.
스팸이 아니어서 사용자가 꼭 봐야하는 메일이 스팸 메일함에 들어가 있을 수 있기 때문입니다. 반면에 스팸인데 스팸이 아니라고 예측하는 것은 전자보단 문제가 덜 합니다.
Recall
- 레이블이 True인 샘플들 중, 실제로 모델이 맞춘 샘플의 비율입니다.
- TP/(TP+FN)
- False negative를 잡는게 중요한 문제에서 사용됩니다.
예를 들어, 암진단 모델을 만든다고 할 때, 암 환자에 대해 암이 아니라고 한다면(False negative) 큰 문제가 됩니다. 반면에 암이 아닌 환자에 대해 암이라고 예측한다면 전자보다는 환자 생명에 문제가 없는 작은 문제입니다.
F1-score
- precision, recall의 조화 평균입니다.
- 당연히 위의 precision, recall은 모두 중요한 성능 지표이고 이를 한번에 평균낸 값을 통해 모델을 측정하는게 합리적입니다.
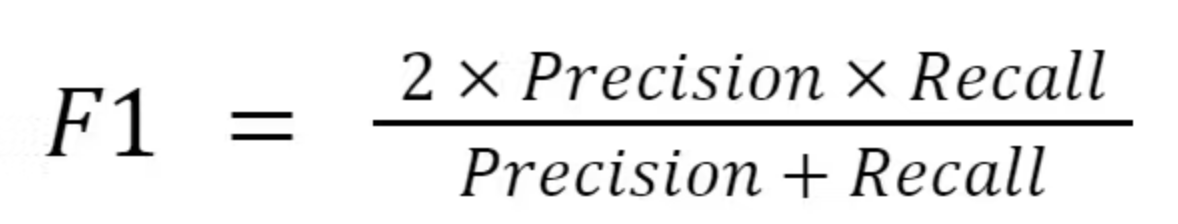
일반 평균을 사용하지 않는 이유
- precision, recall을 조합한다고 하면 당연히 그냥 일반적인 더하고 2로 나누는 평균을 생각할 수 있습니다.
- 하지만, precision:0.9, recall:0.1 라고 한다면, 평균값은 0.5로 생각보다 높습니다. 즉, 높은 값으로 인해 낮은 성능 지표의 의미가 희석될 수 있습니다.
- 반면에 F1-score로 조화평균을 계산하면 0.18로 낮은 지표를 가지는 것을 알 수 있습니다.
- 따라서, 두 개의 중요한 지표 모두를 고려한 모델을 만들고자 할 때, F1-score를 측정하는 것이 좋습니다.
ROC Curve, Precision-Recall Curve
- 일반적으로 binary classification 모델은 바로 True, False 값을 뱉는게 아닌 확률값(0~1 사이)을 뱉습니다.
- 따라서 일정 임계값(threshold)를 기준으로 Positive 혹은 Negative로 예측을 해야 합니다.
- 물론 기본적으로 중간값인 0.5를 잡을 수 있지만, 모델이 이 threshold에 민감할 수도 있습니다.
- 따라서, 이러한 threshold값에 따른 그래프를 그려서 성능 평가를 진행하고 이것이 ROC curve, precision-recall curve입니다.
Precision-Recall Curve
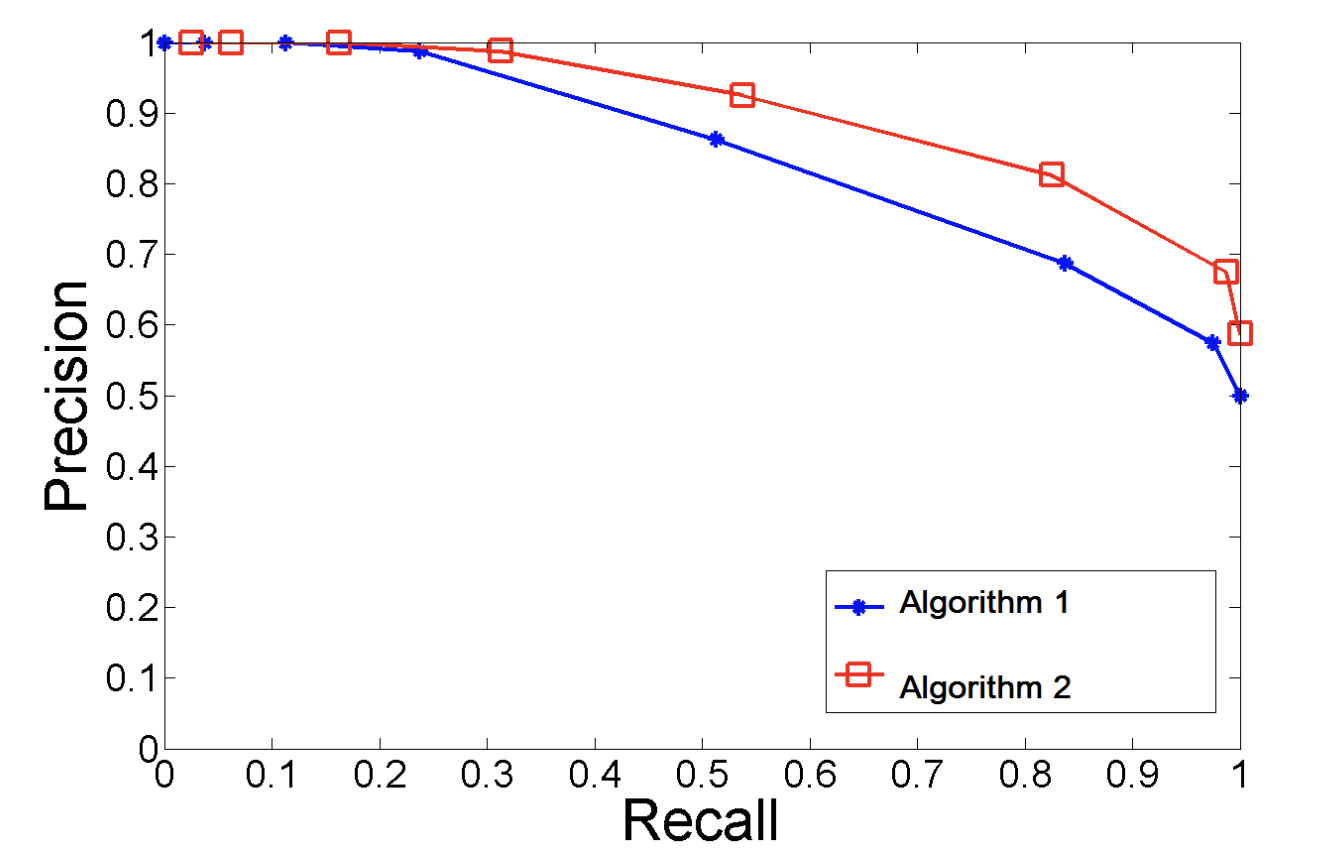
- 위에서 언급한대로 threshold값을 바꾸어 가면서 precision recall 값들을 plot한 그래프입니다.
- 예를 들면, threshold를 0.1로 설정했다면, 0.1 이상의 확률 값을 가지는 샘플을 모두 positive로 예측합니다. 그 후, precision, recall을 계산해 2D 그래프 상에 점으로 표시하는 방식입니다.
- 아래는 그러한 그래프의 예시입니다.
ROC Curve
- ROC curve는 precision, recall이 아니라 TPR(True Positive Rate), FPR(False Positive Rate)를 기준으로 그린 그래프입니다.
- True Positive rate는 Recall과 같은 의미로 레이블이 True인 샘플들 중 모델이 맞춘 샘플의 비율입니다.
- TP / (TP+FN)
- False Positive Rate는 레이블이 False인 샘플들 중 모델이 잘못 Positive로 예측한 비율입니다.
- FP / (FP+TN)
- 이 두 가지 값을 precision recall curve와 동일하게 threshold를 바꾸어가면서 그래프에 plot하면 됩니다.
ROC Curve vs Precision-Recall Curve
- ROC curve의 경우 negative 샘플이 많은 불균형 데이터셋에서 제대로 된 성능 평가가 안될 수 있습니다.
- 예를 들어, 95% 데이터가 negative label인 경우, False Positive 가 많아도 True Negative가 많기 때문에 FPR(False Positive Rate)가 낮게 평가될 수 있습니다.
- 반면에, precision recall curve의 경우 positive label에 중점을 두고 있기 때문에, 이러한 경우에도 사용할 수 있습니다.
- precision: 모델 positive 중 실제 positive
- recall: 레이블 positive 중 실제 positive
AUC
- Area Under the ROC Curve의 준말로 ROC curve의 아래 면적을 의미합니다.
- ROC curve는 성능 지표를 보여주기 좋은 그래프이지만, 수치화가 되어있지 않습니다. 따라서 ROC curve를 정량적으로 평가하기 위해 만든 성능 지표라고 보면 됩니다.
- Precision Recall curve도 같은 개념으로 AP(Average Precision)이 있고, 이는 AUC와 마찬가지로 precision recall curve 아래의 면적입니다.
- 아무래도 curve들 모두 threshold를 반영한 결과들이므로, accuracy같은 단일 임계값에서의 성능 평가 지표보다 모델의 성능 변화를 반영하기에 더 유용합니다.
Reference
https://www.evidentlyai.com/classification-metrics/confusion-matrix
https://encord.com/glossary/f1-score-definition/
https://www.datacamp.com/tutorial/precision-recall-curve-tutorial
