1. 학습 내용
CNN(Convolutional Neural Networks, 합성곱 신경망)
- 딥러닝에서 주로 이미지나 영상 데이터를 처리할 때 쓰인다.
- 데이터에서 직접 학습하고 패턴을 사용해 이미지를 분류하기 때문에 특징을 수동으로 추출할 필요가 없다는 장점이 있다.
- 자율주행자동차, 얼굴인식과 같은 객체인식이나 computer vision이 필요한 분야에 많이 사용된다.
1-1 Convolution
- Convolution 은 특징을 추출하는 데에 사용되는 연산
- 픽셀들로 구성된 데이터에 Convolution 필터가 이동하면서 곱셈 연산이 이루어지고 연산에 따라 값이 변화
- 즉, input 데이터(픽셀) * 필터 값의 결과가 Convolution
1-2 Convolutional Layer 계산방법
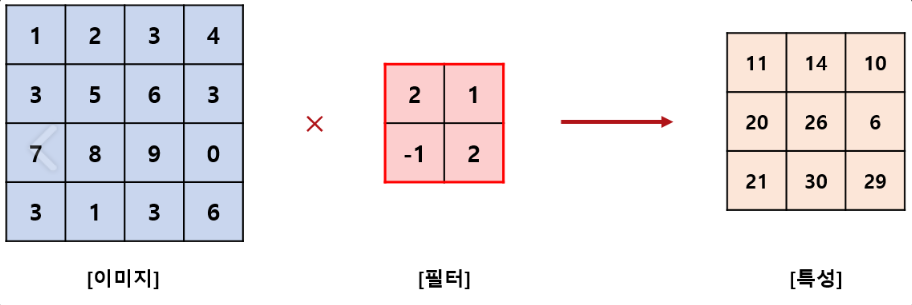
픽셀 값은 입력 값(input)이 되고, 필터 값은 가중치(weight)가 된다. 계산 방법은 이미지와 필터를 포개 놓고, 대응되는 숫자끼리 곱한 뒤, 모든 숫자를 더해주면 된다.
1-3 Pooling
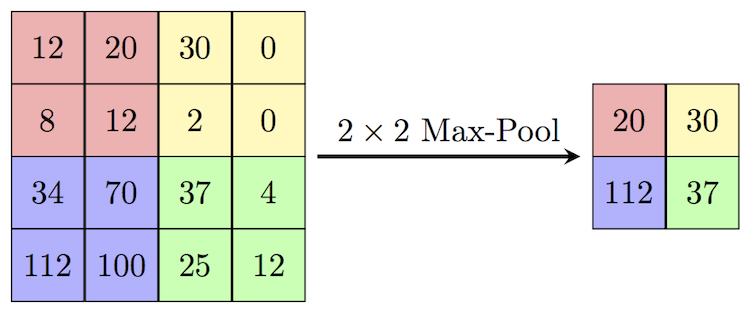
Pooling은 레이어의 크기를 축소시키는 작업을 의미한다. 더 쉽게 설명하자면 720p 화질의 이미지 정보를 가지고 있지만 크기를 줄여 360p의 변환하는 작업처럼 생각할 수 있다.
2. 실습
- 자료 : Lung CT data
- 입력 : 실제 폐 모양 이미지
- 출력 : 마스킹 된 폐 이미지
모델학습
Library Import
import numpy as np #행렬
import matplotlib.pyplot as plt #시각화
import tensorflow as tf #신경망
from keras.layers import Input, Activation, Conv2D, Flatten, Dense, MaxPooling2D, Dropout, Add, LeakyReLU, UpSampling2D
from keras.models import Model, load_model
from keras.callbacks import ReduceLROnPlateauData Load
x_train=np.load('dataset/x_train.npy')
y_train=np.load('dataset/y_train.npy')
x_val=np.load('dataset/x_val.npy')
y_val=np.load('dataset/y_val.npy')
train_dataset의 shape는 (240, 256, 256, 1)으로 data의 개수는 240개, 데이터 셋에 포함된 각각의 이미지는 행과 열이 각각 256 이며 4차원 배열임을 알 수 있다.
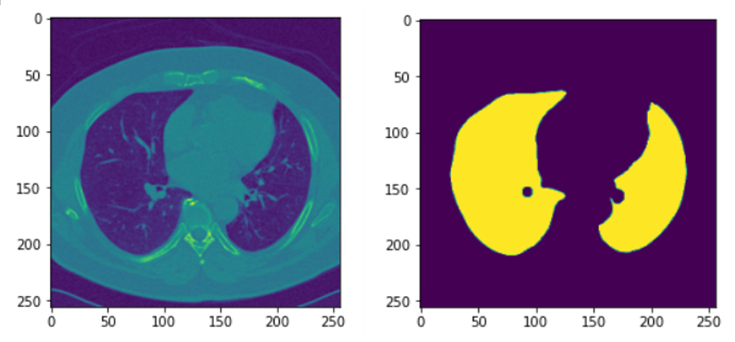
plt.imshow(x_train[0])
plt.show()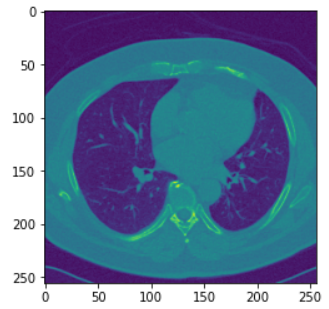
plt.imshow(y_train[0])
plt.show()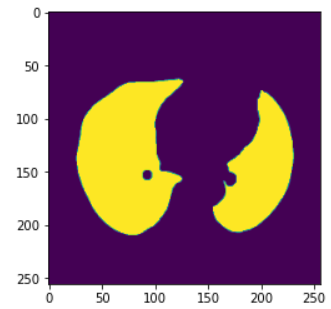
합성곱 신경망 구성
model = tf.keras.models.Sequential()
model.add(Conv2D(32, kernel_size=3, activation='relu', padding='same', input_shape = (256, 256, 1) ))
model.add(MaxPooling2D(pool_size=2, padding='same'))
model.add(Conv2D(64, kernel_size=3, activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=2, padding='same'))
model.add(Conv2D(128, kernel_size=3, activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=2, padding='same'))-
tf.keras.models 모듈의 Sequential 클래스를 사용해서 인공신경망의 각 층을 순서대로 쌓을 수 있음
-
add() 메서드를 이용해서 합성곱 층 Conv2D와 Max pooling 층 MaxPooling2D를 반복해서 구성하여 차원의 크기를 줄임
-
첫번째 Conv2D 층의 첫번째 parameter 32는 filters 값
- 합성곱 연산에서 사용되는 필터(filter)는 이미지에서 특징(feature)을 분리해내는 기능
- filters의 값은 합성곱에 사용되는 필터의 종류(개수)이며, 출력 공간의 차원(깊이)을 결정
-
활성화함수(Activation function)는 ‘relu’로 지정하고, 입력 데이터의 형태(input_shape)는 (256, 256, 1)로 설정
model.add(Dense(128, activation='relu'))- Dense 층(Fully-connected layer)을 추가하는 이유는 이미지가 픽셀의 위치에 민감하기 때문에 완전 연결을 해줌으로써 학습의 정확도를 높일 수 있기 때문이다.
model.add(UpSampling2D(size=2))
model.add(Conv2D(128, kernel_size=3, activation='sigmoid', padding='same'))
model.add(UpSampling2D(size=2))
model.add(Conv2D(64, kernel_size=3, activation='sigmoid', padding='same'))
model.add(UpSampling2D(size=2))
model.add(Conv2D(1, kernel_size=3, activation='sigmoid', padding='same'))- 차원의 크기를 다시 늘리기 위해 Upsampling2D와 Conv2D를 반복하여 구성
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc', 'mse'])
model.summary()- compile() 메서드를 이용하여 학습 방식에 대하여 설정함
- optimizer(최적화 알고리즘 설정)
- loss(손실함수)
- metric(평가지표)
- summary() 메서드를 이용해서 지금까지 구성한 신경망에 대한 정보를 출력할 수 있음
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 256, 256, 32) 320
max_pooling2d (MaxPooling2D (None, 128, 128, 32) 0
)
conv2d_1 (Conv2D) (None, 128, 128, 64) 18496
max_pooling2d_1 (MaxPooling (None, 64, 64, 64) 0
2D)
conv2d_2 (Conv2D) (None, 64, 64, 128) 73856
max_pooling2d_2 (MaxPooling (None, 32, 32, 128) 0
2D)
dense (Dense) (None, 32, 32, 128) 16512
up_sampling2d (UpSampling2D (None, 64, 64, 128) 0
)
conv2d_3 (Conv2D) (None, 64, 64, 128) 147584
up_sampling2d_1 (UpSampling (None, 128, 128, 128) 0
2D)
conv2d_4 (Conv2D) (None, 128, 128, 64) 73792
up_sampling2d_2 (UpSampling (None, 256, 256, 64) 0
2D)
conv2d_5 (Conv2D) (None, 256, 256, 1) 577
=================================================================
Total params: 331,137
Trainable params: 331,137
Non-trainable params: 0
_________________________________________________________________모델 훈련
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=10)Epoch 1/10
8/8 [==============================] - 142s 17s/step - loss: 0.5907 - acc: 0.7107 - mse: 0.1941 - val_loss: 0.5637 - val_acc: 0.7428 - val_mse: 0.1871
Epoch 2/10
8/8 [==============================] - 151s 18s/step - loss: 0.5250 - acc: 0.7605 - mse: 0.1718 - val_loss: 0.5156 - val_acc: 0.7450 - val_mse: 0.1701
Epoch 3/10
8/8 [==============================] - 152s 19s/step - loss: 0.4871 - acc: 0.7625 - mse: 0.1593 - val_loss: 0.4701 - val_acc: 0.7467 - val_mse: 0.1560
Epoch 4/10
8/8 [==============================] - 152s 19s/step - loss: 0.4445 - acc: 0.7627 - mse: 0.1462 - val_loss: 0.4260 - val_acc: 0.7467 - val_mse: 0.1396
Epoch 5/10
8/8 [==============================] - 145s 17s/step - loss: 0.4371 - acc: 0.7645 - mse: 0.1446 - val_loss: 0.4675 - val_acc: 0.7362 - val_mse: 0.1530
Epoch 6/10
8/8 [==============================] - 162s 20s/step - loss: 0.4267 - acc: 0.7609 - mse: 0.1404 - val_loss: 0.4148 - val_acc: 0.7519 - val_mse: 0.1396
Epoch 7/10
8/8 [==============================] - 162s 21s/step - loss: 0.3987 - acc: 0.7696 - mse: 0.1332 - val_loss: 0.3825 - val_acc: 0.7467 - val_mse: 0.1271
Epoch 8/10
8/8 [==============================] - 149s 18s/step - loss: 0.3471 - acc: 0.8105 - mse: 0.1137 - val_loss: 0.3657 - val_acc: 0.8057 - val_mse: 0.1198
Epoch 9/10
8/8 [==============================] - 148s 19s/step - loss: 0.3450 - acc: 0.8110 - mse: 0.1145 - val_loss: 0.3913 - val_acc: 0.7467 - val_mse: 0.1309
Epoch 10/10
8/8 [==============================] - 150s 19s/step - loss: 0.3130 - acc: 0.8305 - mse: 0.1026 - val_loss: 0.3200 - val_acc: 0.8409 - val_mse: 0.1034loss, acc 시각화
fig, ax = plt.subplots(2, 2, figsize=(10, 7))
# subplots는 한번에 여러 개의 그래프를 동시에 그려줌
ax[0, 0].set_title('loss')
ax[0, 0].plot(history.history['loss'], 'r')
ax[0, 1].set_title('acc')
ax[0, 1].plot(history.history['acc'], 'b')
ax[1, 0].set_title('val_loss')
ax[1, 0].plot(history.history['val_loss'], 'r--')
ax[1, 1].set_title('val_acc')
ax[1, 1].plot(history.history['val_acc'], 'b--')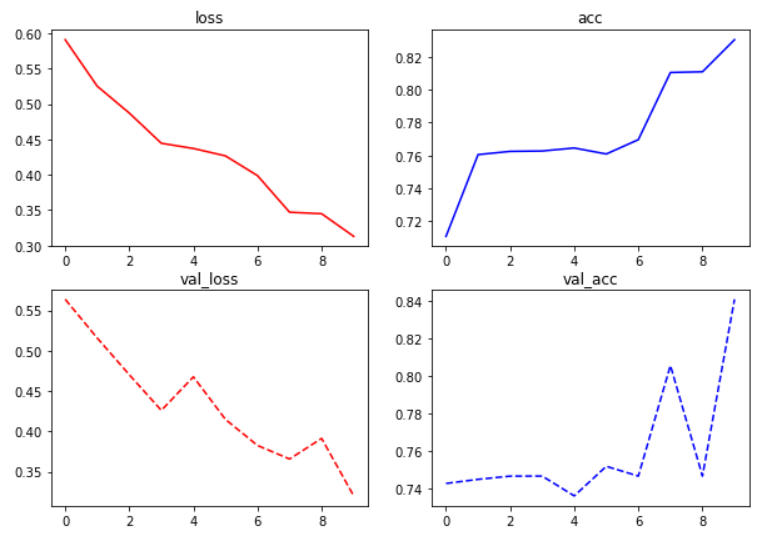
예측 모델
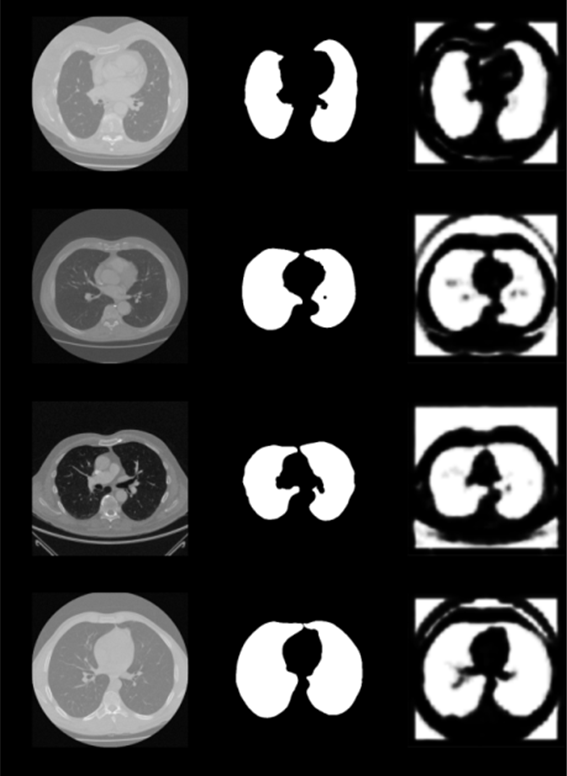
preds = model.predict(x_val)
fig, ax = plt.subplots(len(x_val), 3, figsize=(10, 100))
for i, pred in enumerate(preds):
ax[i, 0].imshow(x_val[i].squeeze(), cmap='gray')
ax[i, 1].imshow(y_val[i].squeeze(), cmap='gray')
ax[i, 2].imshow(pred.squeeze(), cmap='gray')- predict()를 이용하여 x_val을 검증
- 첫 번째엔 x_val, 두 번째엔 y_val, 세 번째엔 예측된 결과값이 나온다