
01-머신러닝 이해에 필요한 통계학적 핵심 개념
1-1. 머신러닝과 통계학

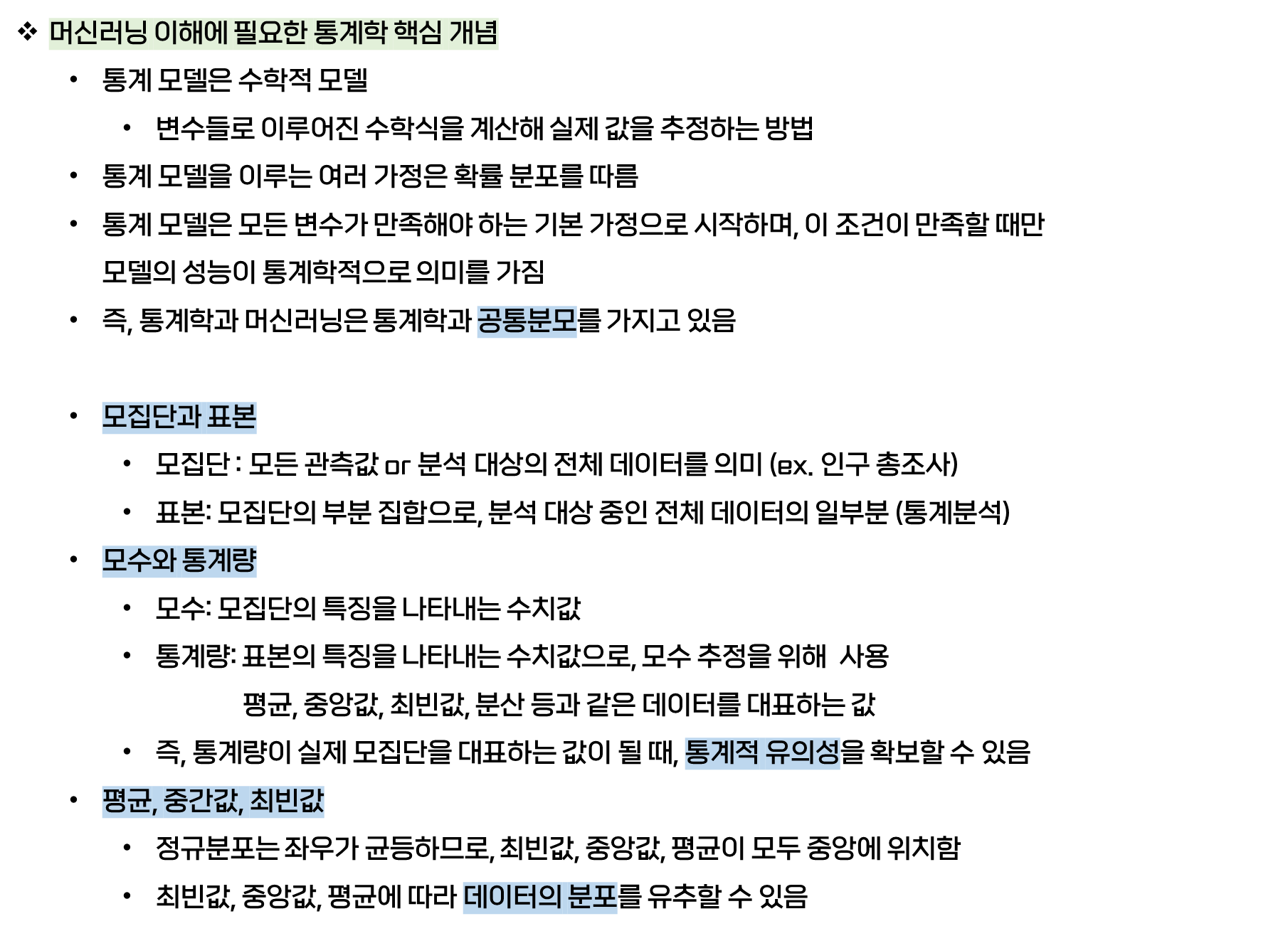
1-2. 모집단 vs. 모수와 통계량 vs. 평균, 중간값, 최빈값
1-3. 분산, 표준편차, 범위, 사분위수

# numpy는 최빈값과 관련된 함수를 제공하지 않으므로,
# scipy 패키지는 stats 모듈에 있는 mode 함수 사용
import numpy as np
from scipy import stats
np.random.seed(0)
data = np.random.randint(0, 100, 10000)
mean = np.mean(data); print("평균값: ", mean.round(2))
median = np.median(data); print("중앙값: ", median)
mode = stats.mode(data); print("최빈값: {} ({})".format(mode[0][0], mode[1][0]))
# 결과는 다음과 같음
# 평균값: 49.17
# 중앙값: 49.0
# 최빈값: 3 (125)# 분산과 표준편차, 범위, 사분위수
import numpy as np
from statistics import variance, stdev # 표준편차
np.random.seed(0)
points = np.random.randint(0, 100, 200)
var = variance(points); print("분산: ", var)
std = stdev(points); print("표준편차 : ", np.round(std, 2))
range = np.max(points) - np.min(points); print("범위: ", range)
print("사분위 수: ")
for val in [0, 25, 50, 75, 100]:
quantile = np.percentile(points, val)
print("{}% => {}".format(val, quantile))
q1, q3 = np.percentile(points, [25, 75])
print("IQR: ", q3 - q1)
# 결과는 다음과 같음
# 분산: 821
# 표준편차 : 28.65
# 범위: 99
# 사분위 수:
# 0% => 0.0
# 25% => 24.0
# 50% => 48.0
# 75% => 72.25
# 100% => 99.0
# IQR: 48.25
best of best