
01-머신러닝 이해에 필요한 통계학적 핵심 개념-통계적 추론
1-1. p-value, 카이제곱 독립성 검정

1-2. ANOVA 분산 분석

1-3. 머신러닝 통계학 내용 정리

# 문제1) 한 빵집에서 생산되는 식빵의 무게가 최소 200g이라고 주장할 경우,
# 표본 20개를 추출해 구한 평균 무게가 196g이고, 표준편차는 5.3g이었다면,
# 유의수준 5%(0.05)로 위의 주장을 기각할 수 있을까?
import numpy as np
from scipy import stats
x_bar, mu, sigma, n = 196, 200, 5.3, 20
t_sample = (x_bar - mu) / (sigma / np.sqrt(float(n)))
print("검정 통계량: ", np.round(t_sample, 2))
alpha = 0.05
t_alpha = stats.t.ppf(alpha, n-1)
print("t-table로 부터의 임계값: ", np.round(t_alpha, 3))
p_val = stats.t.sf(np.abs(t_sample), n-1)
print("t-table의 아래쪽 꼬리 p 값: ", np.round(p_val, 4))
# 결과 값은 다음과 같음
# 검정 통계량: -3.38
# t-table로 부터의 임계값: -1.729
# t-table의 아래쪽 꼬리 p 값: 0.0016# 문제2) 시험 점수가 정규분포를 따른다고 가정할 경우, 평균 점수가 56점이고,
# 표준편차가 13.6인 경우, 75점 이상을 받은 학생들은 몇 % 일까?
import numpy as np
from scipy import stats
x, mu, sigma = 75, 56, 13.6
z = (x - mu) / sigma
print("z-score: ", np.round(z, 2)) # 누적확률분포함수는 표준화되어 있으므로 z-score 사용
p_val = 1 - stats.norm.cdf(z)
print("학생이 {}점 이상 받을 확률: {}%".format(x, np.round(p_val*100, 2)))
# 결과 값은 다음과 같음
# z-score: 1.4
# 학생이 75점 이상 받을 확률: 8.12%# 카이제곱 독립성 검정:
# 흡연이 운동에 영향을 미칠까?
import numpy as np
import pandas as pd
from scipy import stats
np.random.seed(0)
smoke = ["안함", "가끔", "매일", "심함"]
exercise = ["안함", "가끔", "매일"]
data = {"smoke": np.random.choice(smoke, size=500),
"exercise": np.random.choice(exercise, size=500)}
df = pd.DataFrame(data, columns=["smoke", "exercise"])
df.head()
# pandas 함수를 이용해 독립성 검정 분할표(=빈도표) 만들기
xtab = pd.crosstab(df.smoke, df.exercise)
xtab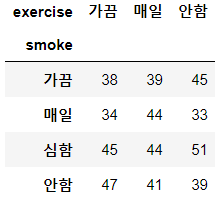
contg = stats.chi2_contingency(observed=xtab)
p_val = np.round(contg[1], 3)
print("p값: ", p_val)
# 결과 값은 다음과 같음
# p값: 0.668 --> p값이 0.05보다 크기 때문에, 흡연과 운동의 상관관계 없음# ANOVA 분산 분석
# 10명의 환자를 대상으로 A, B, C 3가지 수면제 약효(수면시간)를 각각 테스트 할 경우,
# 유의수준 0.05에서 A, B, C 수면제의 평균 수면시간은 동일한가?
import numpy as np
import pandas as pd
from scipy import stats
np.random.seed(0)
data = (np.random.rand(30).round(2) * 10).reshape(-1, 3)
df = pd.DataFrame(data, columns=["A", "B", "C"])
df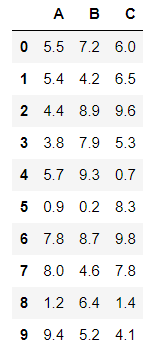
# 분산분석은 f 분포를 따르는 f 통계량 사용, ANOVA(F 검정)
# 일원분산분석 : oneway / 이원분산분석 : twoway
one_way_anova = stats.f_oneway(df.A, df.B, df.C)
print("통계량: {}, p-value: {}".format(np.round(one_way_anova[0], 2),
np.round(one_way_anova[1], 3)))
# 결과 값은 다음과 같음
# 통계량: 0.34, p-value: 0.713 --> p 값이 0.713으로 귀무가설 채택 (3개의 수면제 약효 평균이 동일함)
best of best