기본 import문
import numpy as np
import pandas as pd
np.random.seed(12345)
import matplotlib.pyplot as plt
plt.rc('figure', figsize=(10, 6))
np.set_printoptions(precision=4, suppress=True)💡 CSV를 DataFrame으로 읽기
- examples/ex1.csv 파일 내용
a,b,c,d,message
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo
- 기본
df = pd.read_csv('examples/ex1.csv')
#read_table은 구분자 지정
#pd.read_table('examples/ex1.csv', sep=',') 위랑 결과 동일.
df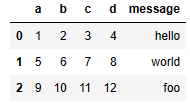
- 표 내용이 열이 되지 않도록
pd.read_csv('examples/ex2.csv', header=None)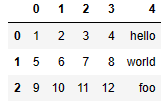
- 열(col) 지정해서 읽기
pd.read_csv('examples/ex2.csv', names=['a', 'b', 'c', 'd', 'message'])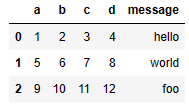
- 열(col) 지정하고, 행(index)이 될 열(col) 지정
# index_col 옵션: index column 지정
names = ['a', 'b', 'c', 'd', 'message']
pd.read_csv('examples/ex2.csv', names=names, index_col='message')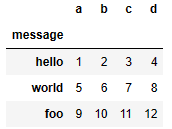
- examples/csv_mindex.csv 내용
- csv 내용 일부의 열(col)을 행(index)으로
key1,key2,value1,value2
one,a,1,2
one,b,3,4
one,c,5,6
one,d,7,8
two,a,9,10
two,b,11,12
two,c,13,14
two,d,15,16
parsed = pd.read_csv('examples/csv_mindex.csv',
index_col=['key1', 'key2'])
- csv가 field를 구분하는 특정 구분자(delimeter)가 없는 경우
- delimiter로 정규표현식 사용
list(open('examples/ex3.txt'))[' A B C\n',
'aaa -0.264438 -1.026059 -0.619500\n',
'bbb 0.927272 0.302904 -0.032399\n',
'ccc -0.264273 -0.386314 -0.217601\n',
'ddd -0.871858 -0.348382 1.100491\n']
# 행의 데이터 갯수보다 한개 적은 column name을 가진 경우, 첫번째 열을 index
result = pd.read_table('examples/ex3.txt', sep='\s+')
result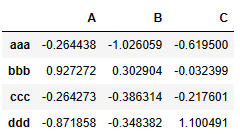
- 특정 행(row) skip해서 df로
list(open('examples/ex4.csv'))['# hey!\n',
'a,b,c,d,message\n',
'# just wanted to make things more difficult for you\n',
'# who reads CSV files with computers, anyway?\n',
'1,2,3,4,hello\n',
'5,6,7,8,world\n',
'9,10,11,12,foo']
#skip할 행의 인덱스 순서번호를 삽입
result = pd.read_csv('examples/ex4.csv', skiprows=[0, 2, 3])
result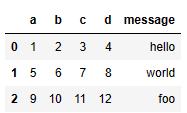
- Empty string or NaN 부분을 true로 나오게
result = pd.read_csv('examples/ex5.csv')
result
pd.isnull(result)- Empty string or NaN 부분을 'NaN'으로 나오게
result = pd.read_csv('examples/ex5.csv', na_values=['NULL'])
result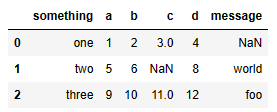
- 'NaN'으로 만들 데이터를 지정
sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
pd.read_csv('examples/ex5.csv', na_values=sentinels)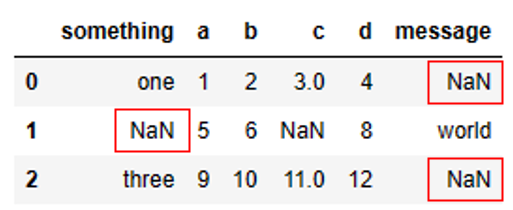
💡 csv 파일의 일부만 읽기
- 화면에 출력될 행의 수 지정
pd.options.display.max_rows = 10 #10개의 행만 출력
result = pd.read_csv('examples/ex6.csv')- 읽을 행의 수 지정 (nrows)
pd.read_csv('examples/ex6.csv', nrows=5) #5개 행만 읽음.chunker = pd.read_csv('examples/ex6.csv', chunksize=1000)- chunk로 행 몇 개를 읽고 특정 열(col) 데이터 빈도 계산
# 1000줄 읽은 chunker에서 'key'열 값의 빈도 계산
chunker = pd.read_csv('examples/ex6.csv', chunksize=1000)
tot = pd.Series([])
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
# 빈도 순으로 내림차순 정렬
tot = tot.sort_values(ascending=False)
tot[:10]💡 df에서 csv(text)로
data = pd.read_csv('examples/ex5.csv')
data.to_csv('examples/out.csv') #table을 csv의 text 형태로
list(open('examples/out.csv'))[',something,a,b,c,d,message\n',
'0,one,1,2,3.0,4,\n',
'1,two,5,6,,8,world\n',
'2,three,9,10,11.0,12,foo\n']
- df를 구분자 '|'로 해서 csv로 출력
import sys
data.to_csv(sys.stdout, sep='|')|something|a|b|c|d|message
0|one|1|2|3.0|4|
1|two|5|6||8|world
2|three|9|10|11.0|12|foo
- NaN 값을 특정 값으로 처리
data.to_csv(sys.stdout, na_rep='NULL'),something,a,b,c,d,message
0,one,1,2,3.0,4,NULL
1,two,5,6,NULL,8,world
2,three,9,10,11.0,12,foo
- row의 index와 column의 label 출력 안되게
data.to_csv(sys.stdout, index=False, header=False)one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo
- column의 일부만 출력(지정된 순서)
data.to_csv(sys.stdout, index=False, columns=['a', 'b', 'c']) #index는 안 보이게a, b, c
1, 2, 3.0
5, 6,
9, 0, 1.0
- 특정 날짜부터 n days 출력
dates = pd.date_range('1/1/2000', periods=7) #총 7days 출력
datesDatetimeIndex(['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04',
'2000-01-05', '2000-01-06', '2000-01-07'],
dtype='datetime64[ns]', freq='D')
ts = pd.Series(np.arange(7), index=dates) #위 출력한 날짜를 인덱스로
ts
#ts.to_csv('examples/tseries.csv') csv 파일로 변경2000-01-01 0
2000-01-02 1
2000-01-03 2
2000-01-04 3
2000-01-05 4
2000-01-06 5
2000-01-07 6
💡 형식이 잘못된 파일 읽기
- 표 형식의 data는 pandas.read_table로 읽음
- 형식이 잘못된 파일 읽기 => python의 csv module 사용
['"a","b","c"\n', '"1","2","3"\n', '"1","2","3"\n']
import csv
f = open('examples/ex7.csv')
reader = csv.reader(f)
for line in reader:
print(line)['a', 'b', 'c']
['1', '2', '3']
['1', '2', '3']
