1. Elastic-Search란
-
Apache Lucene 기반의 java 오픈소스 분산 검색 엔진
-
데이터를 신속하게 저장, 검색, 분석을 수행하는 역할
-
역색인 구조로 대용량 데이터를 빠르게 처리 가능
-
기존 관계 데이터베이스 시스템에서는 다루기 어려운 전문검색(Full Text Search) 기능과 점수 기반의 다양한 정확도 알고리즘 가능
2. Elastic-Search 용어
-
클레스터(cluster)
여러 개의 ElasticSearch가 마치 하나의 구성 요소처럼 사용할 수 있게 하는 기술 -
노드
클러스터를 구성하는 하나의 인스턴스
여러개의 노드들이 모여 하나의 클러스터를 이룸 -
인덱스(index)
문서의 모음을 유지하는 논리적 네임스페이스이며, 각 문서는 필드의 모음이고, 필드는 데이터를 포함하는 키-값 쌍
RDBMS의 테이블과 유사 -
샤드(shard)
고유한 인덱스의 하위 집합으로, 데이터를 물리적으로 저장하는 기본 단위
인덱스는 샤드 단위로 분산하여 저장
보통 샤드 크기를 최소 몇 GB에서 수십 GB 사이로 유지하는 것을 권장 -
레플리카 샤드(Replica shard)
Elasticsearch의 데이터 보호와 가용성을 높이는 중요한 구성 요소
데이터 가용성 및 장애 복구, 읽기 성능 향상 -
문서(document)
Elastic Search에서 데이터의 기본 단위
JSON의 형식으로 저장, 구조화된 데이터를 표현하는 하나의 entity -
색인(indexing)
문서를 분석하고 그것을 Storage에 저장하는 이러한 일련의 과정
미리 설정해둔 샤드와 레플리카의 경우 재색인을 하지 않는 이상 변경 불가능
3. 색인의 과정
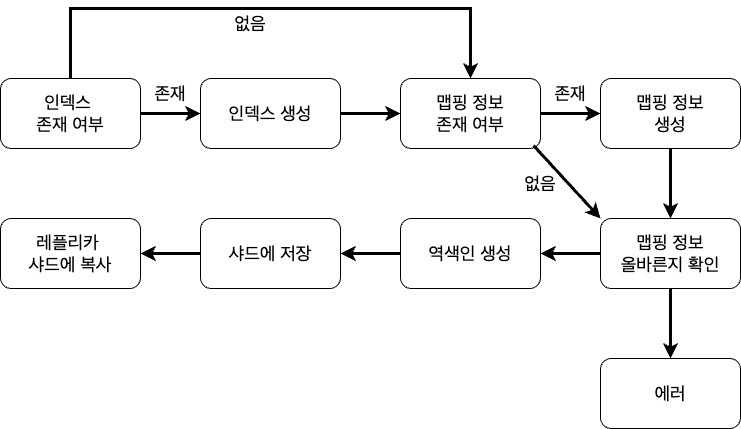
데이터가 색인이 진행되는 과정입니다.
4. 역색인이란
-
키워드를 통해 문서를 찾아내는 방식
-
책의 뒤에 부록을 생각하면 이해하기 편함
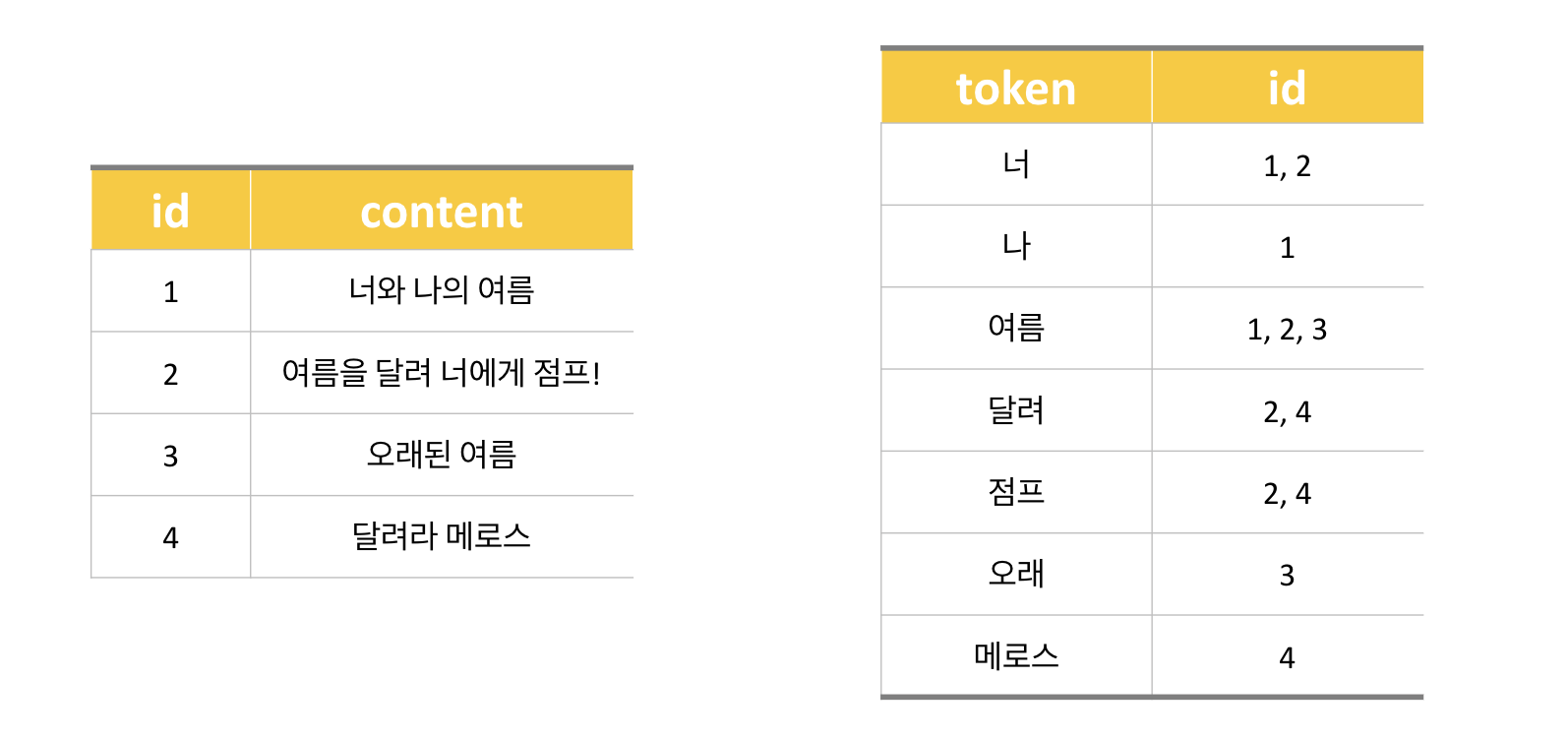
"너와 나의 여름"이란 content를 저장한다고 가정하면 token로 나누어 너, 나, 여름으로 나뉜다. 그 토큰을 키 값으로 저장한다.
그렇게 다른 문장들을 다 저장한 후 여름을 검색하면 그 안에 있는 값인 1, 2, 3이 나온다.
역색인 구조라 대용량 데이터를 사용할 때에도 속도가 빠르다
5. 왜 Elastic Search 선택하는 가?
기존 RDBMS 대신 Elastic Search를 사용하는가?
-
Full Text Search
RDBMS도 ngram을 사용하여 Full Text Search를 사용할 수는 있지만 Elastic Search의 경우 형태소 분석등으로 더 다양한 분석기를 지원해준다. -
동의어와 유의어
Elastic Search의 경우 동의어와 유의어를 추가하여 사용할 수 있다. -
비정형 데이터의 색인과 검색이 가능
JSON 형식으로 되어있어 확장성이 더 유용하다. -
역색인 지원으로 RDBMS보다 더 빠른 검색이 가능하다.
이러한 이유로 저는 프로젝트에서 Mysql과 Elastic Search를 함께 사용하였습니다.
