분석기(Analyzer)란
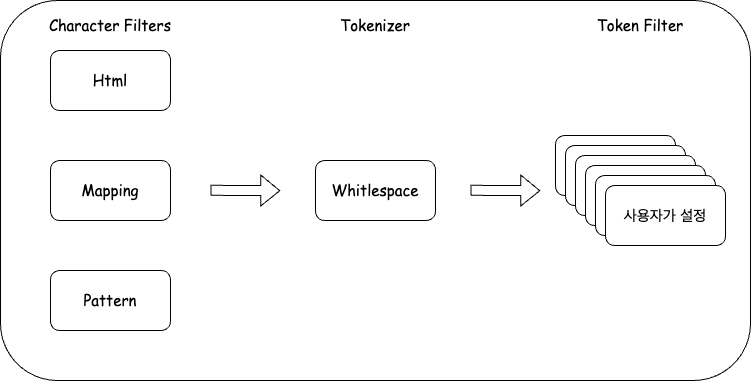
Elastic Search는 문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위해 여러 단계의 처리 과정을 거칩니다. 이 전체 과정을 텍스트 분석(Text Analysis) 이라고 하고 이 과정을 처리하는 기능을 분석기(Analyzer) 라고 합니다.
Analyer 는 크게 Char Filters, Tokenizer, Token Filters 로 나뉩니다.
Char Filter란
보통 0~3개 정도의 char Filter가 적용 가능합니다.
텍스트 데이터가 입력되면 가장 먼저 필요에 따라 전체 문장에서 특정 문자를 대치하거나 제거하는데 이 과정을 담당하는 기능이 캐릭터 필터입니다
한 문장이 들어왔을 때 각 문자의 필터 역할을 하며 추가, 삭제, 변경이 할 수 있으며 매핑이나 html 태그 필터, 사용자가 직접 custom 하여 맞춤 char_filter, Patter_filter의 기능이 있습니다.
1. Html_strip Filter
html 태그 안에 있는 값을 가져온다.
POST _analyze
{
"tokenizer": "keyword",
"char_filter": [
"html_strip"
],
"text": "<p><b>Hello World</b>!</p>"
}
결과
{
"tokens": [
{
"token": """
Hello World!
""",
"start_offset": 0,
"end_offset": 26,
"type": "word",
"position": 0
}
]
}2. Mapping Filter
Mapping 캐릭터 필터를 이용하면 지정한 단어를 다른 단어로 치환이 가능합니다.
보통 특수문자나 해당 문자를 대치하거나 제거할 때 사용
POST _analyze
{
"tokenizer": "standard",
"text": "A+ 비결"
}결과
{
"tokens": [
{
"token": "A",
"start_offset": 0,
"end_offset": 1,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "비결",
"start_offset": 3,
"end_offset": 5,
"type": "<HANGUL>",
"position": 1
}
]
}A+이 A로 저장되는 문제가 발생한다. 그래서 +를 plus 형식으로 저장
PUT test_index
{
"settings": {
"analysis": {
"analyzer": {
"test_analyzer": {
"char_filter": [
"plus_char_filter"
],
"tokenizer": "whitespace",
"filter": ["stop", "snowball" ]
}
},
"char_filter": {
"plus_char_filter": {
"type": "mapping",
"mappings": [ "+ => _plus_" ]
}
}
}
},
"mappings": {
"properties": {
"language": {
"type": "text",
"analyzer": "test_analyzer"
}
}
}
}test_index를 생성하고 mapping을 활용
GET test_index/_analyze
{
"analyzer" : "test_analyzer",
"text" : "A+ 비결"
}결과
{
"tokens": [
{
"token": "A_plus_",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "비결",
"start_offset": 6,
"end_offset": 8,
"type": "word",
"position": 2
}
]
}A에서 Aplus로 변경되어 분석한다.
3. Pattern Filter
정규식을 이용해서 복잡한 패턴들을 치환할 수 있는 캐릭터 필터
PUT /email_index
{
"settings": {
"analysis": {
"filter": {
"email_filter": {
"type": "pattern_capture",
"preserve_original": false,
"patterns": ["([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,6})"]
}
},
"analyzer": {
"email_analyzer": {
"tokenizer": "uax_url_email",
"filter": ["lowercase", "email_filter"]
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "email_analyzer"
}
}
}
}email 형식으로 저장하는 patter filter를 적용하였습니다.
GET _analyze
{
"analyzer" : "standard",
"text" : "support@example.com"
}기존 방식으로 하면 결과는 support, example.com으로 두개로 나눠 저장 됩니다.
GET email_index/_analyze
{
"analyzer" : "email_analyzer",
"text" : "support@example.com"
}patter필터로 분석하면 support@example.com으로 하나로 저장 됩니다.
