📝 A Survey on Transfer Learning
Abstract
-
지식 전이가 성공적으로 이루어진다면 많은 비용이 드는 데이터 라벨링 작업 없이도 학습 성능을 크게 향상시킬 수 있음
-
이 논문에서 분류, 회귀, 군집 문제에 대한 전이 학습의 현재 진행 상황을 분류하고 검토함
-
전이 학습과 도메인 적응, 다중 작업 학습 등의 관련 머신러닝 기술과의 관계에 대해서도 논의함
1 Introduction
-
학습 데이터와 테스트 데이터가 동일한 특성 공간과 동일한 분포로부터 추출되지 않으면 성공하기 어려움
-
분포가 바뀌게 되면, 대부분의 통계 모델들은 새로 수집한 학습 데이터를 이용하여 처음부터 다시 구축해야 함
-> 실제 환경에서는 필요한 학습 데이터를 다시 수집하거나 모델을 재구축하는 것이 비용이 많이 들거나 불가능할 수 있음
-> 결론적으로 학습 데이터를 재수집하는 필요성과 노력을 줄이는 것이 바람직함
-> 작업 도메인 간에 지식을 전이하거나 전이 학습을 수행하는 것이 유용할 수 있음
-
웹 문서 분류, 구식 데이터, 감성 분류 문제와 같은 경우에
전이 학습이 진정으로 도움이 될 수 있는 지식 공학의 많은 예시들이 존재함
2 Overview
2.1 A Brief History of Transfer Learning
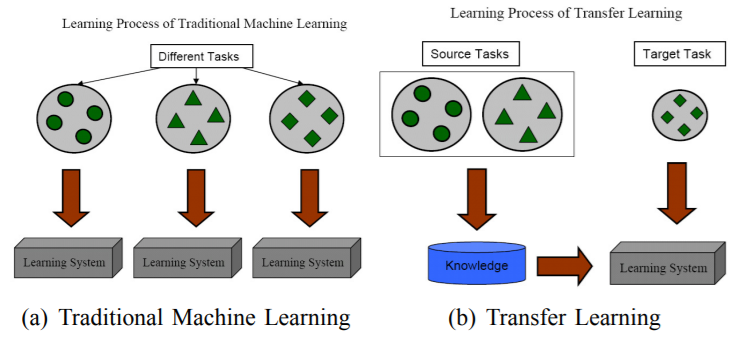 전통적인 머신 러닝 기법과 전이 학습 기법 간의 학습 과정 차이
전통적인 머신 러닝 기법과 전이 학습 기법 간의 학습 과정 차이
(이미지에 대한 설명)
-
전통적인 데이터 마이닝 및 머신 러닝 알고리즘은 과거에 수집된 라벨링 또는 비라벨링 학습 데이터를 기반으로 통계 모델을 학습하여 미래 데이터를 예측함
-
전이 학습 연구는 사람이 과거에 학습한 지식을 지능적으로 적용하여 새로운 문제를 더 빠르거나 더 나은 방식으로 해결할 수 있음
2.2 Notations and Definitions
-
도메인(데이터가 있는 세상, 환경) D의 두 가지 구성 요소:
-
특성 공간 (어떤 형식의 데이터인지)
-
주변 확률 분포 (어떤 데이터가 얼마나 자주 나오는지)
-
-
태스크(무엇을 예측할 건지)의 두 가지 구성 요소:
-
레이블 공간 : 정답의 종류들 (예: 긍정/부정)
-
예측 함수 f(x): 데이터 를 보고 정답 예측
-
2.3 A Categorization of Transfer Learning Techniques
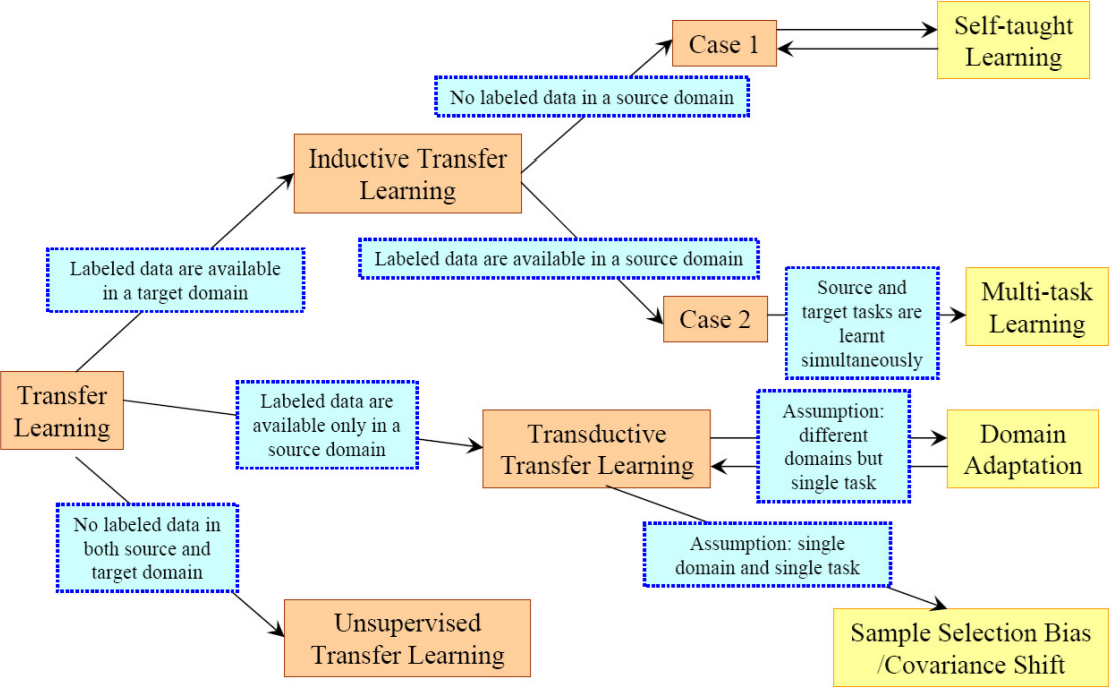 전이 학습의 분류 체계를 조건별로 나눈 흐름도
전이 학습의 분류 체계를 조건별로 나눈 흐름도
-
전이 학습의 세 가지 주요 연구 문제:
1. 무엇을 전이할 것인가?
- 어떤 지식이 도메인이나 태스크 간에 전이될 수 있는지를 물음
2. 어떻게 전이할 것인가?
- 어떤 상황에서 전이 학습을 적용해야 하는지를 물음
- 부정적 전이(negative transfer): 소스 도메인과 타겟 도메인이 충분히 관련이 없는 경우, 무리하게 지식을 전이하면 오히려 성능이 저하됨
3. 언제 전이할 것인가?
- (향후 중요한 연구 주제로 주목받고 있음)
-
상황에 따른 전이 학습의 세 가지 하위 설정:
1. 유도 전이 학습(Inductive Transfer Learning)
- 타겟 태스크가 소스 태스크와 다름
- 타겟 도메인에 일부 라벨된 데이터가 존재해야 함
2. 전달 전이 학습(Transductive Transfer Learning)
- 소스 & 타겟 태스크는 동일, 도메인은 다름
- 타겟 도메인에 라벨이 없음, 소스 도메인에는 있음
3. 비지도 전이 학습(Unsupervised Transfer Learning)
- 태스크는 다르지만 관련 있음
- 타겟 도메인은 비지도 학습 문제 (예: 클러스터링, 차원 축소 등)
- 소스와 타겟 모두 라벨 없음
3 INDUCTIVE TRANSFER LEARNING
3.1 Transferring Knowledge of Instances
- 소스 도메인의 데이터를 그대로 재사용할 수는 없지만, 일부 데이터는 타겟 도메인의 라벨이 지정된 데이터와 함께 여전히 재사용이 가능함
3.2 Transferring Knowledge of Feature Representations
-
특성 표현 전이 접근법은 도메인 간의 차이를 최소화하고 분류 또는 회귀 모델 오류를 줄이는 좋은 특성 표현을 찾는 것을 목표로 함
-
소스 도메인에 라벨이 지정된 데이터가 많을 경우, 지도 학습 방법을 사용하여 특성 표현을 구성할 수 있음
-
소스 도메인에 라벨이 지정된 데이터가 없을 경우, 비지도 학습 방법을 통해 특성 표현을 구성하는 방법이 제안됨
3.3 Transferring Knowledge of Parameters
-
파라미터 전이는 소스와 타겟 과제의 모델 파라미터 간의 공유 또는 정규화를 통해 지식을 전이함
-
주로 다중 과제 학습 프레임워크에서, 파라미터를 공동으로 학습하거나
관련 구조를 강제하는 방식으로 활용됨 -
이 접근법은 과제 간 유사성이 높을수록 효과적이며, 파라미터 간의 구조적 관계를 정형화할 수 있는 경우에 유리함
3.4 Transferring Relational Knowledge
-
관계 전이는 데이터 인스턴스 간의 구조적 관계나 규칙을 통해 지식을 전이함
-
주로 관계적 학습이나 통계적 관계학습에서 사용되며, 예를 들어 링크 구조를 공유하거나 규칙 기반 표현을 활용함
-
소스 도메인의 관계 패턴을 학습한 후, 이를 타겟 도메인의 구조 학습에 활용할 수 있음
4 TRANSDUCTIVE TRANSFER LEARNING
4.1 Transferring the Knowledge of Instances
-
출처 도메인 데이터와 대상 도메인 데이터의 분포가 다를 경우, 그냥 모델을 학습하면 잘 맞지 않음
-
그래서 출처 데이터를 얼마나 대상 데이터와 비슷한가에 따라 가중치를 다르게 줌
-
이 비율을 계산하기 위해 확률 밀도나 커널 방법을 사용함
-
출처 데이터를 대상 도메인에 잘 맞게 조정해서 쓰는 것이 전략
4.2 Transferring Knowledge of Feature Representations
-
출처와 대상 도메인이 다를 때도 공통으로 잘 작동하는 특성을 찾아냄
-
이 특성을 중심으로 새롭게 특성 공간을 재구성해서 도메인 간 차이를 줄임
-
출처와 대상 도메인 두 가지를 잘 설명할 수 있는 새로운 특성 공간을 만드는 것이 목표
5 UNSUPERVISED TRANSFER LEARNING
5.1 Transferring Knowledge of Feature Representations
-
비지도 전이 학습의 한 예인 Self-taught clustering(STC)이라 불리는 새로운 유형의 군집화 문제를 연구함
-
출처 도메인에 있는 다량의 비라벨 데이터의 도움을 받아서 대상 도메인의 소량 비라벨 데이터를 군집화하는 것을 목표로 함
-
STC는 도메인 간 공통 특성 공간을 학습하여 대상 도메인에서의 군집화에 도움이 되도록 함
6 TRANSFER BOUNDS AND NEGATIVE TRANSFER
-
부정적 전이는 출처 도메인의 데이터와 과제가 대상 도메인에서의
학습 성능을 저하시킬 때 발생함 -
두 과제가 너무 다르면, 무작정 전이를 시도하는 것이 대상 과제의 성능을 저하시킬 수 있음을 실험적으로 보여줌
8 CONCLUSIONS
-
전이 학습은 유도 전이 학습, 전이 추론, 비지도 전이 학습 세 가지 서로 다른 설정으로 분류됨
-
전이 학습에 대한 접근 방식들은 학습에서 무엇을 전이할 것인가에 기반하여 네 가지 맥락으로 분류됨
-
인스턴스 전이 접근법
-
특성 표현 전이 접근법
-
파라미터 전이 접근법
-
관계 지식 전이 접근법
-
-
부정적 전이를 어떻게 피할 것인가에 대한 문제를 향후 해결해야 됨
