논문 정리
1.[XGBoost: A Scalable Tree Boosting System] 논문 정리

📝 XGBoost: A Scalable Tree Boosting Systemtree boosting은 머신러닝에서 효율적이고 널리 쓰임XGBoost라는 최첨단 결과를 이끌어내기 위해 많은 데이터 사이언티스트들이 사용함XGBoost는 기존 시스템보다 휠씬 적은 리소스를
2.[CatBoost: unbiased boosting with categorical features] 논문 정리
MathJax.Hub.Config({ tex2jax: {inlineMath: [['$', '$'], ['\\(', '\\)']]}, displayAlign: "center" }); 1 Introduction Gradient boosting은 다양한 실용적인
3.[LightGBM: A Highly Efficient Gradient Boosting Decision Tree] 논문 정리
MathJax.Hub.Config({ tex2jax: {inlineMath: [['$', '$'], ['\\(', '\\)']]}, displayAlign: "center" }); 📝 [LightGBM: A Highly Efficient Gradient B
4.[Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift] 논문 정리
📝 Batch Normalization: Accelerating Deep Network Training by ReducingInternal Covariate Shift내부 공변량 변화(Internal Covariate Shift)각 레이어의 입력 분포가 이전 레이어의
5.[Dropout: A Simple Way to Prevent Neural Networks from Overfitting] 논문 정리
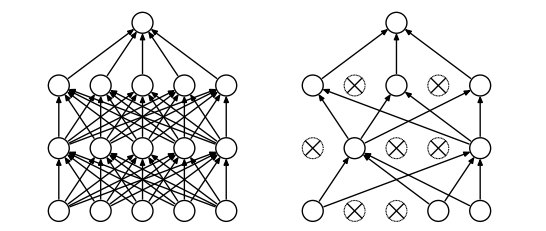
📝 Dropout: A Simple Way to Prevent Neural Networks from Overfitting내부 공변량 변화(Internal Covariate Shift)각 레이어의 입력 분포가 이전 레이어의 파라미터 변화에 따라 지속적으로 변하는 문제가
6.[Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling] 논문 정리
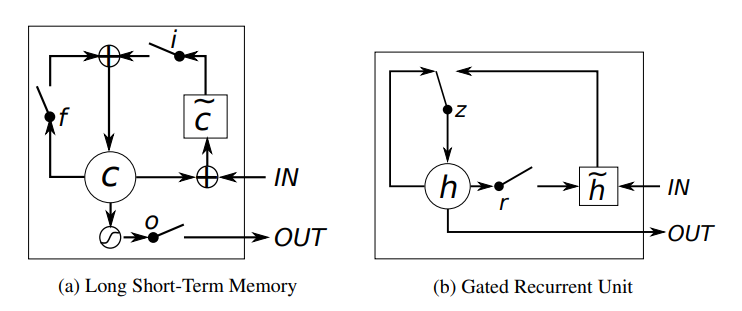
📝 Batch Normalization: Accelerating Deep Network Training by ReducingInternal Covariate Shift내부 공변량 변화(Internal Covariate Shift)각 레이어의 입력 분포가 이전 레이어의
7.[Learning Internal Representations by Error Propagation] 논문 정리
📝 Learning Internal Representations by Error Propagation딥러닝에서 과적합이 문제되는 대형 신경망을 효율적으로 학습시키기 위해 드롭아웃(Dropout) 기법을 제안훈련 중에 뉴런과 연결을 랜덤하게 제거하여 과적합을 방지하고,
8.[Distributed Representations of Sentences and Documents] 논문 정리
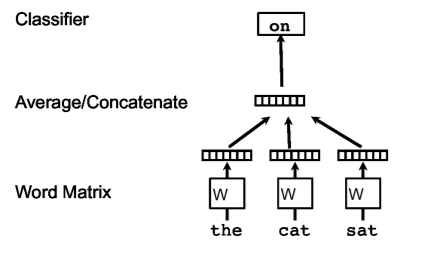
📝 Learning Internal Representations by Error Propagation신경망의 학습은 입력과 출력 간의 관계를 모델링하는 데 중점을 둠기존의 학습 방법은 단층 신경망에 제한적이며, 복잡한 패턴 인식에 한계가 있음다층 신경망의 효과적인 학
9.[Efficient Estimation of Word Representations in Vector Space] 논문 정리
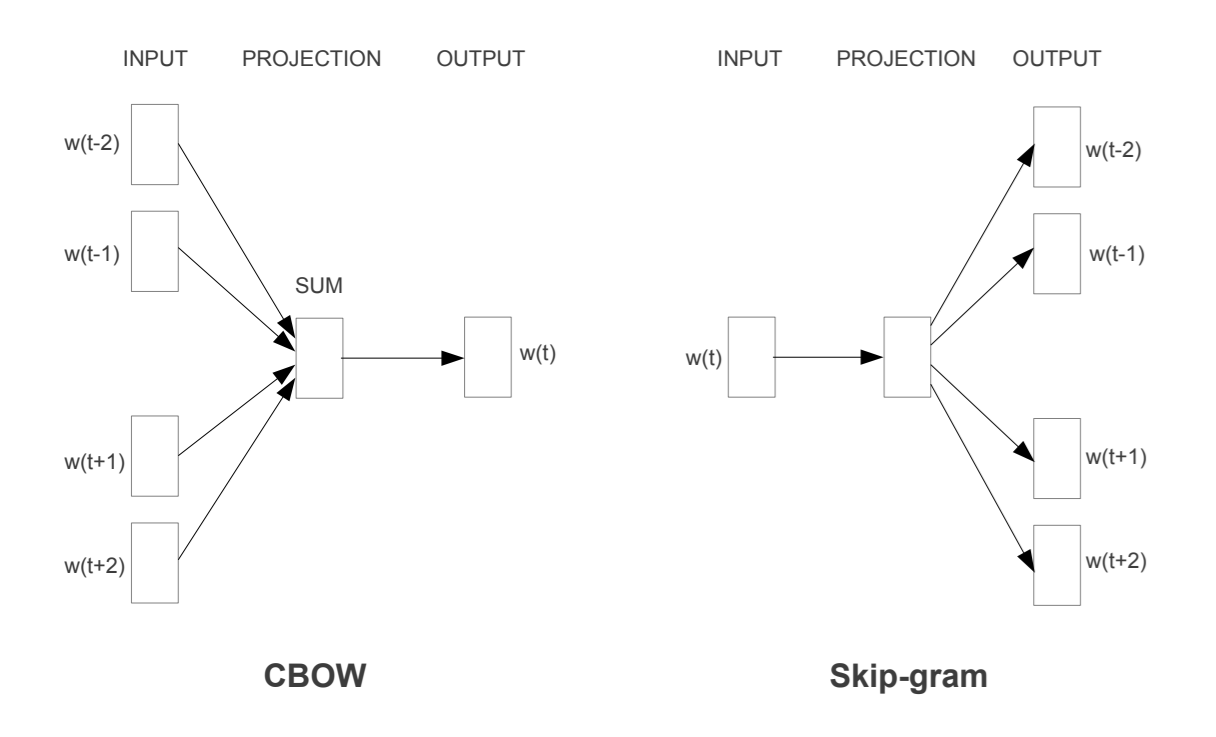
📝 Distributed Representations of Sentences and Documents머신러닝에서 고정 길이 특징 벡터가 필요하지만, 기존 Bag-of-Words는 단어 순서와 의미를 무시하는 단점이 있음이를 해결하기 위해 문서별 밀집 벡터를 학습하는
10.[BLEU: a Method for Automatic Evaluation of Machine Translation] 논문 정리
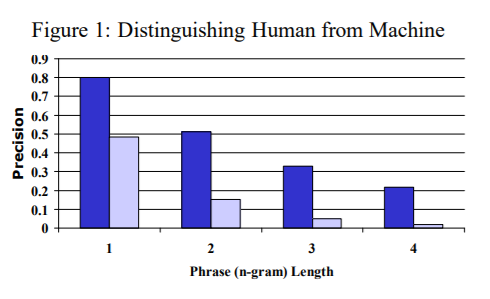
📝 Distributed Representations of Sentences and Documents머신러닝에서 고정 길이 특징 벡터가 필요하지만, 기존 Bag-of-Words는 단어 순서와 의미를 무시하는 단점이 있음이를 해결하기 위해 문서별 밀집 벡터를 학습하는
11.[Sequence to Sequence Learning with Neural Networks] 논문 정리
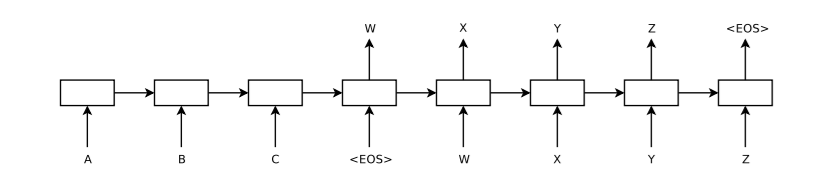
📝 BLEU: a Method for Automatic Evaluation of Machine Translation딥 뉴럴 네트워크(DNN)는 복잡한 학습 문제에서도 뛰어난 성능을 발휘하는 강력한 모델DNN이 제대로 작동하려면 대량의 라벨링된 학습 데이터가 필요하고,
12.[Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation] 논문 정리
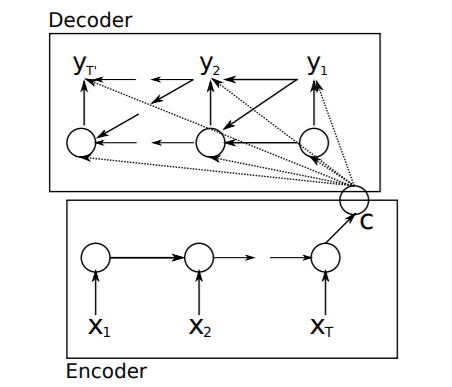
MathJax.Hub.Config({ tex2jax: {inlineMath: [['$', '$'], ['\\(', '\\)']]}, displayAlign: "center" }); 📝 [Learning Phrase Representations using R
13.[NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE] 논문 정리
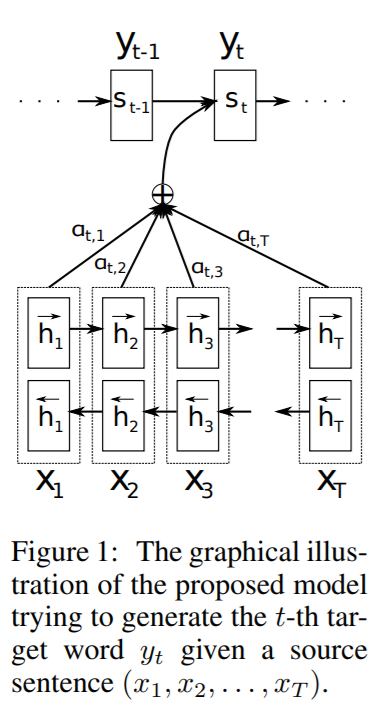
📝 NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATERNN Encoder-Decoder라는 새로운 신경망 모델은 두 개의 순환 신경망(RNN)으로 구성되며, 하나의 RNN은 입력된 기호를 고정
14.[Attention Is All You Need] 논문 정리
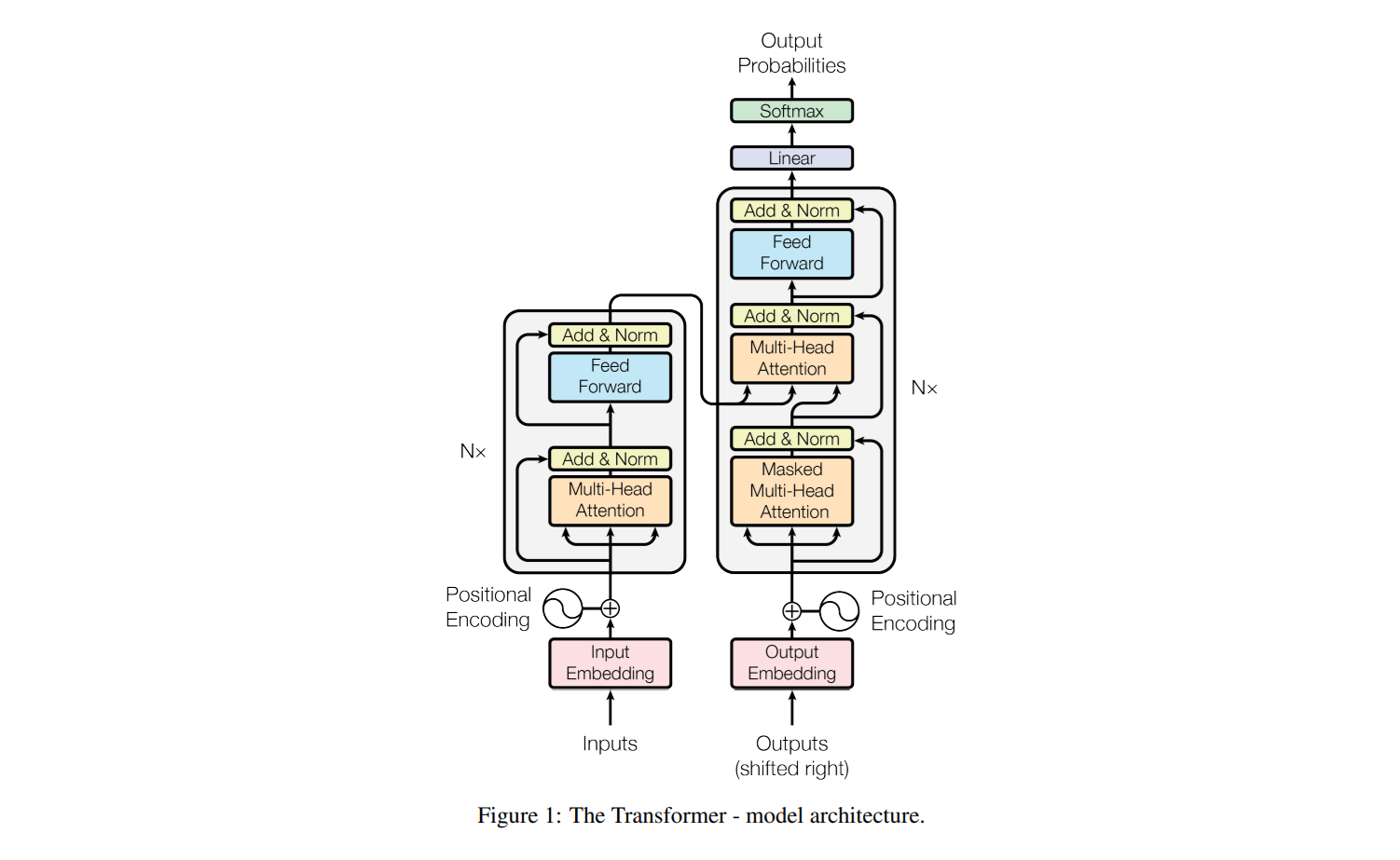
📝 Attention Is All You Need신경망 기계 번역(NMT)은 번역 성능을 극대화하기 위해 하나의 신경망을 공동 최적화하는 방식으로, 기존 인코더-디코더 모델은 고정된 길이의 벡터 사용으로 인해 성능에 제한이 생김이를 해결하기 위해, 특정 단어를 예측할
15.[BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding] 논문 정리
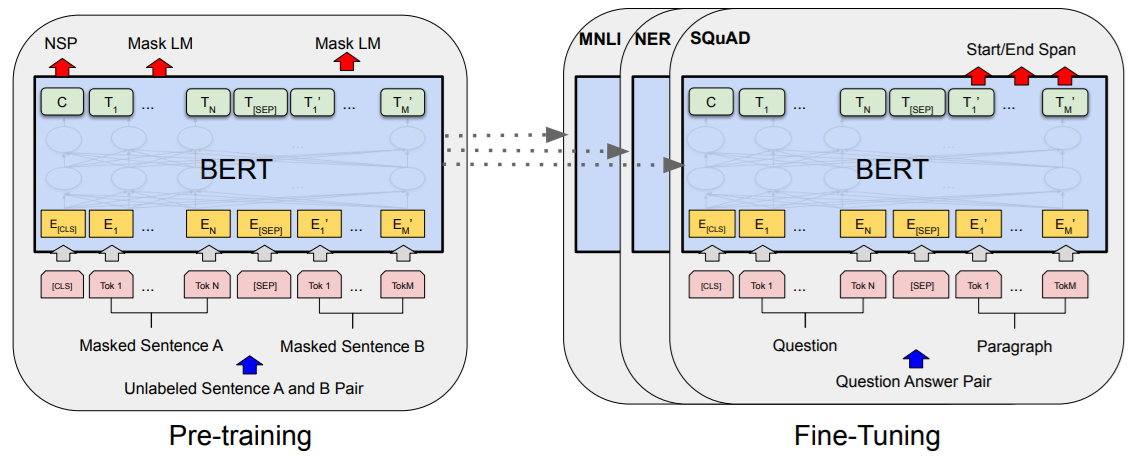
📝 BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding전적으로 어텐션 메커니즘에만 의존하고, 순환 구조나 합성곱을 완전히 제거하는 새로운 단순 네트워크 아키텍처인 Transfo
16.[Improving Language Understanding by Generative Pre-Training] 논문 정리
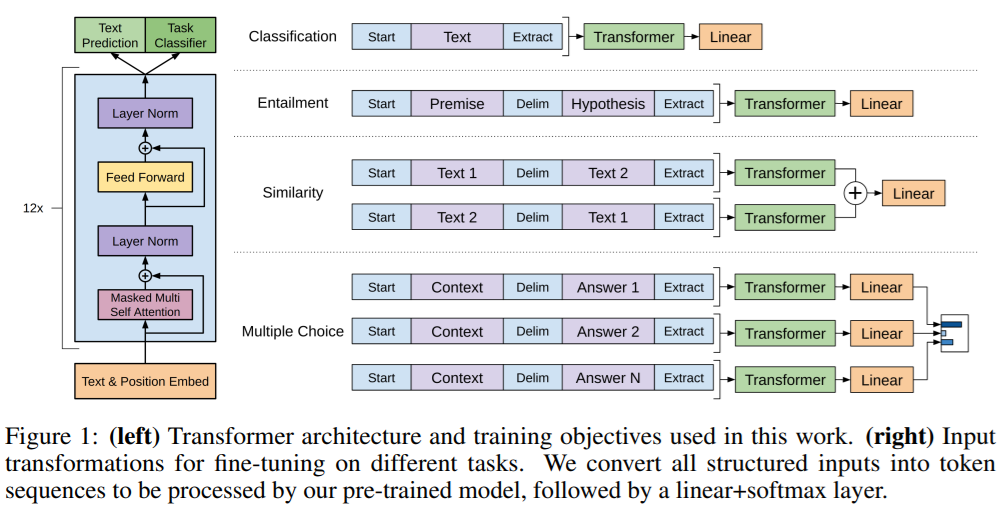
MathJax.Hub.Config({ tex2jax: {inlineMath: [['$', '$'], ['\\(', '\\)']]}, displayAlign: "center" }); 📝 Improving Language Understanding by Gene
17.[Language Models are Unsupervised Multitask Learners] 논문 정리

📝 Language Models are Unsupervised Multitask Learners자연어 이해 과제들은 풍부한 비라벨 데이터가 있음에도, 특정 과제 학습에 필요한 라벨 데이터가 부족하여 모델 성능을 높이기 어려움이를 해결하기 위해, 대규모 비라벨 데이터로
18.[Language Models are Few-Shot Learners] 논문 정리
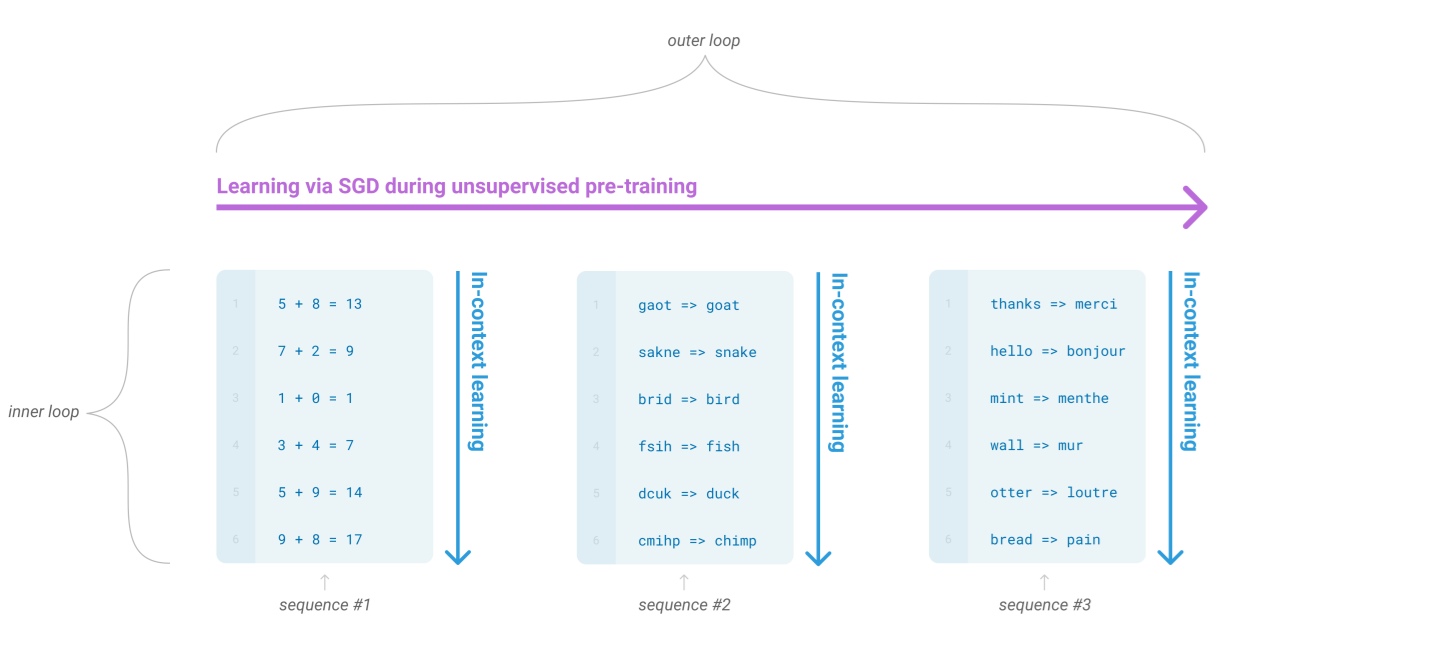
📝 Language Models are Unsupervised Multitask Learners기존 자연어 처리 태스크는 지도 학습이 필요했지만, WebText로 학습한 모델은 명시적 지도 없이도 태스크를 수행함CoQA 데이터셋에서 F1 55점을 기록하며, 기존 모델
19.[LLaMA: Open and Efficient Foundation Language Models] 논문 정리
📝 LLaMA: Open and Efficient Foundation Language Models대규모 언어 모델을 사전 훈련하면 작업별 미세 조정 없이도 few-shot 학습 성능이 크게 향상됨 GPT-3는 1,750억 개의 파라미터를 가진 모델로, 기존 모델보다
20.[Data Augmentation for Imbalanced Regression] 논문 정리
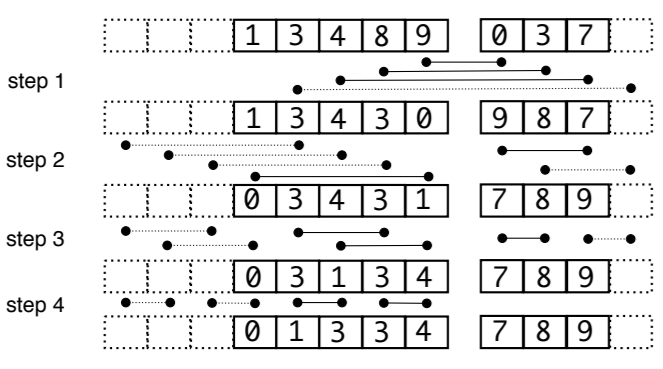
📝 LLaMA: Open and Efficient Foundation Language ModelsLLaMA는 70억~650억 개 매개변수를 가진 기본 언어 모델 모음 공개 데이터셋만을 사용해 최첨단 성능을 내는 모델을 훈련할 수 있음을 증명함 LLaMA-13B는
21.[Billion-scale similarity search with GPUs] 논문 정리
📝 Billion-scale similarity search with GPUs유사성 검색은 고차원 데이터(예: 이미지, 비디오)를 다루며, GPU를 효과적으로 활용하는 것이 중요함 기존 GPU 기반 방법은 k-최소 선택과 메모리 계층 활용의 비효율성으로 인해 병목
22.[The Llama 3 Herd of Models] 논문 정리
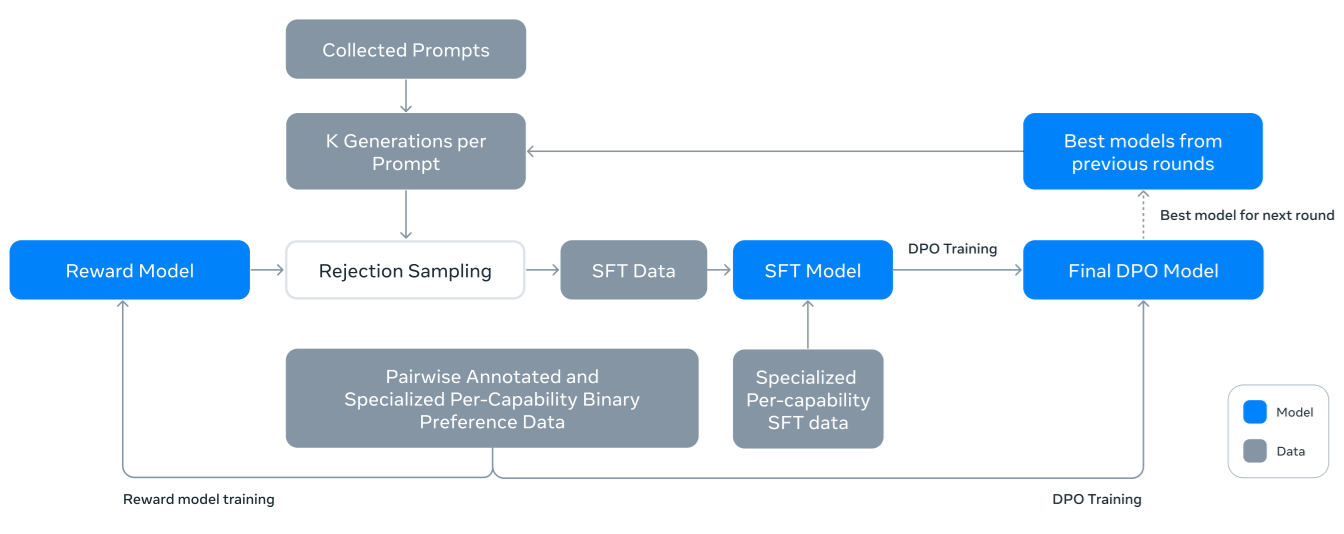
MathJax.Hub.Config({ tex2jax: {inlineMath: [['$', '$'], ['\\(', '\\)']]}, displayAlign: "center" }); 📝 The Llama 3 Herd of Models Abstract 본
23.[A Survey on Transfer Learning] 논문 정리
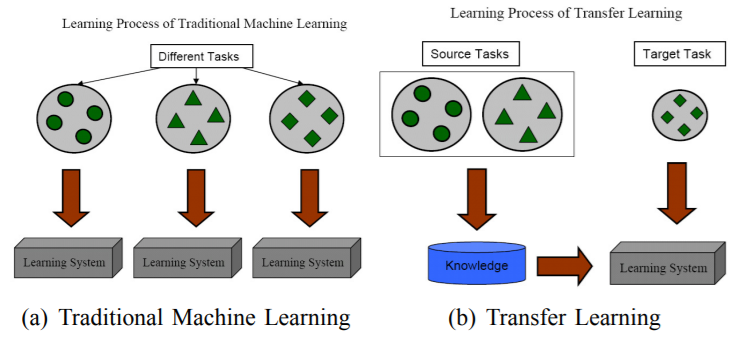
📝 A Survey on Transfer Learning본 논문은 Llama 3라고 불리는 새로운 기초 모델 세트를 소개하고자 함 Llama 3은 다국어 지원, 코딩, 추론 및 도구 사용을 기본적으로 지원하는 언어 모델 집단임구성적 접근법을 통해 이미지, 비디오 및