Abstract
-
본 논문은 Llama 3라고 불리는 새로운 기초 모델 세트를 소개하고자 함
-
Llama 3은 다국어 지원, 코딩, 추론 및 도구 사용을 기본적으로 지원하는 언어 모델 집단임
-
구성적 접근법을 통해 이미지, 비디오 및 음성 기능을 Llama 3에 통합한 실험 결과를 제시함
1 Introduction
-
현대 기초 모델의 개발은 크게 두 단계로 이루어짐:
-
1. 사전 훈련 단계 (pre-training)
- 다음 단어 예측이나 캡셔닝과 같은 단순한 작업을 사용하여 대규모로 모델을 훈련시킴
-
2. 사후 훈련 단계 (post-training)
- 모델이 지시를 따르고 인간의 선호에 맞추며, 코딩이나 추론과 같은 특정 능력을 향상하도록 튜닝함
-
-
고품질 기초 모델 개발에 있어 세 가지 핵심 요소가 있다고 믿음:
-
1. 데이터
- 이전 버전의 Llama와 비교해서, 사전 훈련 및 사후 훈련에 사용하는 데이터의 양과 질을 모두 개선함
-
2. 규모
-
Llama 2의 가장 큰 버전보다 거의 50배 많은, 3.8 × 10^25 FLOP을 사용하여 사전 훈련함
-
15.6T 텍스트 토큰에 대해 4050억 개의 학습 가능한 매개변수를 가진 주력 모델을 사전 훈련함
-
기초 모델에 관한 스케일링 법칙에 따라, 당사의 주력 모델은 동일한 절차로 훈련된 작은 모델들보다 더 우수한 성능을 보임
-
-
3. 복잡성 관리
-
모델 개발 프로세스를 확장할 수 있는 능력을 최대화하기 위해 설계를 선택함
-
예) 훈련 안정성을 극대화하기 위해 혼합 전문가 모델 대신 약간의 수정만 가한 표준 밀집 Transformer 모델 아키텍처를 선택함
-
-
-
Llama 3라는 8B, 70B, 405B 매개변수를 가진 세 가지 다국어 언어 모델 무리를 만듦
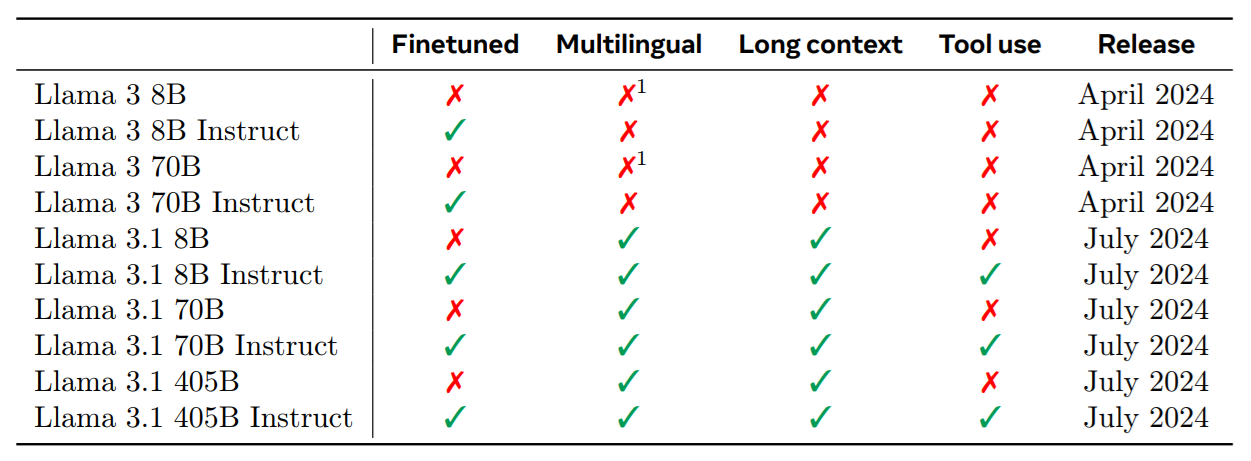 Llama 3 시리즈의 모델별 특성
Llama 3 시리즈의 모델별 특성
2 General Overview
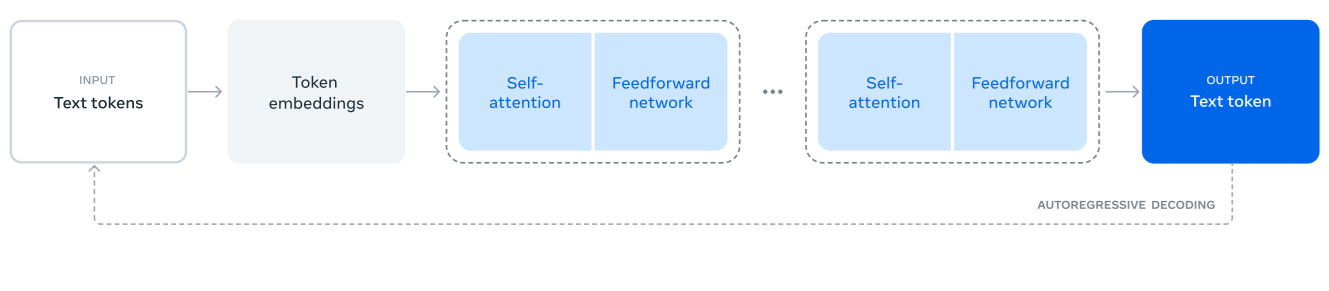 Llama 3의 모델 아키텍처
Llama 3의 모델 아키텍처
(이미지에 대한 설명)
-
1. 입력 (Input: Text tokens)
-
우리가 모델에 넣는 텍스트(단어, 문장 등)를 토큰 단위로 변환함
-
예) "Hello, how are you?" → ["Hello", ",", "how", "are", "you", "?"]
-
-
2. 토큰 임베딩 (Token embeddings)
-
텍스트 토큰을 고유한 숫자 벡터(임베딩)로 변환하는 과정
-
이 벡터들은 모델이 의미를 학습하는 데 사용됨
-
-
3. 트랜스포머 블록 (Self-attention & Feedforward network)
-
Self-attention (셀프 어텐션): 입력 문장 내에서 각 단어(토큰)가 서로 얼마나 관련 있는지 계산
-
Feedforward network (피드포워드 신경망): 어텐션을 거친 정보를 더 깊이 변환하는 단계
-
-
4. 출력 (Output: Text token)
-
모델이 예측한 다음 단어(토큰)를 생성하는 단계
-
예) "Hello, how are" → 모델이 "you?"를 생성
-
-
5. 오토리그레시브 디코딩 (Autoregressive Decoding)
-
모델이 한 번에 하나씩 다음 토큰을 예측하여 문장을 완성하는 방식
-
앞에서 생성한 단어를 입력으로 삼아 다음 단어를 예측함
-
-
Llama 3 모델 개발 단계 구성:
-
1. 언어 모델 사전 훈련 (Pre-training)
-
대규모 다국어 텍스트 코퍼스를 토큰화하여, LLM이 다음 토큰을 예측하도록 학습함
-
4050억 개의 매개변수를 가진 모델을 15.6조 개의 토큰으로 훈련하며, 초기에 8K 토큰 길이의 컨텍스트 윈도우를 사용함
-
추가 훈련을 통해 컨텍스트 윈도우를 128K 토큰까지 확장함
-
-
2. 언어 모델 사후 훈련 (Post-training)
-
모델을 인간 피드백과 정렬하여 지시를 따를 수 있도록 조정함
-
지도 방식의 미세 조정(SFT) 및 Direct Preference Optimization (DPO) 적용
-
도구 사용 등의 새로운 기능을 통합하고, 코딩 및 추론 능력을 향상시킴
-
-
-
멀티모달 확장을 위한 3단계 접근법:
-
1. 멀티모달 인코더 사전 훈련
-
이미지-텍스트 쌍으로 이미지 인코더 학습
-
자가 지도 학습 방식으로 음성 인코더 학습
-
-
2. 멀티모달 인코더 사전 훈련
-
이미지 인코더를 언어 모델과 통합하는 크로스어텐션 기반 어댑터 훈련
-
비디오 어댑터 추가 훈련을 통해 프레임 간 정보 통합
-
-
3. 멀티모달 인코더 사전 훈련
-
음성 인코더를 어댑터를 통해 언어 모델에 연결
-
텍스트-음성 변환 시스템 통합
-
-
-
이러한 실험을 통해 이미지, 비디오, 음성을 이해하고 상호작용할 수 있는 모델을 개발 중이나, 아직 공개 준비가 완료되지 않은 상태임
3 Pre-Training
3.1 Pre-Training Data
-
2023년 말까지의 지식을 포함하는 다양한 데이터 소스를 활용하여 언어 모델 사전 훈련을 위한 데이터셋을 구축함
-
각 데이터 소스에 대해 여러 중복 제거 및 데이터 정제 방법을 적용하여 고품질 토큰을 확보함
-
많은 양의 개인 식별 정보를 포함하는 도메인 및 성인 콘텐츠가 포함된 도메인을 제거함
3.2 Model Architecture
-
Llama 3는 Llama 및 Llama 2와 유사한 표준 밀집 Transformer 아키텍처를 사용하지만, 그룹화된 쿼리 어텐션과 문서 간 어텐션 마스크 등 몇 가지 소규모 수정이 이루어짐
-
어휘는 128K 토큰을 사용하며, RoPE 기본 주파수를 500,000으로 설정해 긴 컨텍스트 지원을 강화함
-
스케일링 법칙을 도입하여 훈련 FLOPs와 최적 훈련 토큰 수 간의 멱법칙 관계:
- 이 분석을 바탕으로 405B 파라미터 주력 모델을 결정하고, 다운스트림 과제 성능 예측에 두 단계 스케일링 법칙 예측을 적용함
3.3 Infrastructure, Scaling, and Efficiency
-
최대 규모의 모델 훈련을 확장하기 위해, 우리는 네 가지 병렬화 기법을 결합한 4D 병렬화를 사용함
-
4D 병렬화는 계산을 여러 GPU에 효율적으로 분산하고, 각 GPU의 모델 파라미터, 옵티마이저 상태, 그래디언트 및 활성화 값이 GPU의 HBM 내에 적절히 배치되도록 함
-
Llama 3의 훈련 비용을 최적화하기 위해, 우리는 다양한 컴퓨팅, 통신, 메모리 최적화 기법을 도입함
-
Llama 3는 Meta의 최신 AI 인프라 및 확장성 기술을 적극 활용한 모델로, 대규모 LLM 훈련의 새로운 기준을 제시함
3.4 Training Recipe
-
Llama 3 405B 사전 훈련에 필요한 세 가지 주요 단계:
-
1. Initial Pre-Training (초기 사전 훈련)
-
훈련 안정성을 개선하기 위해 초기에 작은 배치 크기를 사용하고, 이후에는 효율성을 높이기 위해 배치 크기를 점진적으로 증가시킴
-
이러한 훈련 레시피는 매우 안정적인 것으로 나타났으며, 손실 값의 급격한 변화가 거의 발생하지 않음
-
훈련 초기, 중기, 후기에 따라 데이터 비율을 다르게 조정하면서 모델이 특정한 능력을 더 잘 학습하도록 유도함
-
-
2. Long Context Pre-Training (장문 컨텍스트 사전 훈련)
-
최대 128K 토큰의 컨텍스트 윈도우(context window)를 지원할 수 있도록 장문 컨텍스트 훈련을 수행함
-
모델이 증가된 컨텍스트 길이에 적응할 때까지 점진적으로 컨텍스트 길이를 증가시키며 훈련을 진행함
-
모델의 컨텍스트 길이 적응 성공 여부 평가 2가지 기준을 사용함:
1. 모델의 짧은 컨텍스트(short-context) 평가 성능이 완전히 회복되었는가?
2. 모델이 "건초 더미 속 바늘 찾기(needle in a haystack)" 과제를 해당 길이까지 완벽하게 해결할 수 있는가?
-
-
3. Annealing (어닐링)
-
어닐링은 기계학습(특히 딥러닝)에서 학습률을 점진적으로 낮춰 모델을 더 안정적으로 수렴시키는 과정을 말함
-
어닐링 중 모델 체크포인트의 평균을 계산하여 최종 사전 훈련된 모델을 생성함
-
-
4 Post-Training
4.1 Modeling
-
사후 훈련(post-training) 전략의 핵심은 보상 모델과 언어 모델임
-
먼저, 사전 훈련된 체크포인트 위에 인간이 주석을 단 선호하는 데이터를 사용하여 보상 모델을 훈련함
-
그다음, 사전 훈련된 체크포인트를 지도 미세 조정(SFT)을 통해 미세 조정하고, 직접 선호 최적화(DPO)를 사용하여 체크포인트를 추가로 정렬함
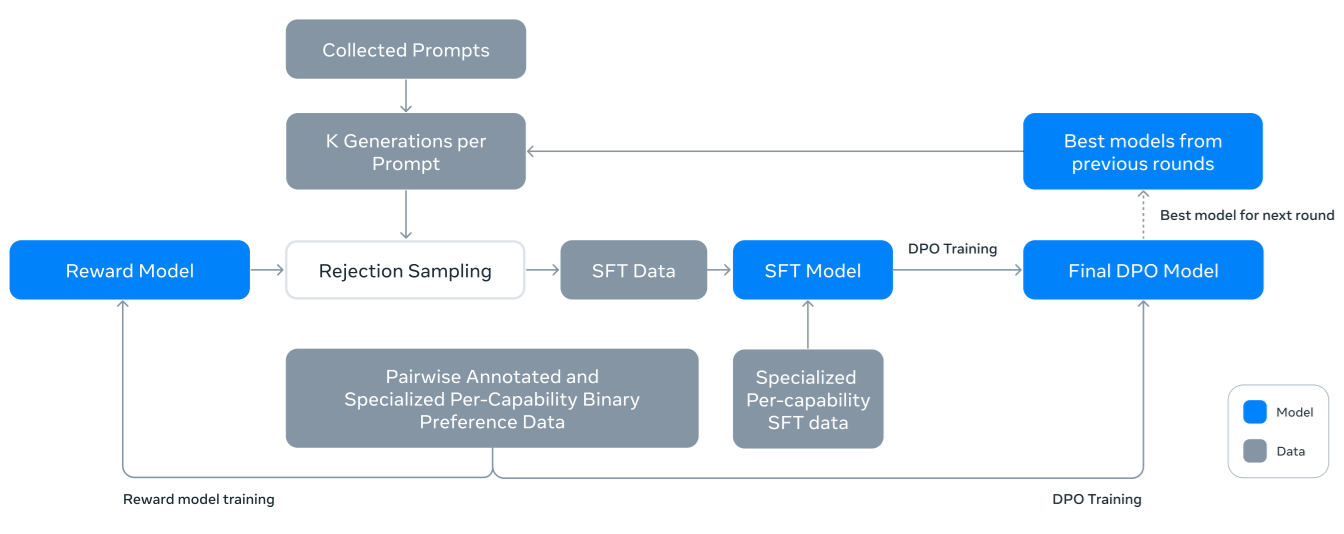 Llama 3의 사후 훈련 (post-training) 전략 흐름도
Llama 3의 사후 훈련 (post-training) 전략 흐름도
(이미지에 대한 설명)
-
1. Collected Prompts (수집된 프롬프트)
- 모델을 학습시키기 위해 다양한 질문(prompt)을 수집함
-
2. K Generations per Prompt (각 프롬프트당 K개 생성)
-
수집한 프롬프트를 기반으로 모델이 여러 개(K개)의 응답을 생성함
-
이 단계에서 다양한 가능한 출력이 만들어짐
-
-
3. Rejection Sampling (거부 샘플링)
-
생성된 여러 개의 응답 중에서 품질이 낮거나 적절하지 않은 응답을 제거하는 과정임
-
Reward Model (보상 모델)이 이 과정에서 사용되며, 가장 적절한 응답을 선택함
-
-
4. SFT Data (지도 학습 미세 조정 데이터)
-
거부 샘플링을 통과한 데이터는 지도 학습 미세 조정(SFT) 데이터로 사용됨
-
지도 학습 미세 조정(SFT) 데이터는 SFT 모델 학습에 활용됨
-
-
5. SFT Model (지도 학습 미세 조정 모델)
-
선택된 데이터로 미세 조정(SFT)된 모델을 학습함
-
추가적으로, 특정 능력(per-capability)에 맞춘 SFT 데이터도 활용됨
-
-
6. DPO Training (직접 선호 최적화)
-
SFT 모델을 학습한 후, DPO를 사용하여 최적화함
-
DPO는 모델이 사용자 선호도를 더 잘 반영하도록 하는 강화 학습 기반 방법임
-
-
7. Final DPO Model (최종 DPO 모델)
-
DPO 훈련을 거쳐 최적화된 최종 모델이 생성됨
-
이전 라운드에서 나온 최상의 모델들과 비교하여, 다음 라운드의 후보 모델이 선택됨
-
-
8. Best models from previous rounds (이전 라운드의 최적 모델)
-
여러 번의 반복 과정을 거쳐 모델의 성능을 지속적으로 개선함
-
최상의 모델이 다음 훈련 과정에서 출발점이 됨
-
4.2 Post-training Data
-
SFT 데이터는 사람이 직접 만든 프롬프트, 거절 샘플링된 응답, 합성 데이터 및 소량의 인간 큐레이션 데이터(사람이 직접 선별하고 다듬은 데이터)를 포함함
-
데이터 품질 관리를 위해 토픽 분류, 품질 점수 평가, 난이도 측정, 의미적 중복 제거 등의 기법을 적용함
-
각 사후 훈련(post-training) 단계에서 데이터 구성을 조정하여 다양한 벤치마크에서 성능을 최적화하고, 높은 품질의 데이터를 우선적으로 사용함
4.3 Capabilities
-
Llama 3는 128K 토큰까지 긴 문맥을 처리할 수 있도록 훈련되었으며, 이를 위해 합성 데이터를 활용한 질문 답변, 문서 요약, 코드 분석 등의 기법을 적용함
-
도구 활용 능력을 강화하여 검색 엔진, 파이썬 인터프리터, 수학 계산 엔진을 사용할 수 있도록 훈련되었으며, 단일 및 다중 단계 도구 호출을 처리 가능함
-
모델이 잘못된 정보를 생성하지 않도록 사전 훈련 데이터를 기반으로 사실 확인 기법을 적용해, 정확성이 낮은 질문에 대해 거부할 수 있도록 조정함
-
사용자 지시에 따라 응답 형식, 길이, 말투 등을 조절할 수 있도록 유연성을 높였으며, 시스템 프롬프트를 통해 다양한 역할을 수행할 수 있도록 설계됨
5 Results
Llama 3 모델의 다양한 평가와 안전성 측면에 대한 연구 내용을 설명함
5.1 Pre-trained Language Model
- Llama 3의 사전 훈련 언어 모델이 다양한 표준, 적대적 벤치마크와 MCQ 설계 견고성 및 데이터 오염 분석을 통해 경쟁 모델 대비 우수한 성능과 신뢰성을 입증함
5.2 Post-trained Language Model
- Llama 3의 사후 훈련 언어 모델이 일반지식, 지시 수행, 시험, 코드 생성, 다국어, 수학 및 추론, 장문맥 처리, 그리고 도구 활용 등 다양한 영역에서 경쟁 모델을 앞지르는 탁월한 성능을 보임
5.3 Human Evaluations
- Llama 3의 인간 평가를 통해 실제 사용자 경험에 부합하는 미묘한 언어 표현, 구조, 그리고 문화적 맥락 이해 능력 등이 경쟁력 있는 성능을 보여줌
5.4 Safety
- Llama 3는 전반적인 안전 미세 조정, 레드 팀 평가, 시스템 보호(Llama Guard) 등을 통해 다국어, 장문맥, 도구 사용 및 사이버 · CB(화학/생물학) 무기 위험 등 다양한 위험 요소에 대해 경쟁 모델 대비 낮은 위반율과 균형 잡힌 거부율을 달성했다는 것을 입증함
6 Inference
-
Llama 3 405B 모델 추론을 효율적으로 수행하기 위한 주요 기술을 연구함:
-
1. Pipeline Parallelism (파이프라인 병렬 처리)
-
2. FP8 Quantization (FP8 양자화)
-
7 Vision Experiments
-
Llama 3에 시각적 인식 기능을 통합 하기 위한 일련의 실험을 수행했으며, 이를 위해 두 가지 주요 단계로 구성된 합성적 접근 방식을 적용함
-
사전 훈련된 이미지 인코더와 사전 훈련된 언어 모델을 조합하여,
두 모델 사이에 교차 주의 레이어를 추가 및 훈련함 -
시간 정보를 인식하고 처리할 수 있도록 모델을 학습시키기 위해
시간 집계 레이어와 추가적인 비디오 교차 주의 레이어를 도입함
8 Speech Experiments
-
Llama 3에 음성 기능을 통합하는 합성적 접근 방식을 연구하기 위해 실험을 수행함
-
입력(Input) 처리 방식
-
음성 신호를 처리하기 위해 인코더(Encoder)와 어댑터(Adapter)를 결합하여 통합함
-
Llama 3의 음성 이해 기능을 제어하기 위해 시스템 프롬프트를 활용함
-
시스템 프롬프트가 제공되지 않을 경우, Llama 3는 일반적인 음성 대화 모델로 동작하고, 텍스트 전용 버전의 Llama 3와 일관된 방식으로 사용자 음성에 효과적으로 응답이 가능함
-
-
음성 인터페이스(Speech Interface) 기능
-
Llama 3의 음성 인터페이스는 최대 34개 언어를 지원함
-
텍스트와 음성 입력을 번갈아 사용할 수 있어, 고급 오디오 이해 작업을 해결할 수 있음
-
-
음성 생성(Speech Generation) 실험
-
Llama 3의 음성 생성기는 독점적인 TTS 시스템을 기반으로 설계됨
-
언어 모델을 음성 생성 목적으로 추가 미세 조정하지 않음
-
추론 시 Llama 3 임베딩을 활용하여 음성 합성의 지연 시간, 정확도, 자연스러움을 개선하는 것 에 초점을 맞춤
-
10 CONCLUSION
-
Llama 3 모델을 개발하는 과정에서, 고품질 데이터, 규모, 그리고 단순성에 집중하는 것이 일관되게 가장 좋은 결과를 가져온다는 사실을 발견함
-
모델 개발 과정에서 기술적 문제뿐만 아니라 조직적 의사결정
(벤치마크 오버피팅 방지, 신뢰할 수 있는 인간 평가)이 중요한 역할을 함 -
안전성 분석 결과가 긍정적으로 나타남에 따라, Llama 3 언어 모델을 공개적으로 배포하려 함
