Abstract
-
전적으로 어텐션 메커니즘에만 의존하고, 순환 구조나 합성곱을 완전히 제거하는 새로운 단순 네트워크 아키텍처인 Transformer를 제안함
-
이 모델은 품질 면에서 우수할 뿐 아니라 병렬화가 용이하고, 학습 시간이 훨씬 짧게 걸린다는 사실을 보여줌
-
WMT 2014 영-독 번역에서 28.4 BLEU, 영-프 번역에서 단일 모델로 41.8 BLEU 달성
-
영어 구문 분석 등 다른 작업에도 적용 가능해 범용성과 효율성을 동시에 입증함
1 Introduction
-
순환 신경망(LSTM, GRU)은 시퀀스 모델링에서 강력한 성능을 보였지만, 순차적 연산 특성 때문에 병렬화가 어려운 단점이 있음
-
최근 연구에서 인자화 기법과 조건부 연산을 활용하여 성능과 연산 효율성을 개선했지만, 근본적인 순차적 처리 문제는 해결되지 않음
-
어텐션 메커니즘은 거리와 관계없이 의존성을 모델링할 수 있지만,
기존 모델들은 여전히 순환 신경망과 함께 사용되는 경우가 많음 -
Transformer는 순환 구조 없이 어텐션 메커니즘만으로 동작하며,
높은 병렬성을 통해 기존 모델보다 빠르고 뛰어난 번역 품질을 제공함
2 Background
-
CNN 기반 모델들은 연산을 병렬로 수행하지만, 두 위치 간 관계를 학습하는 데 필요한 연산량이 거리와 함께 증가하는 문제가 있음
-
Transformer는 이러한 연산량을 상수로 줄이지만, 해상도 감소 문제를 해결하기 위해 다중 헤드 어텐션을 도입
-
셀프 어텐션은 시퀀스 내 위치 간 관계를 모델링하는 메커니즘이며, 독해, 요약, 포함관계 판별 등 다양한 NLP 작업에서 성공적으로 활용됨
-
Transformer는 최초로 RNN이나 CNN 없이 순수한 셀프 어텐션만으로 입력과 출력을 표현하는 변환 모델
3 Model Architecture
3.1 Encoder and Decoder Stacks
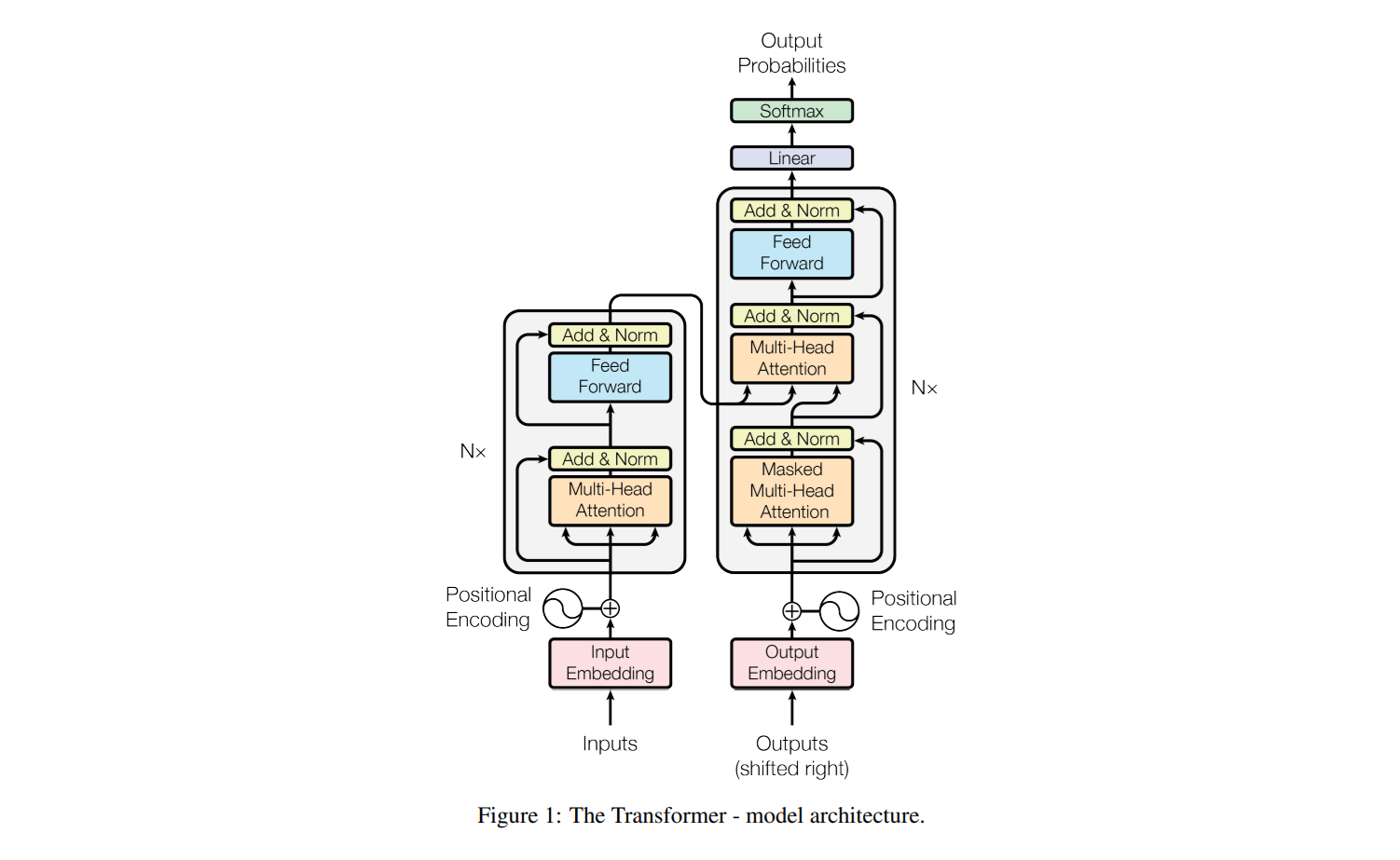
1. 인코더 (Encoder)
-
입력을 처리하는 부분으로, N개의 인코더 블록이 존재함
-
각 블록은 다층 구조로 반복적으로 적용됨
-
구성 요소:
-
Input Embedding: 입력 단어를 벡터로 변환함
-
Positional Encoding: 단어 순서를 고려하기 위한 위치 정보 추가함
-
Multi-Head Attention: 입력 시퀀스 내에서 관계를 학습함
-
Feed Forward Network (FFN): 비선형 변환을 수행하여 특성을 추출함
-
Residual Connection + Layer Normalization: 안정적인 학습을 돕기 위해 추가됨
-
2. 디코더 (Decoder)
-
인코더에서 처리된 정보를 바탕으로 출력을 생성함
-
구성요소:
-
Output Embedding: 정답 문장을 벡터로 변환함
-
Positional Encoding: 출력 단어의 순서 정보 추가함
-
Masked Multi-Head Attention: 미래 단어를 가리지 않도록 마스킹(masking) 적용함
-
Multi-Head Attention (인코더-디코더 어텐션): 인코더의 출력과 상호작용하여 문맥을 학습함
-
Feed Forward Network (FFN): 추가적인 비선형 변환을 수행함
-
Residual Connection + Layer Normalization: 안정적인 학습을 위해 추가함
-
Softmax & Linear Layer: 최종 출력을 확률 분포로 변환함
-
3.2 Attention
-
어텐션 함수는 쿼리(Query), 키(Key), 값(Value)의 집합을 출력 벡터로 매핑하는 연산임
-
출력은 값(Value)의 가중합(Weighted Sum)으로 계산됨
-
각 값에 할당되는 가중치는 쿼리(Query)와 해당 키(Key) 간의 유사도로 결정됨
-
-
Scaled Dot-Product Attention
-
입력은 쿼리(Q), 키(K) 및 값(V)이며, 각각의 차원은 dk와 dv임
-
쿼리(Q)와 키(K)의 내적을 계산함
-
내적 결과를 로 나누어 스케일링함
-
Softmax를 적용하여 가중치를 계산함
-
가중치를 값(V)에 곱하여 최종 어텐션 출력 도출함
-
-
Multi-Head Attention
-
하나의 어텐션 연산만 수행하는 대신, 여러 개의 서로 다른 어텐션을 병렬로 수행하는 것이 더 효과적임
-
각 헤드는 서로 다른 특징을 학습하여 더 정교한 표현 가능함
-
쿼리(Q), 키(K), 값(V)를 각각 번 선형 변환한 후, 병렬로 어텐션 연산을 수행함
-
병렬 연산된 결과를 병합한 후 최종 선형 변환을 수행하여 최종 출력을 얻음
-
-
Applications of Attention in our Model (어텐션의 활용)
-
Transformer에서는 세 가지 방식으로 어텐션을 활용함
-
인코더-디코더 어텐션
-
인코더 내 셀프 어텐션
-
디코더 내 셀프 어텐션
-
-
3.3 Position-wise Feed-Forward Networks
-
인코더와 디코더의 각 레이어에는 완전 연결 피드포워드 네트워크(FFN)가 포함되어 있으며, 이는 각 위치에서 독립적으로 동일하게 적용됨
-
FFN은 두 개의 선형 변환과 중간에 ReLU 활성화 함수로 구성됨
- 입출력 차원은 , 내부 레이어 차원은 임. 이 FFN은 커널 크기 1인 컨볼루션으로 볼 수도 있음
3.4 Embeddings and Softmax
-
입력 및 출력 토큰을 임베딩 벡터(차원: )로 변환하기 위해 학습된 임베딩을 사용함
-
디코더 출력은 선형 변환과 소프트맥스 함수를 거쳐 다음 토큰의 확률을 예측함
-
두 개의 임베딩 레이어와 소프트맥스 직전의 선형 변환에서 동일한 가중치 행렬을 공유하며, 임베딩 레이어에서 가중치 행렬을 배로 조정하여 사용함
3.5 Positional Encoding
-
트랜스포머 모델에는 순환과 컨볼루션이 없음
-
모델이 입력 순서 정보를 활용할 수 있도록 위치 인코딩(Positional Encoding)을 추가함
(여기서 pos는 단어의 위치, i는 차원의 인덱스)
-
이 방식은 모델이 상대적 위치 정보를 쉽게 학습할 수 있도록 설계됨
-
학습 가능한 임베딩 방식도 실험했으나, 두 방식의 성능 차이는 거의 없음
-
따라서 모델이 더 긴 시퀀스를 일반화할 가능성이 있는 사인-코사인 방식을 채택함
4 Why Self-Attention
-
Self-Attention을 사용하는 동기를 설명하기 위해 세 가지 주요 요건을 고려함:
1. 레이어별 총 계산 복잡도
2. 병렬화할 수 있는 계산량
3. 네트워크에서 장거리 의존성을 처리하는 경로 길이
-
컨볼루션은 깊이 쌓아야 장거리 의존성을 학습 가능하며, 이는 계산 비용을 증가시킴
-
Self-Attention은 적절한 제한을 두면 긴 시퀀스에서도 성능 개선 가능
-
어텐션 헤드들은 문법적 · 의미적 구조를 학습하는 경향이 있음
6 RESULTS
6.1 Machine Translation
-
WMT 2014 영어-독일어 번역 태스크에서 Transformer (big)이 BLEU 28.4로 기존 모델을 크게 능가함
-
영어-프랑스어 번역에서도 BLEU 41.0을 기록하며 최고 성능을 달성,
기존 모델 대비 1/4의 훈련 비용이 듦 -
체크포인트 평균화, 빔 서치, 길이 페널티 등 다양한 기법을 적용하여 최적 성능을 달성함
6.2 Model Variations
-
어텐션 헤드 수와 차원 크기를 변경한 결과, 단일 헤드는 성능이 저하되며 너무 많아도 효과적이지 않음
-
어텐션 키 크기를 줄이면 성능이 저하됨. 모델 크기가 클수록 성능이 향상되며, 드롭아웃이 과적합 방지에 효과적임
-
위치 인코딩 방식을 학습된 임베딩으로 바꿔도 성능 차이는 거의 없음
7 Conclusion
-
트랜스포머는 순환 레이어 없이 전적으로 어텐션에 기반한 최초의 시퀀스 변환 모델임
-
번역 태스크에서 순환 및 합성곱 기반 모델보다 훨씬 빠르게 학습하며, WMT 2014에서 최고 성능을 기록함
-
텍스트 외 이미지, 오디오, 비디오에도 적용하고, 효율적인 어텐션 메커니즘을 연구할 계획임
