📝 BLEU: a Method for Automatic Evaluation of Machine Translation
Abstract
-
기계 번역의 품질을 확인해기 위해 사람이 직접 확인하는 과정이 오래 걸리고 비용도 많이 필요함
-
빠르고 저렴하고 언어 제약이 없는 자동 평가 방법을 제안함
1 Introduction
1.1 Rationale
-
인간이 직접 평가하는 방법들은 비용이 많이 들고 시간도 많이 걸림
-
기계 번역 시스템을 개발하는 연구자들에게 큰 문제인데, 번역 시스템은 매일 개선되고 있기 때문에, 어떤 변화가 효과적인지 빠르게 판단할 필요가 있음
-
비용이 적게 들고 빠르고 언어에 구애받지 않는 자동 평가 방법을 사용하면, 이 문제를 해결할 수 있다고 판단함
1.2 Viewpoint
그렇다면 기계 번역의 성능을 어떻게 측정할 수 있을까?
-
기계 번역이 인간 번역과 얼마나 가까운지를 평가하는 것
-
기계 번역의 품질을 판단하려면, 그것이 인간 번역과 얼마나 유사한지를 숫자로 측정
논문에서 제안하는 평가 방법의 두 가지 주요 요소:
1. 번역의 유사성을 수치로 나타낼 수 있는 평가 기준 2. 품질이 뛰어난 인간 번역 모음
- 참조 번역과 기계 번역 간의 유사성을 측정할 때, 다양한 길이의 구 단위로 비교하여 점수를 계산하는 방법을 사용함
2 The Baseline BLEU Metric
2.1 Modified n-gram precision
-
BLEU의 핵심 개념은 정밀도(precision)라는 지표를 활용하는 것
-
정밀도 계산 방법:
-
후보 번역에서 사용된 단어(유니그램) 중 참조 번역에도 등장하는 단어의 개수를 셈
-
그 개수를 후보 번역의 총 단어 수로 나눔
-
-
번역 후보 문장에서 참조 번역과 일치하는 n-그램 수를 계산함
-
동일한 단어가 과도하게 반복되는 문제를 막기 위해 클리핑 적용함
-
높은 n-그램 정밀도는 번역의 적절성과 유창성을 반영함
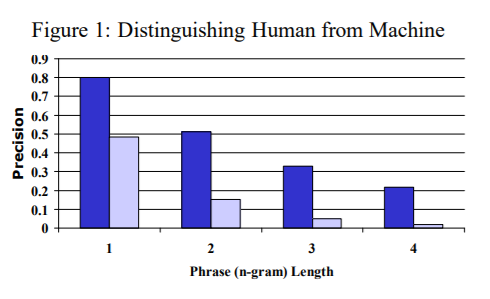
-
진한 파란색 (왼쪽 막대) → 인간 번역의 n-그램 정밀도)
연한 파란색 (오른쪽 막대) → 기계 번역의 n-그램 정밀도) -
n-그램 길이가 길어질수록(2-그램, 3-그램, 4-그램) 인간과 기계 번역 간의 정밀도 차이가 점점 커짐
2.2 Sentence length
-
번역 후보 문장은 너무 길거나 짧아서는 안 되며, n-그램 정밀도가 일부 해결하지만 완벽하진 않음
-
단순한 리콜(recall) 계산은 여러 참조 번역에서 단어를 전부 포함하는 경우 부자연스러운 번역이 되어 부적절함
-
너무 긴 번역은 수정된 n-그램 정밀도로 패널티를 받지만, 너무 짧은 번역을 막기 위해 별도의 짧은 문장 패널티(Brevity Penalty, BP)를 적용함
-
이 패널티는 코퍼스 전체에서 후보 번역과 참조 번역의 최적 길이 비율(r/c)을 지수함수로 감소시키는 방식으로 계산됨
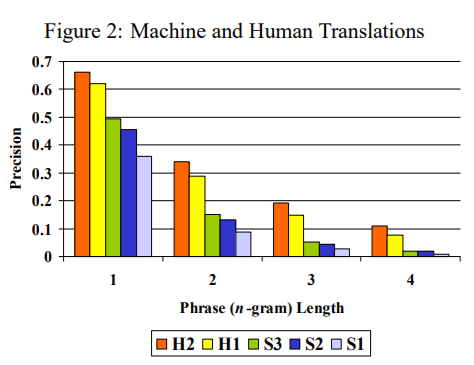
H2 (주황색): 네이티브 수준의 인간 번역
H1 (노란색): 비원어민 인간 번역
S3 (녹색): 가장 성능이 좋은 기계 번역 시스템
S2 (파란색): 중간 수준의 기계 번역 시스템
S1 (보라색): 가장 성능이 낮은 기계 번역 시스템
-
H2(네이티브 번역)가 가장 높은 정밀도를 유지하고 있으며, H1(비원어민 번역)도 비교적 높은 성능을 보임
-
기계 번역 시스템(S3, S2, S1)은 인간 번역보다 전반적으로 낮은 정밀도를 가짐
2.3 BLEU details
- BLEU 점수는 테스트 코퍼스의 수정된 정밀도 값들의 기하평균을 구한 후, 지수 형태의 짧은 문장 패널티(Brevity Penalty, BP)를 곱하는 방식으로 계산
(후보 번역의 길이: , 효과적인 참조 코퍼스의 길이: )
BLEU 점수 계산식:
로그 도메인에서의 BLEU 계산식:
- 기본 설정으로는 를 사용하며, 모든 가중치 는 균등하게 으로 설정
3 The BLEU Evaluation
-
BLEU 점수는 0에서 1 사이의 값을 가지고, 원본 번역과 정확히 일치하는 경우에만 1에 가까운 점수를 받음
-
한 문장에 대해 참조 번역이 많을수록 BLEU 점수가 높아져 참조 번역 개수가 다른 평가 결과를 비교할 때는 신중해야 함
-
충분히 큰 테스트 코퍼스가 존재한다면 단일 참조 번역만을 사용해도 비교적 신뢰할 수 있는 평가가 가능함
4 The Human Evaluation
번역 품질 평가를 위해 두 그룹의 평가자를 모집함:
- 단일언어 그룹: 영어를 모국어로 하는 10명
- 이중언어 그룹: 중국어를 모국어로 하면서, 몇 년간 미국에서 거주한 10명
- 총 500개의 테스트 문장에서 무작위로 선택된 일부 중국어 문장을 대상으로 평가를 진행함
4.1 Monolingual group pairwise judgments
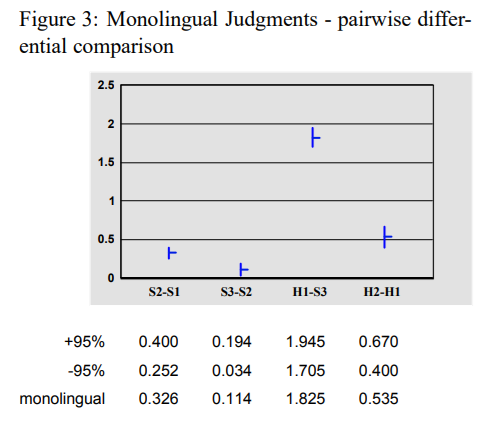
-
연속된 두 시스템 간 평균 점수 차이와 95% 신뢰 구간을 나타냄
-
H1은 중국어와 영어 모두 원어민이 아닌 평가자임
-
H1(인간 번역자 1)은 가장 우수한 번역 시스템보다 훨씬 높은 점수를 받았으나,
H2(인간 번역자 2)보다는 낮았음 -
H2는 영어 원어민이었기 때문에 H1보다 더 높은 평가를 받음
-
H1과 H2의 점수 차이 또한 95% 신뢰 수준에서 유의미함
4.2 Bilingual group pairwise judgments
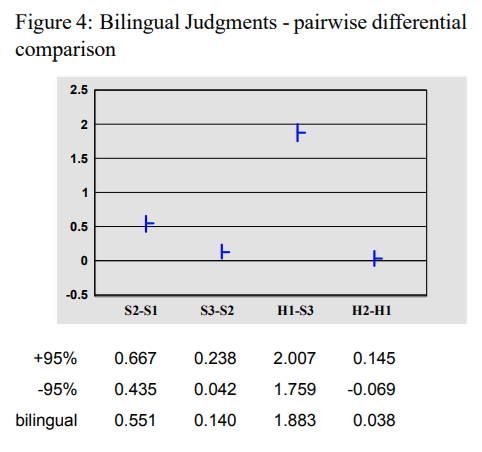
-
이중언어 그룹도 S3가 S2보다 약간 더 나은 번역을 제공한다고 판단했으며, 이 차이는 95% 신뢰 수준에서 유의미함
-
하지만 이중언어 그룹은 인간 번역자들의 결과(H1과 H2)를 거의 동일하게 평가했으며, 95% 신뢰 수준에서 유의미한 차이를 보이지 않음
-
이중언어 그룹이 번역의 유창성보다는 원문의 의미를 얼마나 잘 전달하는지에 더 집중했기 때문으로 보임
5 BLEU vs The Human Evaluation
단일언어 그룹의 평가 점수를 BLEU 점수와 비교하여 선형 회귀 분석을 수행한 결과:
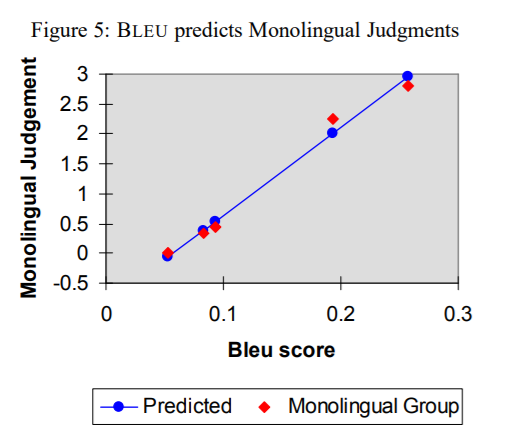
-
상관 계수가 0.99로 매우 높게 나타남
-
BLEU 점수가 인간 평가 점수와 매우 잘 일치한다는 것을 의미함
-
BLEU가 S2와 S3의 미묘한 차이를 정확하게 구분한다는 점이 흥미롭게 느껴짐
이중언어 그룹의 평가 점수에 적용한 결과:
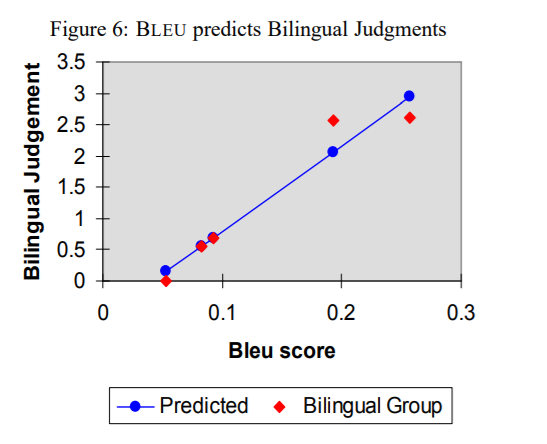
- 상관 계수는 0.96으로, 단일언어 그룹보다는 약간 낮지만 여전히 높은 상관 관계를 보임
BLEU 점수와 인간 평가 점수의 정규화 비교:
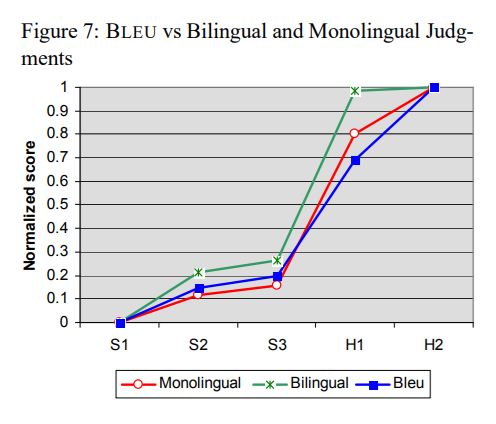
-
BLEU 점수와 단일언어 그룹 평가 점수는 매우 높은 상관 관계를 보임
-
BLEU 점수가 S2와 S3의 작은 차이를 정확하게 반영함
-
S3와 H1(인간 번역자 1)의 큰 차이도 BLEU가 정확하게 평가하고 있음
-
기계 번역 시스템과 인간 번역자(H1, H2) 사이의 격차가 상당히 크다는 점을 확인할 수 있음
6 Conclusion
-
BLEU를 활용하면 연구자들이 보다 효과적인 모델링 아이디어를 빠르게 찾아낼 수 있음
-
BLEU의 가장 큰 장점은 단일 문장 평가에서 발생할 수 있는 오류를 개별적으로 보정하려 하기보다는, 전체 테스트 코퍼스에서 평균을 내어 오류를 상쇄시키는 방식으로 인간 평가와 높은 상관 관계를 유지한다는 점임
-
BLEU가 텍스트 요약 평가 및 유사한 자연어 생성 작업에도 적용될 수 있을 것이라고 기대함
