📝 Efficient Estimation of Word Representations in Vector Space
Abstract
-
매우 큰 데이터셋에서 단어의 연속 벡터 표현을 계산하기 위해 두 가지 모델 아키텍처를 제안하려고 함
-
이 모델들은 낮은 계산 비용으로도 기존 방식보다 훨씬 정확도가 높은 단어 벡터 학습이 가능함
-
구문 및 의미적 유사도 측정 테스트에서 최고 성능을 달성
1 Introduction
-
최근 머신러닝 기술이 발전함에 따라 보다 복잡한 모델을 대규모 데이터에 학습시키는 것이 가능해짐
-
수십억 개의 단어와 수백만 개의 어휘를 포함한 대규모 데이터셋에서 고품질 단어 벡터를 학습하는 기법을 소개하려함
-
단순한 문법적 규칙을 넘어 단어 표현의 유사성이 확장될 수 있음이 밝혀짐
-
예를 들면, King" - "Man" + "Woman"의 결과가 "Queen" 벡터와 가장 가까워짐
2 Model Architectures
여기서 소개할 모든 모델에서 학습 복잡도(training complexity)는 다음과 같이 비례함:
2.1 Feedforward Neural Net Language Model (NNLM)
입력층(input layer), 투영층(projection layer), 은닉층(hidden layer), 출력층(output layer) 으로 구성된다. 입력층에서는 𝑁개의 이전 단어들이 1-of-𝑉 인코딩(즉, 원-핫 인코딩) 방식으로 표현되며, 여기서 𝑉는 어휘(vocabulary)의 크기를 의미한다. 입력층의 단어들은 투영층 𝑃로 투영되며, 이 층의 차원은 𝑁×𝐷이고, 공유된 투영 행렬(shared projection matrix)을 사용한다. 한 번에 활성화되는 입력의 개수는 𝑁개뿐이므로, 투영층의 구성은 상대적으로 계산 비용이 적게 든다.
훈련 샘플의 계산 복잡도:
여기서 가장 큰 계산량을 차지하는 항(term)은 𝐻×𝑉이다. 이를 줄이기 위해 몇 가지 실용적인 방법들이 제안되었다. 예를 들어, 계층적 소프트맥스(hierarchical softmax)를 사용하거나, 훈련 중 정규화(normalization)를 생략하는 모델을 활용하는 방식이 있다.
2.2 Recurrent Neural Net Language Model (RNNLM)
순환 신경망(Recurrent Neural Network, RNN) 기반 언어 모델은 피드포워드 NNLM의 몇 가지 제한 사항을 극복하기 위해 제안되었다. RNN 모델은 투영층 없이 입력층, 은닉층, 출력층으로 구성됨. 이 모델의 특징은 은닉층을 자기 자신과 연결하는 재귀 행렬(recurrent matrix)을 포함하고 있다.
각 훈련 샘플의 계산 복잡도:
여기서 단어 표현 벡터(𝐷)의 차원은 은닉층(𝐻)과 동일하다. 앞서 설명한 것처럼, 계층적 소프트맥스를 활용하면 𝐻×𝑉를 로 줄일 수 있다. 따라서 대부분의 계산량은 𝐻×𝐻에서 발생한다.
2.3 Parallel Training of Neural Networks
-
대규모 데이터 세트에서 신경망을 학습하기 위해 DistBelief 분산 프레임워크를 활용하여 여러 모델을 병렬로 실행함
-
각 모델 복제(replica)는 중앙 서버를 통해 그래디언트 업데이트를 동기화하며, 미니배치 비동기 확률적 경사 하강법(SGD)과 Adagrad을 사용하여 학습을 최적화함
-
일반적으로 100개 이상의 복제를 활용하며, 여러 CPU 코어를 통해 데이터 센터 내에서 병렬 처리함
3 New Log-linear Models
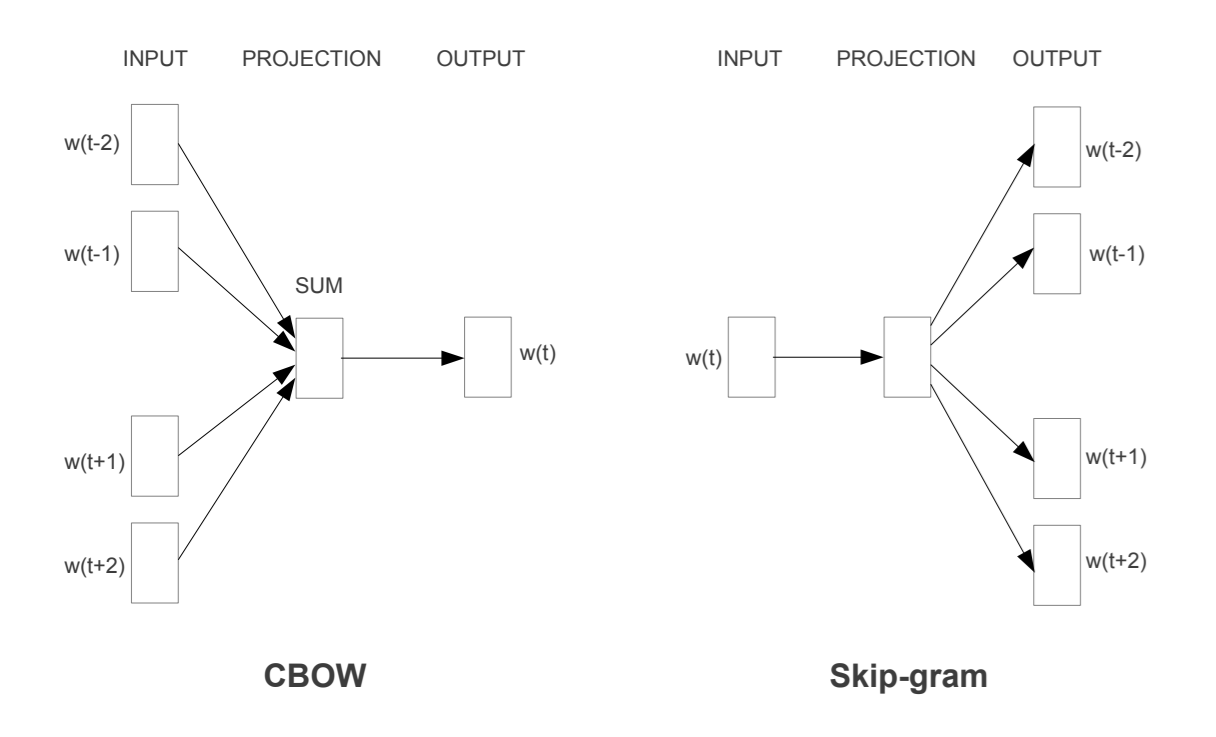
3.1 Continuous Bag-of-Words Model
-
CBOW 모델은 피드포워드 NNLM에서 비선형 은닉층을 제거하고, 모든 단어가 동일한 투영 위치를 공유하는 방식으로 동작함
-
이 모델은 문맥 내 단어들의 순서를 고려하지 않고, 과거 및 미래 단어들을 평균화하여 현재 단어를 예측하는 로그-선형 분류기임
-
위 그림에서 𝑤(𝑡−2), 𝑤(𝑡−1), 𝑤(𝑡+1), 𝑤(𝑡+2)라는 주변 단어들을 이용해 중심 단어 𝑤(𝑡)를 예측함
학습 복잡도:
3.2 Continuous Skip-gram Model
-
Skip-gram 모델은 CBOW와 유사하지만, 주어진 단어로부터 주변 단어를 예측하는 방식으로 동작함
-
현재 단어를 입력으로 사용하고, 일정 범위 내의 앞뒤 단어들을 예측하도록 학습함
-
보다 먼 단어는 연관성이 낮기 때문에 샘플링 비율을 낮추어 가중치를 조절함
-
위 그림에서는 중심 단어 𝑤(𝑡)를 입력으로 두고 주변 단어들 𝑤(𝑡−2), 𝑤(𝑡−1), 𝑤(𝑡+1), 𝑤(𝑡+2)을 출력으로 예측함
학습 복잡도:
(𝐶는 최대 예측 거리이며, 실험에서는 𝐶=10을 사용)
4 Results
"biggest가 big과 유사한 방식으로, small과 유사한 단어는 무엇인가?"
이 질문은 단순한 벡터 연산으로 해결이 가능하다
-
단어 벡터의 품질을 비교하기 위해 의미적·구문적 관계를 평가하는 테스트 세트를 사용함
-
벡터 연산을 통해 단어 간 관계를 예측할 수 있으며, 고차원 벡터와 대량의 데이터를 사용할수록 정확도가 향상됨
-
Skip-gram 모델이 의미적 관계에서 가장 우수했으며, 병렬 학습을 통해 성능 극대화 가능
-
Microsoft 문장 완성 테스트에서 RNNLM과 결합하여 최고 성능을 기록
