📝 Distributed Representations of Sentences and Documents
Abstract
-
머신러닝에서 고정 길이 특징 벡터가 필요하지만, 기존 Bag-of-Words는 단어 순서와 의미를 무시하는 단점이 있음
-
이를 해결하기 위해 문서별 밀집 벡터를 학습하는 Paragraph Vector 제안
-
문서 내 단어를 예측하는 방식으로 학습되며, 실험 결과 기존 방법보다 성능이 뛰어남
-
여러 텍스트 분류 및 감성 분석 작업에서 최첨단 결과 달성
1 Introduction
-
BoW는 단어 순서를 무시하고 의미를 고려하지 않아서 한계가 있음
-
Paragraph Vector는 문장, 문단, 문서별로 고유한 벡터를 학습해 단점을 극복
-
단어 벡터와 문단 벡터를 결합해 다음 단어를 예측하는 방식으로 학습됨
-
감성 분석과 텍스트 분류에서 기존 방법보다 훨씬 좋은 성능을 보임
2 Algorithms
2.1 Learning Vector Representation of Words
-
단어 벡터(Word Vector)는 단어를 고유한 벡터로 변환하는 방식
-
문맥 속 단어를 입력하면 다음 단어를 예측하는 방식으로 학습됨
-
신경망 기반 언어 모델을 사용하며, 학습이 끝나면 의미가 비슷한 단어들이 가까운 벡터 공간에 위치
-
"King - man + woman = Queen" 같은 벡터 연산이 가능하며, 기계 번역 등 다양한 자연어 처리 작업에 활용됨
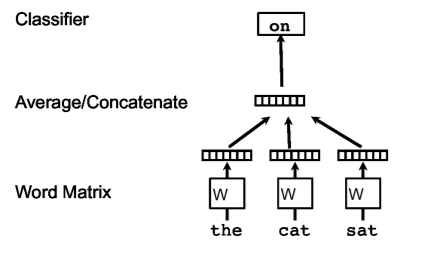
(순서 : 아래에서 위)
Word Matrix (단어 임베딩)
- 문장의 각 단어(예: "the", "cat", "sat")를 수치 벡터로 변환
- 일반적으로 사전 훈련된 단어 임베딩(Word2Vec, GloVe 등) 또는 학습 가능한 임베딩을 사용함
- 각 단어는 W라는 매트릭스를 통해 벡터 표현으로 변환됨
Average/Concatenate (평균 또는 연결 연산)
- 단어 벡터들을 평균(Average)하거나 단순히 연결(Concatenate)하여 하나의 벡터로 만듬
- 이렇게 하면 문장의 전체 의미를 하나의 벡터로 표현 가능
Classifier (분류기)
- 최종 벡터를 입력으로 받아 특정 카테고리(예: "on")로 분류하는 역할을 함
- 일반적으로 신경망(MLP), 소프트맥스(Softmax) 분류기 등이 사용됨
2.2 Paragraph Vector: A distributed memory model
-
문장을 문맥(Context) + 문단 정보(Paragraph ID) 로 구성해서 다음 단어를 예측
-
예측을 반복하면서 문단을 대표하는 벡터(문단 벡터)를 학습
-
문단 벡터는 이후 머신러닝 모델의 입력으로 사용 가능 (예: 문서 분류, 감정 분석 등)
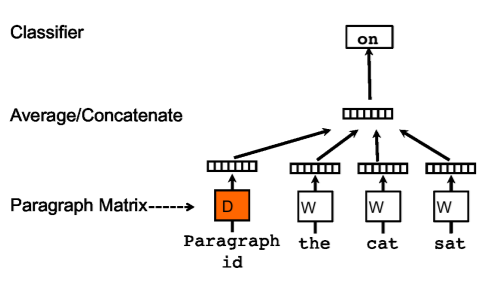
(순서 : 아래에서 위)
Paragraph Matrix (문단 행렬)
- 각 문단(Paragraph)은 하나의 고유한 벡터로 표현됨
- 문단 ID를 기반으로 행렬 𝐷에서 해당 문단에 대한 벡터를 찾음
- 문단 벡터는 전체 문맥에서 부족한 정보를 기억하는 역할을 함
Word Matrix (단어 행렬)
- 각 단어는 벡터로 변환됨
- 예제에서는 "the", "cat", "sat"라는 단어들이 각각 𝑊행렬에서 벡터로 변환됨
Average/Concatenate (평균 또는 연결 연산)
- 문단 벡터 𝐷와 단어 벡터 𝑊들을 합쳐 하나의 벡터를 만듦
- 방법: 평균(Average) 또는 연결(Concatenation)
Classifier (분류기)
- 최종 벡터를 입력으로 받아 다음 단어(예: "on")를 예측
- 학습이 완료되면 문단 벡터는 문단의 의미를 내포한 고유한 특징 벡터가 됨
2.3 Paragraph Vector without word ordering: Distributed bag of words
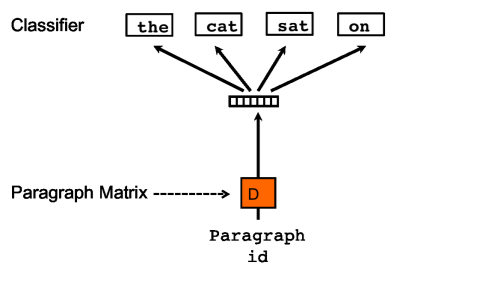
(순서 : 아래에서 위)
Paragraph Matrix (문단 행렬)
- 각 문단(Paragraph)은 고유한 벡터로 표현됨
- 문단 ID를 기반으로 행렬 D에서 해당 문단에 대한 벡터를 찾음
- 문단 벡터는 전체 문맥에서 부족한 정보를 기억하는 역할을 함
Classifier (분류기)
- 단어 벡터들과 문단 벡터를 입력으로 받아 다음 단어를 예측
- 학습이 끝나면 문단 벡터가 문단의 의미를 담은 특징 벡터가 됨
3 Experiments
-
문단 벡터(Paragraph Vector)를 활용해 감성 분석과 정보 검색 실험을 수행
-
기존 Bag-of-Words 모델은 문장 구조를 반영하지 못해 성능이 낮음
-
PV-DM과 PV-DBOW를 결합한 문서 벡터는 기존 모델보다 뛰어난 성능을 보임
-
특히, 문장 구문 분석 없이도 Recursive Neural Network보다 낮은 오류율을 기록
결론 및 정리
-
단어의 분산 표현은 기존 NLP 작업에서 성공적으로 활용되어 왔으며, 문장과 문단 수준에서도 연구가 진행됨
-
기존 방식들은 주로 문장을 단위로 처리하며, 많은 라벨 데이터를 필요로 하는 반면, Paragraph Vector는 비지도 학습 방식으로 문맥을 예측하며 문단 벡터를 학습할 수 있음
-
실험 결과, 감성 분석에서 기존 최신 모델과 비슷하거나 더 나은 성능을 보임
-
Bag-of-Words 모델의 한계를 극복하고, 순차 데이터 학습에도 적용 가능할 것으로 기대됨
