📝 Improving Language Understanding by Generative Pre-Training
Abstract
-
자연어 이해 과제들은 풍부한 비라벨 데이터가 있음에도, 특정 과제 학습에 필요한 라벨 데이터가 부족하여 모델 성능을 높이기 어려움
-
이를 해결하기 위해, 대규모 비라벨 데이터로 생성적 사전 학습 후, 각 과제에 맞춰 판별적 미세 조정을 수행하는 방법을 제안함
-
미세 조정 시 과제별 입력 변환을 적용하여 효과적 전이를 달성하면서도 모델 구조 변경을 최소화함
-
기존 판별적 학습 모델 대비 뛰어난 성능을 보이며, 12개 과제 중 9개에서 최신 성능을 초과 달성함
1 Introduction
-
단어 수준 이상의 정보를 비라벨 텍스트에서 학습하는 것은 최적의 학습 목표와 전이 방법이 명확하지 않기 때문에 어려움
-
이를 해결하기 위해, 비지도 사전 학습(언어 모델링) 후 지도 미세 조정을 수행하는 반지도 접근법을 제안하여 다양한 작업에 적용 가능하도록 함
-
Transformer를 활용하여 장기 의존성을 효과적으로 처리하며, 작업별 입력 변환을 적용하여 최소한의 모델 변경으로 전이 성능을 극대화함
2 Related Work
Semi-supervised learning for NLP (자연어처리를 위한 반지도 학습)
-
반지도 학습은 비지도 데이터에서 단어나 문장 통계를 계산하여 지도 학습 모델의 피처로 활용하는 방식
-
단어 임베딩을 사용하면 여러 NLP 태스크에서 성능이 향상되지만, 보통 단어 수준의 정보만 전이됨
-
최근 연구들은 문장 수준의 임베딩을 학습하여 더 풍부한 의미 정보를 포착하는 방향으로 발전하고 있음
Unsupervised Pre-training (비지도 사전 훈련)
-
비지도 사전 훈련은 모델을 더 좋은 초기화 상태로 만들고, 지도 학습을 보완하는 역할을 함
-
이미지 분류, 음성 인식, 기계 번역 등 다양한 태스크에서 딥 뉴럴 네트워크 학습을 향상시키는 데 활용됨
-
LSTM 기반 사전 훈련 모델은 단기 문맥만 반영하는 한계가 있어, 트랜스포머를 사용하면 더 긴 범위의 정보를 학습 가능함
Auxiliary Training Objectives (보조 학습 목표)
-
보조 학습 목표를 추가하면 시퀀스 라벨링, 품사 태깅, 개체명 인식 같은 태스크에서 성능이 향상될 수 있음
-
일부 연구에서는 언어 모델링을 보조 목표로 추가하여 학습하지만, 비지도 사전 훈련만으로도 충분한 언어적 정보를 학습할 수 있음
-
태스크마다 새로운 파라미터를 추가해야 하는 기존 접근법과 달리, 최소한의 모델 변경으로 다양한 태스크에 적용 가능함
3 Framework
3.1 Unsupervised pre-training
비지도 학습 코퍼스 가 주어졌을 때, 표준 언어 모델 학습 목표를 사용하여 다음과 같은 우도를 최대화한다:
여기서 는 컨텍스트 윈도우 크기이며, 조건부 확률 는 파라미터 를 가진 신경망으로 모델링된다. 이 파라미터들은 확률적 경사 하강법(stochastic gradient descent, SGD)으로 학습된다.
실험에서는 다층 트랜스포머(Transformer) 디코더를 언어 모델로 사용한다. 이 모델은 입력 컨텍스트 토큰들에 대해 다중 헤드 자기-어텐션(multi-headed self-attention)을 수행한 후, 위치별 피드포워드(feedforward) 계층을 적용하여 목표 토큰 분포를 생성한다.
여기서 는 컨텍스트 벡터, 은 레이어 수, 는 토큰 임베딩 행렬, 는 위치 임베딩 행렬이다.
3.2 Supervised fine-tuning
식(1)을 사용해 사전 훈련한 후, 지도 학습 데이터를 활용하여 모델을 특정 태스크에 적응시킨다. 지도 데이터셋 가 주어졌을 때, 각 인스턴스는 입력 토큰 시퀀스 와 레이블 를 포함한다. 사전 훈련된 모델을 통과한 후, 최종 트랜스포머 블록의 활성화 값 을 선형 출력 계층에 전달하여 레이블을 예측한다.
이때, 최적화할 목표 함수는 다음과 같다:
추가적으로, 언어 모델링을 보조 목표로 포함하면 학습 성능이 향상된다. 특히, 지도 모델의 일반화 성능이 개선되고, 수렴 속도가 빨라진다. 따라서 최종적으로 다음과 같은 결합된 목표를 최적화한다:
미세 조정 시 추가되는 파라미터는 와 구분 토큰의 임베딩뿐이다.
3.3 Task-specific input transformations
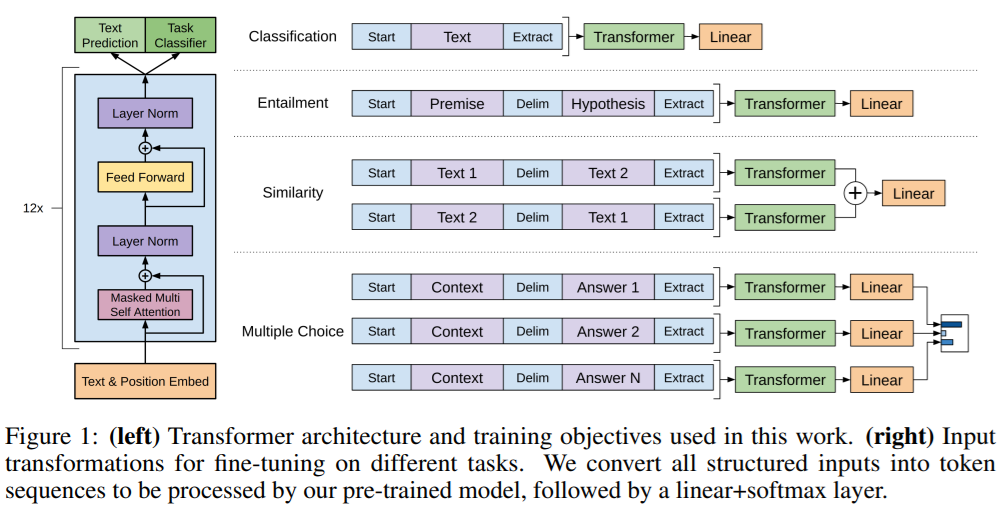
(이미지에 대한 설명)
트랜스포머 아키텍처 (이미지의 왼쪽 부분)
-
입력: 텍스트 + 위치 임베딩 (Text & Position Embed)
- 입력 토큰을 모델이 처리할 수 있도록 토큰 임베딩과 위치 임베딩을 더하여 제공함
-
트랜스포머 블록 (Transformer Block)
-
트랜스포머 구조가 12번 반복됨
-
각 블록은 다음과 같이 구성됨:
-
마스킹된 멀티 헤드 자기-어텐션 (Masked Multi-Head Self Attention):
-
자기-어텐션(Self-Attention)으로 문맥 정보를 학습함
-
마스킹을 적용하여 미래 정보를 보지 않도록 제한함
-
-
레이어 정규화 (Layer Norm)
- 학습을 안정적으로 수행하기 위해 각 층마다 정규화를 적용
-
피드포워드 네트워크 (Feed Forward Network)
- 각 토큰의 표현을 더 풍부하게 하기 위한 비선형 변환을 수행함
-
다시 레이어 정규화 (Layer Norm)
- 추가 정규화를 적용하여 안정적인 학습을 유도함
-
-
-
출력 계층 (Task Classifier / Text Prediction)
-
모델의 최종 출력은 주어진 태스크(분류, 생성 등)에 따라 다르게 사용됨
-
분류 태스크에서는 Task Classifier 계층이 추가됨
-
텍스트 생성 태스크에서는 Text Prediction 계층을 통해 확률 분포를 출력함
-
태스크별 입력 변환 방식 (이미지의 오른쪽 부분)
1. 분류 (Classification)
-
입력: [Start] + Text
-
변환 과정:
- [Start] 토큰을 추가하여 입력 시작점을 나타냄
- 텍스트를 트랜스포머에 입력함
- 마지막 출력 벡터를 선형 계층을 거쳐 클래스 확률을 예측함
2. 텍스트 함의 (Entailment)
-
입력: [Start] + 전제 + [Delim] + 가설
-
변환 과정:
-
전제와 가설을 [Delim] 토큰으로 구분하여 연결함
-
모델이 두 문장 간의 관계를 파악할 수 있도록 변환함
-
트랜스포머를 통과한 후, 선형 계층에서 함의 여부를 예측함
(참/거짓/중립)
-
3. 문장 유사도 (Similarity Tasks)
-
입력: 두 개의 문장(Text 1, Text 2)을 비교함
-
변환 과정:
-
[Start] + Text 1 + [Delim] + Text 2 형태로 변환하여 모델에 입력함
-
두 문장을 독립적으로 처리한 후, 결과를 요소별로 합산하여 최종 예측을 수행함
-
4. 다중 선택 (Multiple Choice)
-
입력: [Start] + 문맥 + [Delim] + 정답 1 (또는 정답 2, …, 정답 N)
-
변환 과정:
-
각 답변 후보를 컨텍스트와 함께 입력으로 변환함
-
[Delim] 토큰을 사용하여 문맥과 답변을 분리함
-
각 답변을 개별적으로 트랜스포머에 통과시킨 후, 선형 계층을 통해 정답 확률을 예측함
-
4 Experiments
-
GPT 계열의 초기 버전 모델은 장거리 문맥 학습이 중요한 태스크에서 특히 강점을 보임
-
기존 SOTA 모델을 초월한 9개 태스크에서 새로운 최고 성능을 기록함
-
작은 데이터셋(STS-B)부터 큰 데이터셋(SNLI)까지 일관된 성능 향상 확인됨
-
엔드 투 엔드 사전 학습 + 파인 튜닝 접근법이 효과적임을 증명함
5 Analysis
-
사전 훈련된 Transformer의 레이어를 점진적으로 전이할수록 성능이 향상되며, MultiNLI에서 최대 9% 향상됨
-
Zero-shot 성능은 훈련 업데이트 수가 증가할수록 꾸준히 증가하며, Transformer는 LSTM보다 전이 학습에 적합한 구조를 가짐
-
사전 훈련 없이 Transformer를 직접 지도 학습한 경우, 평균 14.8% 성능이 저하되었으며 이는 사전 훈련의 필요성을 시사함
-
LSTM과 Transformer를 비교한 결과, Transformer가 대부분의 태스크에서 우수한 성능을 보였으나 MRPC 태스크에서는 LSTM이 더 나은 결과를 보임
6 Conclusion
-
길고 연속적인 텍스트로 사전 훈련하면 배경 지식과 장거리 의존성을 학습할 수 있으며, 이를 다양한 판별 태스크로 전이 가능한 모델을 제안함
-
우리 모델은 12개 데이터셋 중 9개에서 SOTA 성능을 달성하며, Transformer와 장거리 의존성이 있는 데이터셋이 효과적임을 시사함
-
이번 연구가 자연어 이해뿐만 아니라 비지도 학습 연구 전반을 발전시키는 계기가 되길 기대함
