📝 Language Models are Few-Shot Learners
Abstract
-
대규모 언어 모델을 사전 훈련하면 작업별 미세 조정 없이도 few-shot 학습 성능이 크게 향상됨
-
GPT-3는 1,750억 개의 파라미터를 가진 모델로, 기존 모델보다 10배 더 큼
-
번역, 질의응답, 문제 해결 등의 여러 NLP 과제에서 강력한 성능을 보이며 즉석 추론도 수행 가능
-
하지만, few-shot 학습이 어려운 경우가 있고, 웹 데이터 학습 방식의 한계도 존재함
1 Introduction
-
NLP에서 사전 훈련 모델이 발전했지만, 여전히 과제별 데이터와 미세 조정(fine-tuning)이 필요함
-
인간처럼 적은 예제만으로 새로운 언어 과제를 수행하는 것이 목표
-
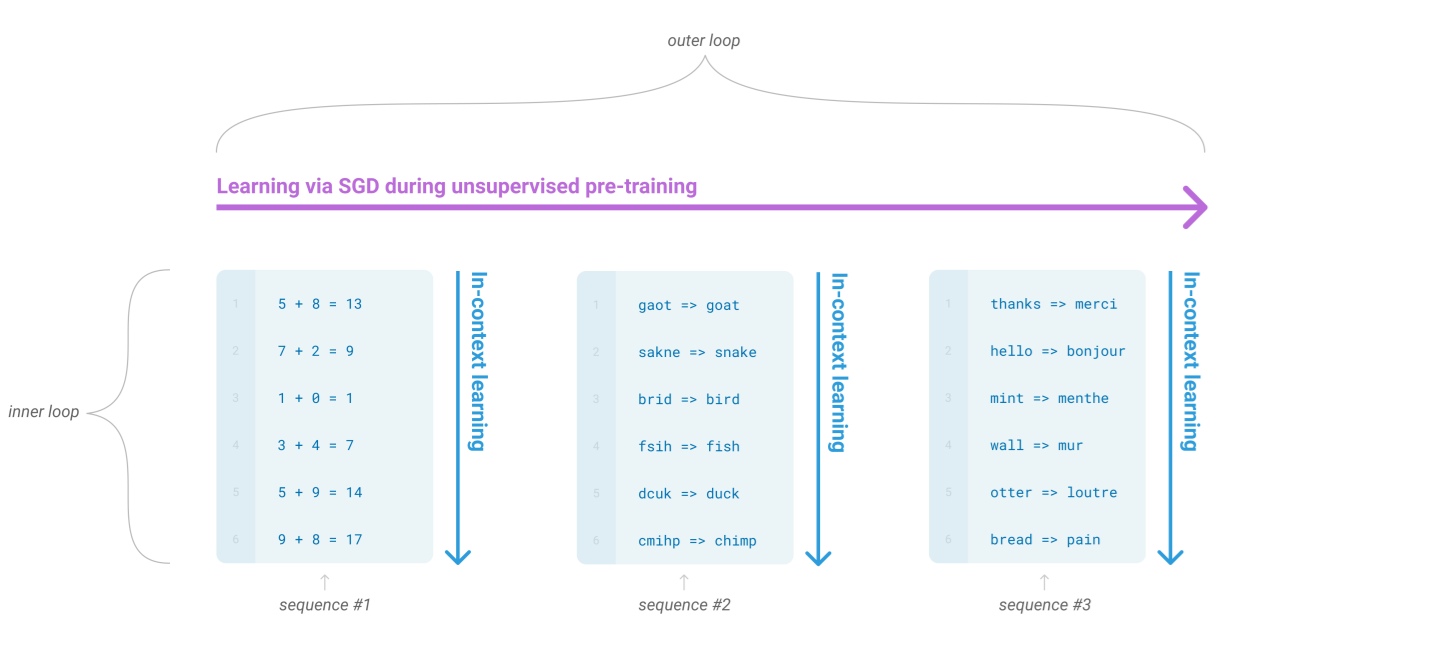
GPT-3(1,750억 매개변수)를 훈련해 맥락 내 학습(in-context learning) 성능을 평가함
-
일부 과제에서는 기존 미세 조정된 모델 성능을 뛰어넘기도 하지만, 한계도 존재함
2 Approach
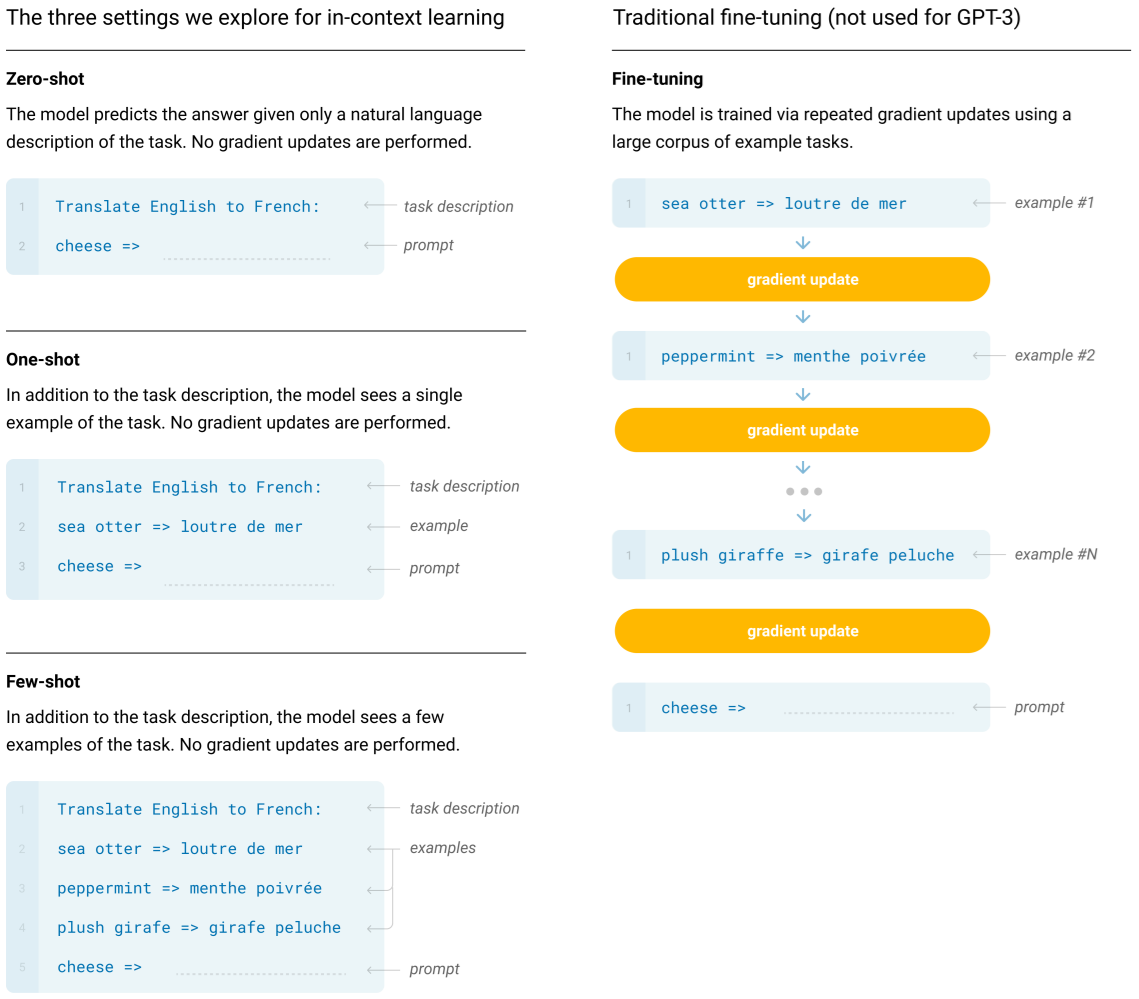
1. 왼쪽: In-context Learning (Zero-shot, One-shot, Few-shot)
(1) Zero-shot
-
개념: 모델에게 직접 작업 설명(task description)만 주고, 예시(example)는 제공하지 않음
-
동작 방식:
-
모델은 “Translate English to French: sea otter => ?”처럼 단순히 지시문(프롬프트)만 보고 답을 생성
-
가중치 업데이트가 일어나지 않으며, 오직 사전 학습(Pre-training)에서 학습된 지식을 활용해 즉석에서 추론
-
(2) One-shot
-
개념: 작업 설명에 단 하나의 예시를 추가해 줌
-
동작 방식(예시):
Translate English to French:
sea otter => loutre de mer
peppermint => ?-
모델에게 “이런 식으로 번역한다”는 한 번의 예시를 보여주고, 이후 유사한 입력에 대해 답을 생성하게 함
-
모델의 파라미터는 업데이트되지 않고, 프롬프트 내 예시를 통해 작업 형식을 학습
-
(3) Few-shot
-
개념: 작업 설명에 여러 개(소수 개)의 예시를 함께 제시함
-
동작 방식(예시):
Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
play => jouer
giraffe => girafe
cheese => ?-
모델은 (영어 단어 → 프랑스어 번역) 예시를 여러 번 본 뒤, 마지막에 새 입력에 대한 번역을 시도
-
가중치 업데이트가 일어나지 않으며, 오직 사전 학습에서 학습된 지식을 활용해 즉석에서 추론
-
가중치 업데이트 없이, 제공된 예시를 통해 문맥에서 규칙을 추론
-
2. 오른쪽: 전통적 Fine-tuning
-
개념: GPT-3 이전의 일반적인 접근법으로, 모델 파라미터를 직접 업데이트하여 특정 태스크에 최적화하는 방법
-
동작 방식:
-
모델에 여러 개의 예시(“sea otter => loutre de mer”, “peppermint => menthe poivrée” 등)를 입력으로 줌
-
실제 출력과 모델 출력의 차이를 최소화하도록 오차 역전파(Gradient Descent)로 모델 가중치를 학습
-
학습이 끝난 모델은 새로운 입력에 대해 추론 수행
-
-
장점/특징:
-
특정 태스크에 매우 특화된 모델을 만들 수 있어 높은 정확도를 달성하지만, 추가 데이터 수집과 학습 과정이 필요
-
매 태스크마다 새로운 모델 파라미터를 훈련해야 하므로 비용이 큼
-
3. 비교 및 핵심 요점
-
In-context Learning (Zero-shot, One-shot, Few-shot)
-
장점:
-
파라미터 업데이트가 없으므로, 새로운 태스크에 즉시 적용 가능
-
적은 데이터나 예시만으로도 모델이 문맥에서 규칙을 추론
-
-
단점:
-
충분한 예시나 매우 명확한 지시문이 없으면 성능이 제한적
-
특정 태스크에 최적화된 모델만큼의 정확도는 아닐 수 있음
-
-
-
Fine-tuning
-
장점:
- 데이터셋을 충분히 제공하면 해당 태스크에서 최적 성능을 달성 가능
-
단점:
-
학습 비용(계산 자원, 시간)이 크며, 태스크별로 모델을 다시 학습해야 함
-
모델 파라미터가 변경되므로, 다른 태스크 적용 시 재학습 필요
-
-
3 Results
-
GPT-3는 언어 모델링부터 닫힌 책 QA, 번역, 윈오그래드형 문제, 상식 추론, 독해, SuperGLUE, NLI 등 광범위한 벤치마크를 대상으로 평가됨
-
여러 과제에서 기존 SOTA에 근접하거나 능가하는 성능을 보였으나, NLI 등 일부 분야에서는 여전히 어려움을 드러냄
-
산술 계산이나 문자 변환, 기사 생성 같은 합성·정성적 과제에서도 인상적인 적응력을 시연했고, 전반적으로 모델 크기에 따라 일관된 성능 향상을 확인
4 Measuring and Preventing Memorization Of Benchmarks
-
인터넷에서 수집한 대규모 데이터에는 테스트 세트가 포함될 가능성이 높음
-
사후 분석으로 오염 여부를 확인해봤더니, 실제로 일부 겹치는 사례가 있으나 대부분 성능 변화는 미미함
-
단, 일부 벤치마크(예: PIQA, Winograd)에서는 약간의 성능 하락이 관찰되거나 측정이 어려웠음
-
결론적으로 오염이 전혀 없다고는 못 하나, 대체로 보고된 성능에 큰 영향은 없어 보임
5 Limitations
-
GPT-3는 긴 문장에서 일관성을 잃거나 모순된 내용을 포함할 수 있음. 상식적 물리 개념을 잘 다루지 못하고, 일부 비교·추론 작업에서 성능이 낮음
-
양방향 학습을 포함하지 않아 특정 작업(예: 빈칸 채우기, 문장 비교 등)에서 성능이 떨어질 가능성이 있음
-
자기지도 학습의 한계로 인해, 모델이 세계를 더 잘 이해하려면 강화 학습이나 다중 모달 학습이 필요할 수도 있음
-
대규모 모델은 계산 비용이 높고 비효율적이며, 데이터 편향을 포함할 가능성이 있어 해석 가능성과 신뢰성 문제가 있음
6 Conclusion
-
1,750억 파라미터 모델이 제로샷(zero-shot), 원샷(one-shot), 그리고 퓨샷(few-shot) 설정에서 우수한 성능 보임
-
일부 과제에서 파인튜닝 모델과 비슷한 성능에 도달, 즉석 과제에서도 높은 품질의 결과 생성 가능
-
파인튜닝 없이도 스케일링에 따른 성능 향상 경향이 관찰됨
-
거대 언어 모델이 범용적이고 적응력 있는 언어 시스템의 핵심 요소가 될 가능성 시사
