[Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation] 논문 정리
논문 정리
📝 Learning Phrase Representations using RNN Encoder–Decoder
for Statistical Machine Translation
Abstract
-
RNN Encoder-Decoder라는 새로운 신경망 모델은 두 개의 순환 신경망(RNN)으로 구성되며, 하나의 RNN은 입력된 기호를 고정 길이 벡터로 변환(인코딩)하고, 다른 RNN은 이를 다시 새로운 기호 시퀀스로 변환(디코딩)함
-
제안된 모델의 인코더와 디코더는 출력 시퀀스(타겟 시퀀스)가 주어진 입력 시퀀스(소스 시퀀스)를 조건으로 가질 확률을 최대화하도록 공동 학습됨
-
의미적으로나 문법적으로 유의미한 언어 표현을 학습할 수 있음을 정성적 분석을 통해 보여줌
1 Introduction
-
본 논문에서는 RNN Encoder-Decoder라는 새로운 신경망 모델을 제안하며, 두 개의 RNN을 활용해 문장을 벡터로 변환 후 다시 문장으로 복원하는 방식을 설명함
-
이 모델은 소스 문장을 조건으로 한 타겟 문장의 확률을 최대화하도록 공동 학습되며, 기억 용량과 학습 효율성을 높이기 위해 개선된 은닉 유닛을 사용함
-
영어→프랑스어 번역 실험에서 기존 구문 기반 통계적 기계 번역(SMT) 시스템과 결합 시 번역 성능이 향상됨을 확인함
-
분석 결과, RNN Encoder-Decoder는 구문적·의미적 구조를 유지하는 표현을 학습하며, 기존 번역 모델보다 언어적 규칙성을 더 잘 포착하는 것으로 나타남
2 RNN Encoder–Decoder
2.1 Preliminary: Recurrent Neural Networks
- 순환 신경망(Recurrent Neural Network, RNN)은 숨겨진 상태(hidden state) 와 선택적 출력(output) 로 구성되며, 가변 길이의 입력 시퀀스 = (, ..., ) 에 대해 동작한다. RNN의 숨겨진 상태 는 매 시점(time step) 에서 다음과 같이 업데이트된다.
-
여기서 는 비선형 활성화 함수(activation function)로, 단순한 로지스틱 시그모이드(sigmoid) 함수부터 LSTM과 같은 복잡한 형태까지 가능하다.
-
RNN은 다음에 올 기호를 예측하는 방식으로 학습하여 시퀀스 전체의 확률 분포를 학습할 수 있다. 즉, 매 시점에서 다음 기호 x_t의 조건부 확률 분포를 예측하는 방식이다.
- 소프트맥스(softmax) 활성화 함수를 사용하여 다항 분포(multinomial distribution)를 출력할 수 있으며, 이를 기반으로 새로운 시퀀스를 생성할 수도 있다.
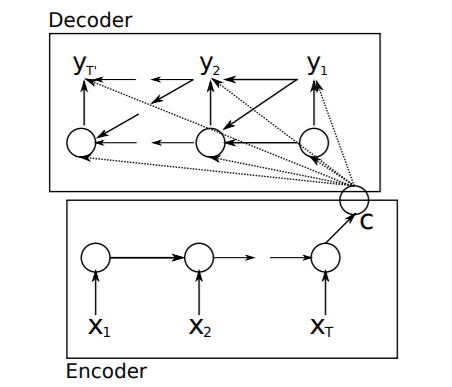
-
이 그림에서 Sequence-to-Sequence (Seq2Seq) 모델의 구조를 나타내며, 주로 기계 번역 등의 자연어 처리(NLP) 작업에 사용된다.
-
Encoder는 입력 시퀀스 를 처리하여 컨텍스트 벡터 를 생성한다.
-
Decoder는 이 컨텍스트 벡터를 기반으로 출력 시퀀스 를 생성하며, 일반적으로 어텐션 메커니즘(점선 화살표)을 포함할 수 있다.
2.2 RNN Encoder–Decoder
- 이 모델은 확률적 관점에서 하나의 가변 길이 시퀀스를 조건으로 또 다른 가변 길이 시퀀스의 조건부 확률 분포를 학습하는 방식이다.
-
인코더(Encoder):
입력 시퀀스를 순차적으로 읽고(hidden state를 갱신하며), 마지막에 전체 입력 시퀀스를 요약하는 벡터 를 생성한다. -
디코더(Decoder):
디코더는 다시 이 벡터 를 기반으로 출력 시퀀스를 생성한다.
단, 기존 RNN과 달리 출력값 와 숨겨진 상태 는 이전 출력 및 인코더의 요약 벡터 에도 의존한다.
(여기서 와 는 각각 활성화 함수이며,
g는 확률 분포를 생성해야 하므로 softmax와 같은 함수를 사용함)
- 인코더와 디코더는 조건부 로그 가능도(conditional log-likelihood)를 최대화하도록 함께 학습되며, 경사 하강법(gradient-based algorithm)을 통해 모델 파라미터 𝜃를 최적화한다.
- 훈련이 끝난 후, 모델은 입력 시퀀스를 기반으로 새로운 출력 시퀀스를 생성하거나, 주어진 입력-출력 쌍의 일치 정도를 확률 로 평가하는 데 사용할 수 있다.
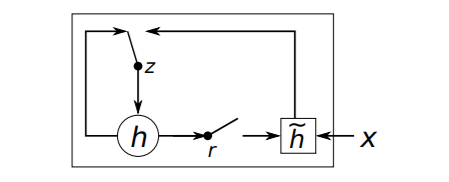
-
GRU는 LSTM과 유사하지만 구조가 더 간결하며, 두 개의 게이트(리셋 게이트 와 업데이트 게이트 )를 사용하여 장기 의존성을 학습한다.
-
: 이전 타임스텝의 은닉 상태, : 후보 은닉 상태,
(Reset gate): 이전 은닉 상태를 얼마나 반영할지를 조절,
(Update gate): 이전 상태를 얼마나 유지할지를 결정 -
GRU는 LSTM보다 계산량이 적고 학습 속도가 빠르며, 시퀀스 데이터를 다루는 데 효과적이다.
2.3 Hidden Unit that Adaptively Remembers and Forgets
-
LSTM은 메모리 셀(memory cell)과 4개의 게이트(gating unit)를 사용하지만, 제안된 유닛은 2개의 게이트(reset gate, update gate)만을 사용하여 더 간단한 연산 구조를 가진다.
-
Reset Gate (리셋 게이트)
- Update Gate (업데이트 게이트)
- 최종 은닉 상태 ℎ𝑡
-
여기서 ℎ~𝑡 는 새로운 후보 상태로, 리셋 게이트를 고려하여 계산됨.
-
가 1에 가까우면 이전 은닉 상태를 유지하고, 0에 가까우면 새로운 정보를 받아들임.
3 Statistical Machine Translation
통계적 기계 번역(SMT) 시스템에서의 목표
-
일반적으로 사용되는 통계적 기계 번역(SMT, Statistical Machine Translation) 시스템에서, 번역기의 목표(특히 디코더의 역할)는 주어진 원문 문장 에 대해 최적의 번역문 를 찾는 것이다. 이를 수식으로 표현하면 다음과 같다.
-
오른쪽 항의 첫 번째 요소 는 번역 모델(Translation Model) 을 의미한다.
- 그러나 실제로 대부분의 SMT 시스템에서는 로그-선형 모델(log-linear model) 을 사용하여 를 다음과 같이 모델링한다.
- 여기서 과 은 각각 n번째 특성(feature)과 그 가중치(weight)를 의미한다. 는 가중치에 영향을 받지 않는 정규화 상수이다. 이 가중치들은 BLEU 점수를 최대화하는 방식으로 최적화된다.
4 Experiments
-
영어/프랑스어 번역 작업에서 다양한 데이터와 방법을 사용하여 성능을 평가함
-
RNN Encoder-Decoder는 1000개의 은닉 유닛과 제안된 게이트를 사용, 7-그램 모델과 비교됨
-
CSLM을 사용한 전통적인 언어 모델도 실험, 훈련 후 퍼플렉시티 45.80 달성함
-
RNN Encoder-Decoder가 기존 번역 모델보다 더 적합한 구문 쌍 점수를 제공함
-
CSLM과 RNN Encoder-Decoder를 조합하여 성능을 개선한 결과가 나옴
5 Conclusion
-
RNN Encoder–Decoder 모델은 임의 길이의 시퀀스를 다른 시퀀스로 변환할 수 있음
-
리셋 게이트랑 업데이트 게이트로 은닉 유닛의 기억과 잊어버림을 조절함
-
기계 번역 성능 개선에 기여했고, 기존 신경망 기법과도 잘 맞음
-
앞으로 문구 제안이나 음성 인식 등 다양한 응용 분야로 확장 가능함
