Can we remove policy gradient completely?
YES!
Aπ(st,at) : at가 다른 π에 따른 average action보다 얼마나 나은지에 대한 정보
복기해보자면 A(s,a)=Q(s,a)−V(s)로
V는 avrage action, Q와 V는 whether action is a or not만 다름
그러면
argmaxatAπ(st,at): π를 따를 때, st에서의 최고의 action
이는 basicly means policy ⇒ policy 대신 사용!
따라서 forget policies, let's just do argmaxatAπ(st,at)!
이때,
π′(at∣st)={10if at=argmaxatAπ(st,at)otherwise
1과 0은 각각 probability
as good as π (probably better)
이렇게 해가지고, 하나만 가지고 actor-critic algorithm이 작동할 수 있도록 변경됨!
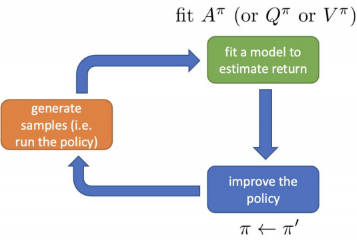
Policy iteration
High level idea
policy iteration algorithm
- evaluate Aπ(s,a)
how to do this?
- set π→π′
π : theoritical policy
π′ : implicit policy
π′(at∣st)={10if at=argmaxatAπ(st,at)otherwise
as before: Aπ(s,a)=r(s,a)+γE[Vπ(s′)]−Vπ(s)s′=st+1
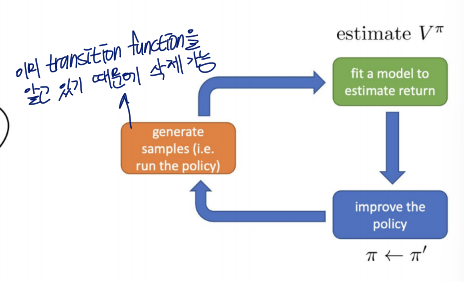
Dynamic Programing
one way to evaluate Vπ
advantage function을 구하는 것은 value function을 구하는 것으로 formate될 수 있음
Assumption
we know
- p(s′∣s,a)
transition function (→ assume we know the transition probability)
원래 model-free RL은 transition function이 없음
→ model based function이라 가정 ⇒ environment =의 dynamic을 알고 있음
- s and a are noth discrete (and small)
dp 사용을 위한 가정
Example
- 16 states
- 4 actions
up, down, left, right
T is 16×16×4 tensor
bootstrapped update: Vπ(s)←Ea∼π(a∣s)[r(s,a)+γEs′∼p(s′∣s,a)[Vπ(s′)]]
- Ea∼π(a∣s) : deterministic policy이므로 걷어낼 수 있음
- Vπ(s′)에는 just use the current estimate
π′(at∣st)={10if at=argmaxatAπ(st,at)otherwise→ deterministic policy π(s)=a
deterministic policy π(s)=a : state에 따라 정해진 a들 존재하여 변화X
simplified: Vπ←r(s,π(s))+γEs′∼p(s′∣s,π(s))[Vπ(s′)]
policy iteration with dynamic programming
policy iteration
- evaluate Vπ(s)
- set π←π′
π′(at∣st)={10if at=argmaxatAπ(st,at)otherwise
policy evaluation
Vπ←r(s,π(s))+γEs′∼p(s′∣s,π(s))[Vπ(s′)]
이걸 사용해서 위의 iteration의 1 수행
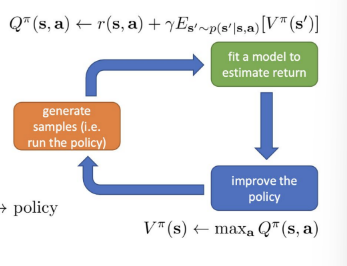
Simplify A function
π′(at∣st)={10if at=argmaxatAπ(st,at)otherwise
- argmaxatAπ(st,at)=r(s,a)+γE[Vπ(s′)]−Vπ(s)로, too much equations!
- Vπ(s)는 constant로 ignore 가능
→argmaxatAπ(st,at)=argmaxatQπ(st,at)
- Qπ(s,a)=r(s,a)+γE[Vπ(s′)] (a bit simpler)
skip the policy and compute values directly!
⇒ value iteration algorithm
- set Q(s,a)←r(s,a)+γE[V(s′)]
estimate all Q(s,a) value
- set V(s)←maxaQ(s,a)
V는 expected reward at state s. argmax 통해 update
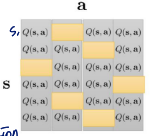
이렇게 행이 state이므로 각 행마다의 최댓값을 선택해서 V update