강화학습 수업정리
1.1. Supervised Learning of Behaviors
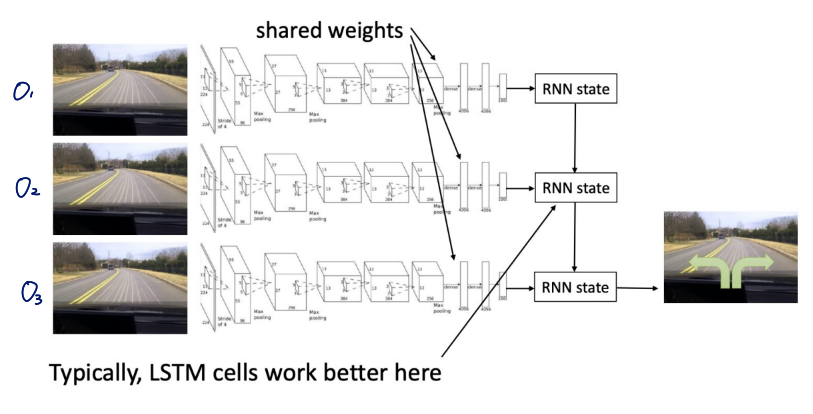
Terminology & notation $s_t$ : state Markov property 만족 $o_t$ : observation how the agent see the world Markov property를 만족하지 않음 $a_t$ : action $\pi\t
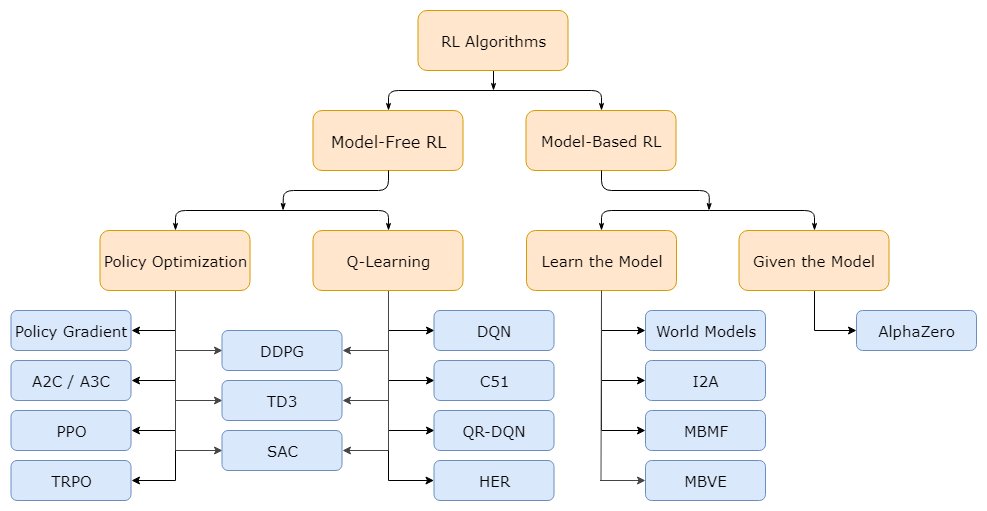
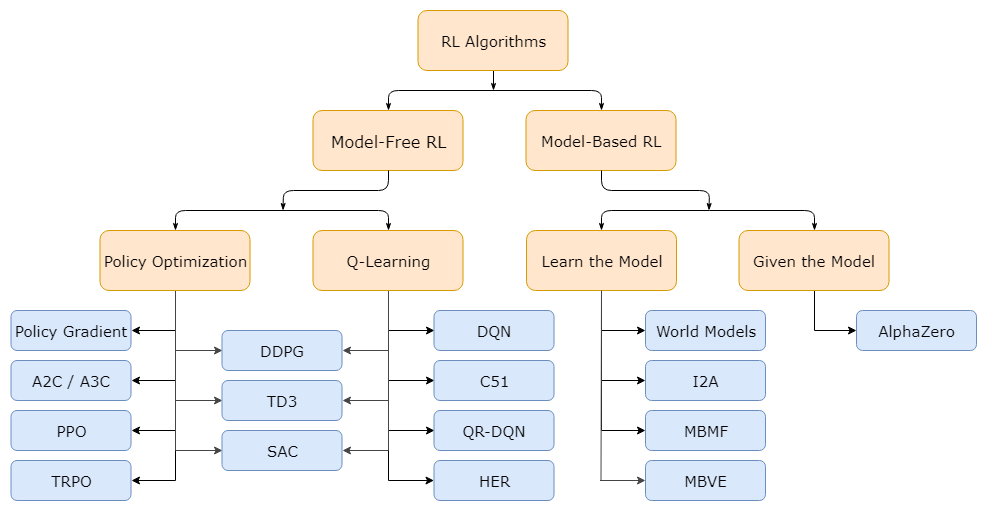
2.2. Introduction of Reinforcement Learning (Key Concepts of RL)

Recap Basic of Reinforcement Learning Input given environment which provides numerical reward signal, and agent which act inside of that environment O
3.3. RL algorithms: Policy-based RL
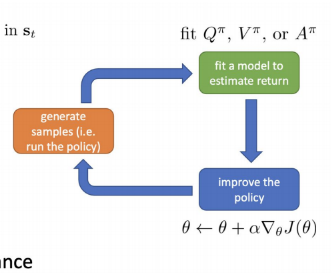
inputagent, environmentagent take the state($st$)$\\rightarrow$ agent take action$\\rightarrow$ action에 따라 환경(state $s{t+1}$) 변화objective functionExpe
4.4. Off-policy Policy Gradient
여기서Policy Optimization : on-policy RLQ-Learning : off-policy RLsample ${\\gamma^i}$ from $\\pi (a_t|s_t)$ (run it on the robot)skip 불가능!$\\bigtriangle
5.5. Actor-Critic Algorithm
Advanced Policy Gradient Progress beyond Vanilla Policy Gradient Natural Policy Gradient: REINFORCE PPO (Proximal Policy Optimization) TRPO (Trust Reg
6.6. Actor-Critic Design Decisions
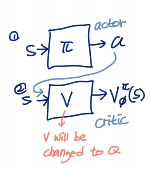
take action $a\\sim \\pi\_\\theta(a|s)$, get $(s,a,s',r)$update $\\hat{V}\\phi^\\pi$ using target $r+\\gamma\\hat{V}\\phi^\\pi(s')$evaluate $\\hat{A}^
7.7. Value Function Methods
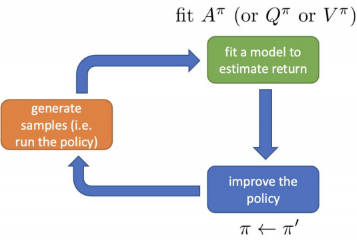
YES!$A^\\pi(s_t,a_t)$ : $a_t$가 다른 $\\pi$에 따른 average action보다 얼마나 나은지에 대한 정보복기해보자면 $A(s,a) = Q(s,a)-V(s)$로 V는 avrage action, Q와 V는 whether action is a