Actor-critic Design Decisions
Architecture Design
online actor-crotoc algorithm
- take action , get
- update using target
- evaluate
여기서 학습해야 하는 것은 두 개
- policy function : actor
- value function : critic
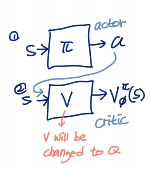
이 두 개를 학습하기 위한 디자인은 두 개가 있는데..
1. two network design
two different networks에서 와 각각 학습
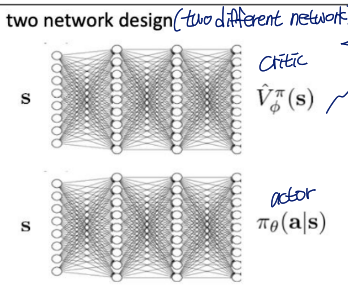
- 장점
simple & stable - 단점
no shared features between actor & critic
두 network 모두 s를 input으로 받는다는 공통점이 있지만 shared feature 없음
2. shared network design
하나의 network로 두 개 모두 학습
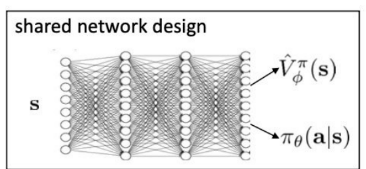
- 장점
parameter memory 절감
학습이 더 빨라지기도 함 - 단점
unstable training
Online Actor-critic in practice
online actor-critic algorithm의 과정에서
- update using target
를 수행할 때에는 works best with a batch (e.g., parallel workers)
예를 들어서 batch size가 16이면 16 workers를 사용 16 transition per 1 time 생성 가능
이때, worker를 사용하는 방법은 두 가지가 있음
-
synchronized parallel actor-critic
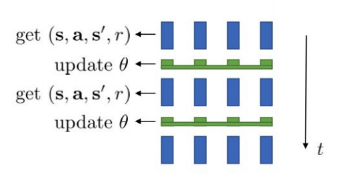
모든 worker가 일을 끝낼 때까지 이미 일을 끝낸 worker도 다음 step으로 넘어가지 못함
parameter를 optimize할 때에는 loss의 평균 사용 -
asynchronous parallel actor-critic
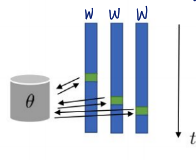
각 에이전트가 독립적으로 학습하고 비동기적으로 업데이트(worker들은 parameter 공유)
synchronized 때보다 학습 더 빨라짐
그러나 일관적이지 못할 수도 있다는 단점 보유
Can we remove the on-policy assumption entirely?
form a batch by using old previously seen transitions
이전에 경험한 state, action, reward, next state의 튜플(transition)을 사용하여 배치 형성
Off-Policy Learning은 현재의 정책이 아닌 이전의 정책에서 수집된 경험을 사용할 수 있기 때문에, 다양한 정책에 대한 학습이 가능해짐
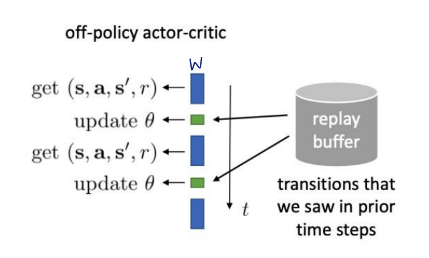
replay buffer에 과거의 transitions를 저장하고 후에 꺼내서 사용
그러나 이걸 진행하면 알고리즘에 붕괴가 발생함
이전의 transition은 old policy를 따르는 것인데, V에서는 현재의 policy를 따르는 transition을 사용해야 함. 따라서 gradient에 붕괴 발생
A should be sampled by current policy. 그러나 replay buffer에서 꺼낸 transition은 옛날 policy에서 sampled 된 것

이런 느낌
Fixing the policy update
V에는 A가 current policy를 따라야 한다는 assuption이 있기 때문에 이러한 가정이 없는 Q로 대체
여기서 는 current policy를 따라야 함
따라서 알고리즘에서 3번은 이렇게 변함
- update using targets for each
은 not from replay buffer R!
이렇게 a는 current policy에서 예측하도록 만듦
replay buffer에는 s, r만 있어도 되게 됨
그리고 policy의 loss function에도 변화 생김
policy에서의 a도 replay buffer R에도 온 것 아님
: higher variance, but convenient
why is higher variance OK here? - sample 효율성, exploration,...
Some implementation details
위에서 바뀐 부분들을 알고리즘에 적용하면 최종적으로 이렇게 됨
- take action , get
- sample a batch from buffer R
- update using targets for each
lots of fancier ways to fit Q-functions
could also use reparameterization trick to better estimate the integral
Q function의 input은 policy network의 output인 action과 replay buffer에서 나온 state
