📄A Unified Approach to Interpreting Model Predictions
written by Scott M.Lundberg and Su-In Lee
Introduction
모델이 예측한 것에 대한 이유(어떤 판단을 왜 내렸는지에 대한 투명한 설명)를 아는 것은 중요함, 그러나 모델이 복잡해질수록 이유를 아는 것은 더욱 어려워짐(accuracy와 interpretable의 trade-off)
본 논문은 복잡한 모델이 어떤 예측 결과를 내놓았을 때, 이것이 어떻게 예측한 것인지 해석하기 위한 unified 프레임워크(설명모델)인 SHAP에 대하여 소개함
additive feature attribution methods
Explanation model을 통해 정의됨
모델을 단순화시켜 보는 방법 사용하여 설명 가능하도록 함
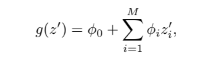
-
LIME
모델이 현재 데이터의 어떤 영역을 집중 분석했으며 어떤 영역을 분류 근거로 사용했는지 알려주는 기법
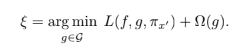
-
DeepLIFT
최근 딥러닝을 위한 재귀적 예측 설명 방법 -
Layer-Wise Relevance Propagation
Deep Network의 예측 해석 방법 -
Classic Sharpley Value Estimation
전체 성과를 창출하는 데 각 참여자가 얼마나 공헌했는지를 수치로 표현하는 기법
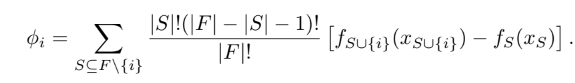
Simple Properties Uniquely Determine Additive Feature Attributions
additive feature attribution methods는 three simple properties를 가진 single unique solution이 존재함
-
Local accuracy
단순화된 모델의 output과 original 모델의 output이 일치해야 함 -
Missingness
x_i'=0은 원래 input x에 feature i가 존재하지 ㅇ낳음을 의미, 따라서 feature i의 기여도 또한 0이 되어야 함 -
Consistency
모델이 변경되었을 때, 단순화된 input x'의 기여도가 증가 또는 유지되었다면 해당 input의 기여도는 감소되어서는 안됨
3개의 property들을 모두 따르며, additive feature attribution method의 정의를 만족하는 설명 모델
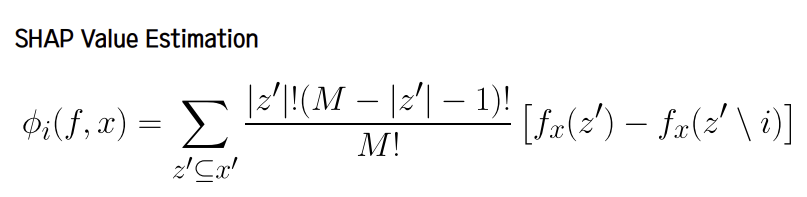
SHAP Values
-
Kernel SHAP
Linear LIME + Sharpley values -
Linear SHAP
for linear models, input의 독립성을 가정하면 SHAP values can be approximated directly from the model's weight coefficients -
Low-Order SHAP
approximation fo the conditional expectations 선택 시 더 효율적 -
Max SHAP
Shapley 값의 순열 공식 사용하여 각 input이 다른 모든 input 대비 최대값을 증가시킬 확률 계산 가능 -
Deep SHAP
DeepLIFT + Shapley values
Advantages
- Kernal SHAP 사용 시 계산 효율성 향상 가능, LIME과 비교했을 때 보다 높은 local accuracy와 consistency를 보임
- 다른 방법보다 SHAP이 사람의 직관과 더 잘 부합하는 좋은 설명을 내놓음을 user study를 통해 확인
- Deep SHAP을 사용하면 이미지에서 클래스별 차이를 더 잘 설명할 수 있음
