📄Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
written by Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
Warning: This is not an official technical report from OpenAI
Introduction
2024년 발표된 OpenAI의 Sora는 text-to-video generative AI model이다. Sora는 텍스트 프롬프트로부터 realistic or imaginative한 약 1분의 영상들을 제작할 수 있다.
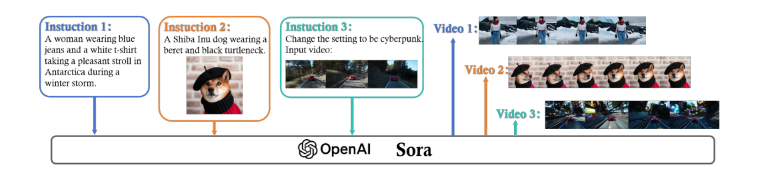
본 논문에서는 이러한 Sora의 background, technology, application 분야, 한계와 opportunities에 대한 discussion을 할 것이다.
Technology
diffusion transformer를 사용하여 LLMs(Large Language Models)와 같이 parse text and comprehend complex user instruction 가능
space time latent patches 사용하여 video 생성이 computationally efficient하도록 함
text-to-video 생성은 diffusion transformer model을 사용하여 frame filled with visual noise에서 noise를 반복적으로 제거 + 텍스트에 주어진 것에 따른 디테일들 추가를 통해 진행
framework of Sora
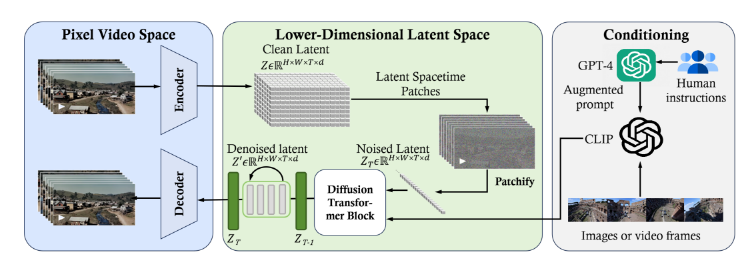
- time-space compressor가 우선적으로 original video를 latent space로 map
- ViT processes the tokenized latent representation and outputs the denoised latent representation
- CLIP-like conditioning mechanism receives LLM-argumented user instructions and potentially visual prompts to guide the diffusion model to generate styled or themed video
Capabilities
- Improving simulation abilities
다양한 각도의 상황을 학습하여 성능 향상 - Boosting creativity
아이디어를 더욱 빠르게 디자인할 수 있도록 도와줌 - Driving educational innovations
학습할 때 중요한 시각적 자료들을 빠르게, 적절하게 생성해냄으로써 학생들의 집중력+이해도 향상 가능 - Enhancing Accessibility
visual domain의 접근성 향상 - Fostering emerging applications
다양한 분야에서 사용될 수 있음
Limitations
limitations
- 더 세밀한 묘사를 위한 학습 필요
- 윤리적 문제 존재
꼭지
윤리적 관련 문제를 너무 나이브하게 생각하는 것 아닌지?
