📄BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
written by Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
Introduction
유저의 과거 행동에서 다이나믹한 선호도를 찾는 것은 추천시스템에서 중요
기존의 unidirectional recommendation model들은 한계점을 지니고 있음
- restrict the power of hidden representation in users' behavior sequences
- often assume a rigidly ordered sequence which is not always practical
본 논문에서는 양방향으로 학습(+Cloze 채택)함으로써 이러한 한계점을 극복하는 추천 모델인 BERT4Rec에 대하여 소개함
BERT4Rec
1. Problem Statement
-
set of users
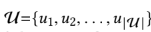
-
set of items
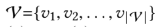
-
interaction sequence
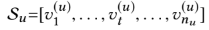
-
이들을 종합해서 probability 도출
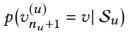
유저가 아이템을 좋아할 확률
2. Model Architecture
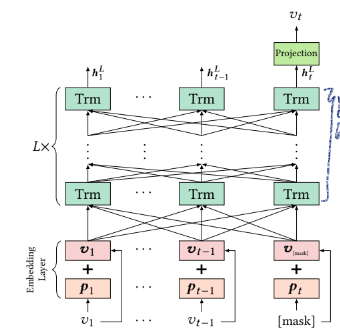
embedding layer + transformar layers + output layer로 구성되어 있음 -
transformar layer
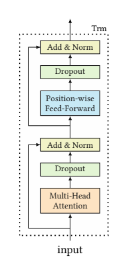
multi-head self-attention + position-wise feed-forward network-
multi-head self-attention
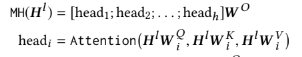
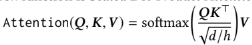
head 별로 각기 다른 어텐션이 가능하도록 transpose 후 각각 query, key, value attention에 통과, transpose한 후 모든 head들의 어텐션 결과를 합침
query, key, value는 같은 행렬인 Hl을 통해 도출됨 -
position-wise feed-forward network
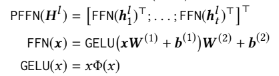
multi head로 각 특성을 학습시킨 후 헤드의 정보를 섞어주는 열할
GeLU 사용
output 도출 역할
-
-
embedding layer
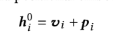
embedding in order to make use of the sequential information of the input -
output layer
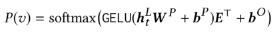
used the shared item embedding matrix in the input and output layer for alleviating overfitting and reducing model size
Model Learning
1. Training
jointly conditioning on both left and right context in a bidirectional model would cause the final output representation of each item to contain the information of the target item.
→ makes predicting the future become trivial and the network would not learn anything useful
이러한 문제 해결 위해 Cloze task 사용
학습 중 몇몇 토큰을 mask한 후 이를 예측하도록 함(p로 얼마만큼 마스킹할 건지 비율 정함) → 훈련샘플 많아져서 성능 향상됨
2. Testing
training 과정 중 사용한 미스매치를 predict 과정에서도 사용할 수 있기 위하여 맨 마지막 token 다음에 mask 토큰 추가하여 예측 진행
성능 좋아지라고 훈련 값에 끝에 값을 마스킹한 것도 추가함
Conclusion
Cloze task를 사용하는 bidirectional model을 훈련시킨 결과로 real-world 데이터를 사용하여 실험해 보았을 때 state-of-the-art baselines를 능가하는 성능을 보여줌
훈련속도 느리고, BERT4Rec이 항상 좋은 것은 아니라는 반박 논문 있음
