📄Deep Neural Networks for YouTube Recommendations
written by Paul Convington, Jay Adams, Emre Sargin
Introduction
유튜브는 비디오 콘텐츠를 제작하고, 공유하고, 발견하는 거대 플랫폼으로써 추천 시스템은 수십억 명의 사용자들이 수많은 영상들 중 자신에게 알맞은 영상을 찾게 해야 함.
이러한 유튜브에서는 세 개의 큰 과제(challenge)가 존재 함
1. Scale
방대한 problems에서도 효율적으로 알고리즘이 작동해야 함
2. Freshness
사용자의 이전 활동과 새로 update된 콘텐츠들을 잘 맞추어 추천해야 함(이전의 영상에만 치중되면 안 됨)
3. Noise
algorithms need to be robust to particular characteristics of the training data
본 논문에서는 이러한 점들을 해결하도록 설계된 딥러닝 모델을 소개한다. 딥러닝 모델은
- candidate generation network
미래에 볼 후보군 생성 - ranking network
1에서 나온 후보군들의 랭킹 정하기
이 두 NN으로 구성되어 있다.
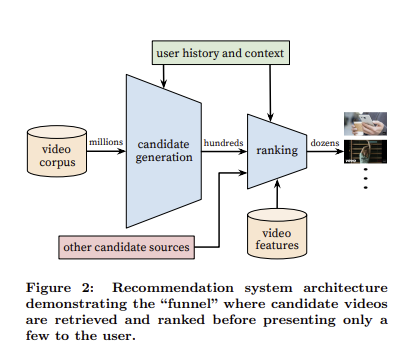
더하여 해당 모델을 만들어가며 얻은 점들에 대하여도 소개한다.
Candidate Generation
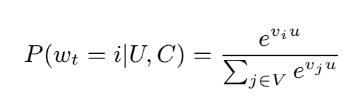
wt=video, V=video set(corpus), U=user, C=context, u=embedding of user, vj=embeddings of each video, N=# of videos
여기서 DNN은 u와 구별에 유용한 context를 학습하게됨(with softmax classifier)
그리고 explicit feedback(e.g.thums up/down)은 제외하고 implicit feedback만을 사용함.
Model Architecture
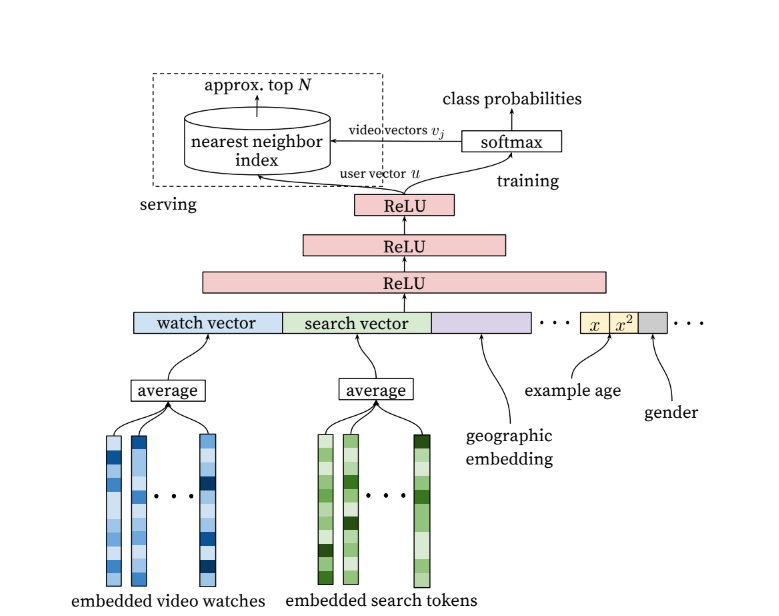
network가 fixed-sized dense input을 필요로 하기 때문에 여러 임베딩을 사용하여 조건을 만족하도록 함. 이때, 임베딩법들은 normal gradient descent backpropagation update를 통해 학습됨.
ex) user's watch history
다양한 길이의 비디오 ID 연속이 임베딩을 통해 mapped to a dense vector representation
features: 검색기록, 시청기록, 사용자의 위치, 성별, 기기가 무엇인지, 나이 .....
tokenize와 같은 방법들을 사용하여 전처리
시청자가 각 영상을 본 날짜를 고려하여 age를 적용하기도 함("example age" feature)
보고 싶은 비디오를 시청한경우 긍정적 코멘트를 다는 것과 같은 부가적 요소들로 모델 성능을 평가함(A/B testing). 그러나 이러한 방법은 측정하기 어려움.
실험적으로 진행한 결과, feature와 depth가 깊어질수록 precision값이 상승함
Ranking
role: use impression data to specialize and calibrate candidate predictions for the particular user interface
the list of vieo를 logistic regression을 사용하여 점수를 매긴 후, 이에 기반하여 sort를 진행하고 사용자에게 return. final ranking objective는 constantly being tuned based on live A/B testing result(generally a simple function of expected watch time per impression)
feature
most important signals are those that describe a user's previous interation with the item itself and other similar items, matching others' experience in ranking ads.
이 continuous features는 powerful함(they generalize well across disparate items)
또한 후보 비디오 중 어떤 것들이 선택되었는지, score은 얼마인지, 추천했는데 안 보았는지에 대한 것들도 중요함
categorical feature들은 NN에 알맞게 dense representation함
- vocabularies : simple look-up tables built by passing over the data once before training
- out-of-vocabulary : simply mapped to the zero embedding
같은 ID space를 갖는 feature들은 underlying embeddings를 공유함
→improving generalization, train 속도 향상, 메모리 절약
Model Architecture
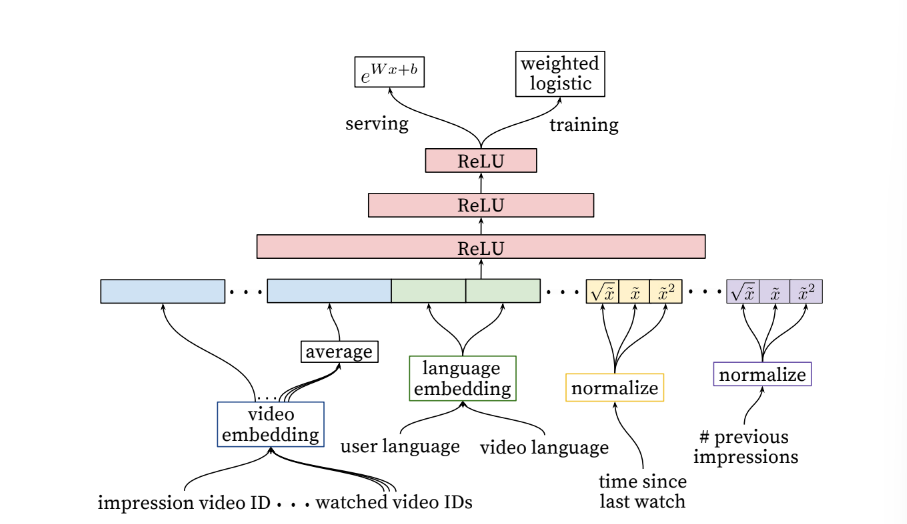
꼭지(의문점)
ranking model에서 score에 따라 비디오를 sort할 때 어떤 sort방법을 사용했을까? 더하여 이때의 비디오 데이터에 대한 자료구조는 어떤 것을 사용했을까?
