📄Deep reinforcement learning for drone navigation using sensor data
written by Victoria J. Hodge, Richard Hawkins and Rob Alexander
Introduction
빠르고 정확한 센서 분석은 오늘날 사회와 관련된 많은 응용 프로그램에 사용됨
- detection and identification of chemical leaks, gas leaks, forest fires
- disaster monitoring and search
- rescue
- agricultural
- construction
- environmental monitoring
센서는 특정 화학 물질의 농도 or 적외선 or 열화상 수준 측정을 통해 이를 분석하여 anomalies를 탐지
이때, anomalies는 다른 측정된 값들과 현저히 다르게 나타나는 값으로
sensor monitoring application domain에서 anomaly는 추가 조사가 필요한 문제임
sensor monitoring for environments, infrastructure and buildings는 이동 가능하고, 유연하고, 견고하고, 넓은 범위의 환경에 사용 가능해야 함
mobile, flexible, robust and have the ability to be used in a broad range of environments
IoT sensor systems와 같은 수많은 current sensors는 mobility와 flexibility를 만족 못함(static with fixed mountings)
UAVs(unmmaned aerial vehicles) 같은 robotic/autonomous systems 통해 조건 만족하도록 함
이를 통해 사람이 접근하기 어려운 곳으로도 이상 탐지, 수색 및 구조 수행 가능
본 논문에서는 small or microdrones을 위한 drone navigation recommender system을 제안함
larger drones or UGVs에도 사용 가능
작동 및 시각적 측면에서 sat-nav system in a car와 유사
목표 위치(anomaly)에 도달하기 위한 최상의 이동 방향을 추천
본 논문에서의 assumes:
- sensor module은 드론의 underneath에 붙어 있음
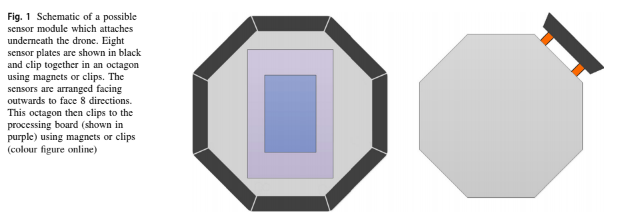
- sensor들의 배열은 anamaly detection application에 적합한 모든 유형의 배열일 수 있음
- sensor data는 location data와 obstacle detection data(from a collision avoidance mechanism)으로 combined되어 있음
anomaly detection process
- anomaly가 어디 있는지 determine
- most anomalous reading을 제공하는 센서 determine
본 논문에서는 recommender software에 집중.
이는 인공지능을 사용하고 anomaly detection software가 anomaly를 탐지한 경우 작동됨
sensor data는 현재 드론의 위치, 장애물 탐지 데이터로 결합되어 있음
이를 이동할 방향 추천을 위한 off-policy deep learning model의 input으로 사용 현재 상황, 주변 환경 및 센서 판독값에 따라 드론의 이동 방향 추천
이때, human pilot and on-board collision avoidance or the drone's autonomous navigation system 허용함으로써 actual naviation and collision avoidance에 집중할 수 있도록 함
본 논문의 recommender AI는 일반적인 환경을 탐색하고, 이전에 본 적이 없는 새로운 환경을 탐색하고, 드론과 온보드 센서에서 얻을 수 있는 최소한의 정보만을 사용하여 탐색할 수 있어야 함
what we know : 드론 위치, 드론 기준 각 방향에 obstacle이 있는지 유무, sensor reading의 방향과 크기
drone은 local 가시성만 가지고 있기 때문에 본 논문의 navigator는 partially observable step-by-step approach with potential for recalculation each step을 사용함. 그리고 developing의 first tep에서는 static environments에 집중하고 explore dynamic environments하지 않음
본 논문의 contributions
-
센서 데이터와 AI를 결합하고 최소한의 정보만 필요로 하는 drone navigation을 위한 새로운 추천 시스템
-
두 가지 deep learnig techniques 결합
- PPO
- LSTM
-
시뮬레이션 환경에서 시스템을 평가하여 실제 테스트로 전환하기 전에 쉽고 철저히 테스트 가능하도록 함
-
FFA(functional failure analysis) 사용하여 시스템의 안전 요구 사항 정의
Reinforcement learning(RL)
먼저, some local navigation approaches를 살펴보자면
- Genetic algorithms
- 부분적으로 observable한 navigation 수행
- 무작위로 생성된 solutions의 population 생성, 자연선택의 원래 통해 유용한 solution sets 선택
- 단점 - local minima에 갇히는 경향
- Fuzzy logic algorithms
- three meta-heuristic algorithms보다 우수한 성능
particle swarm optimization, artifitial bee colony and meta-heuristic Firefly algorithm - 단점 - struggle in dynamic enviroments(바뀐 환경에서 경로를 recompute하는 속도 느림)
- three meta-heuristic algorithms보다 우수한 성능
- Meta-heuristic algorithms
- GAs and swarm intelligence
- can navigate in uncertain environments
- 단점 - 복잡, low-cost 로봇에 적합하지 않음
- GAs and swarm intelligence
- deep classification learning with deep neural networks
- time-consuming
- difficult to accurately label a large enough set of training examples
- deep RL
- key aim
experience-driven learing in the real world가 가능한 adaptive systems 생성
- key aim
RL은 Markov decision process(MDP)
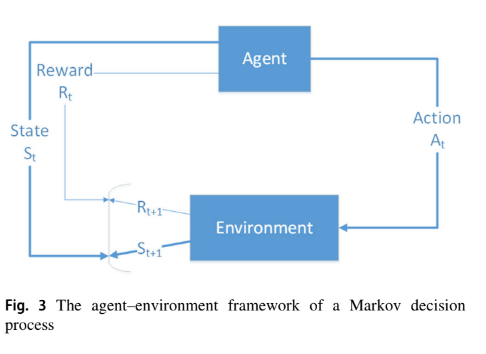
- complexity of the learning task :
exponential with respect to the number of variables used to define a state - 본 논문의 모델은 하나의 agent(four possible directions 중 이동할 방향 하나 선택)만 필요
- transitions는 현재 state와 action에만 depend (Markov assumption)
- instantaneous reward function은 각 transition에 associated되어 있고, optimum transition 평가에 사용됨
- discount factor 은 현재의 reward와 future rewards간의 중요도 차를 두는 것에 사용
- memorylessness
본 논문에서는 drone navigation problem을 Grid-World navigation problem과 유사하게 처리함
알고 있는 값들
- 드론의 GPS 위치
- 드론의 immediate N, E, S, W
- sensor reading in Cartesian coordinates의 방향(x-distance, y-distance)
real world scenario에서는 Magnitude and direction은 polar coordinates to Cartesian coordinates로 변환 가능
본 논문의 drone navigation recommender system은 환경의 일부만 관찰 가능
더 가까이에 있는 obstacles의 위치(무언가에 가려진), 또는 드론의 시야보다 멀리 있는 obstacle을 모름
이에 대한 alternative formulations는 environment를 picture(observation)로 취급함
그리드의 각 셀은 해당 셀의 내용을 나타내는 값인 픽셀에 mapping
{empty, obstacle, goal}
이 방법은 available하지 않은 곳의 정보까지 필요로 하고, 그리드 사이즈를 scale할 수 없음
그러나 본 논문의 formulation은 scalable, adaptable and flexible함
Partially observable MDPs(POMDPs)
local information을 사용하여 훈련하기 위해 사용
POMDP에서, agents는 observation 를 받음
observation's distribution :
observation distribution은 depends on previous action and the current state
observation은 현재 state에 의존하는 state-space model인
{sensor direction, sensor magnitude, N, E, S, W space}와
previously applied action에 mapping되어 표현됨
MDP는 state와 state간의 transition probabilites를 표현함
- policy 는 주어진 state에서 actions의 분포
- policy는 current state에 대한 agent의 행동을 fully define
- 주어진 state에 맞춰 action 생성
- action 실행 후 reward 생성
- 목표 : optimal policy 생성
optimal policy는 reward over all states를 최대화시킴
본 논문의 모델에는 Value learning 말고, policy learning을 사용함
value learning은 학습 속도 느림
Policy gradients learning
deep RL algorithms의 한 부분집합
policy의 gradient를 ascending하며 policy quality의 local maximum을 찾음
robust하지만 variance가 높음
variance를 낮추기 위해 unbiased estimates of the gradient 사용하고
several episodes의 average를 baseline으로 사용하여 subtract함
더하여 local minima를 최소화하기 위하여 trust regions를 사용함
updated policies가 이전 policies에 대해 low deviation을 갖는 것을 보장함으로써 likelihood의 very poor update를 줄임
이때, KL-divergence를 이용하여 trust region(proposed policy)에 얼마나 벗어나 있는지 확인함
그러나 이 방법은 second order gradients 계산을 필요로 하여 적용 가능성이 제한됨
이를 극복하기 위해 PPO 사용
- 오직 first-order gradient information만 필요
- executes multiple epochs of stochastic gradient descent to perform each policy update
it performs a trust region update in a way that is compatible with stochastic gradient descent
adaptive update의 필요성이 사라지며 알고리즘 간소화
Proximal policy optimisation (PPO) algorithm
policy optimisation을 새로운 examples 수집과 interleaves함
PPO는 clipped importance ratio를 사용한 lower bound를 form한 KL penalty를 optimise함
: exploration을 boost하는 entropy factor. hyper-parameter로 set to 0.1 or 0.2.
optimise할 때, batch of navigation examples와 minibatch stochastic gradient descent to maximise the objective를 사용함
이를 통해 KL penalty, adaptive updates를 만드는 것에 대한 필요 사라짐
이 과정은 updated policy와 old policy 간 reliable update를 찾아냄
이를 통해 너무 greedy해지는 것과 좋은 approximation에서 벗어나도록 하는 큰 update를 막을 수 있음
PPO는 TRPO의 성능을 유지하면서 비용이 저렴해서 인기 많음
Models and system architecture
- design : Unity 3-D's ML-agents framework
- develop and test the simulations prior to real-world deployment
- ML-agent
- front-end : Unity 3-D C# development framework
- middleware interfacing : Google TensorFlow
- backend : Python
본 논문에서는 드론의 고도는 고려하지 않고 2-D navigation에 집중함
따라서, anomaly detection problem은 deterministic하고 single-agent search이고 POMDP problem impemented using Grid-World in Unity 3-D ML-agents임
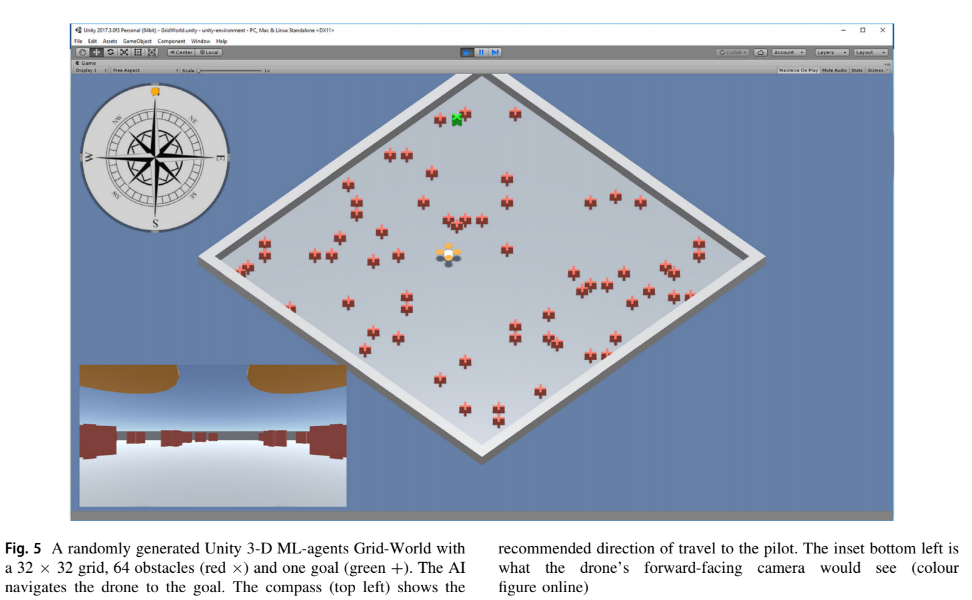
Agents
simulation에서 agent는 drone으로 규정된 action을 수행하고 cumulative rewards를 할당함
one brain과 linked되어 있음
state space는 길이가 6인 벡터로, 내용은 인접한 그리드 셀들(N, E, S, W)과 anomaly까지의 x-distance, y-distance
이는 compact하고 scalable하며 realistically achieved함
리워드는 목적지에 도달하면 +1, obstacle에 collide되면 -1
Brains
agent는 intelligence를 제공하고 action을 결정하는 brain에 link됨
brain은 agent가 결정할 수 있도록 하는 logic을 제공함
이는 각 instance에서 최고의 action을 take하는 것을 결정해줌
brain은 OpenAI에서 개발된 PPO 알고리즘을 사용함
PPO는 TensorFlow를 통해 구현되었고, separate Python process에서 돌아감
input : state-space representation and the set of possible actions
output : action to maximise the reward
Academy
environment의 요소로 decision-making process를 조율함
brain(logic)과 actual Python TensorFlow implementation of the brain을 연결
Configuration
-
state 표현할 때, 이를 N, E, S, W, d(x), d(y)로 표현해야지 최고의 결과가 나옴
-
그리드 크기와 관련된 다양한 스케일링 요소를 사용하여 스텝 페널티를 구한 다양한 스텝 리워드는
이때 제일 좋게 나왔음 -
hyper-parameter setting은 appendix 참조
하나의 obstacle이 있는 경우로 학습하면 complex obstacles인 경우 struggle
complex obstacles를 학습하면 simple한 경우에 비효율적으로 목적지에 도달
이는 agent가 일반적이어야 하고 다양한 환경을 다룰 수 있어야 한다는 desire를 무효화함. 이를 해결하기 위해 step-by-step(curriculum) learning을 사용함
Curriculum learning
이전 task에서 학습한 지식을 확용하여 expect를 수행할 수 있는 방법
simulator에서 시각적 렌더링으로 학습을 시작한 다음 학습된 모델을 실제 응용 프로그램에서 미세 조정할 수 있기 때문에 curriculum learning을 사용함
간단한 task에서 점차적으로 어려운 task를 학습하도록 함
obstacle 개수를 1, 4, 8, 16, 32 순서로 늘림 (모두 16x16 grid)
학습이 끝났을 때, 드론은 여전히 obstacle이 1개인 경우의 대처법도 기억하고 있음
더하여, 본 논문에서는 incremental curriculum learning으로 불리는 adaptive curriculum learning을 사용함
이는 user가 optimise training하기 위해 각 lesson의 number of iterations를 adapt할 수 있도록 함
충분히 학습된 경우 학습을 종료하고, 아닌 경우 학습을 더 시킬 수 있음
그리고 본 연구의 모델에는 mean final reward가 최고의 결과를 만들어낸다는 것을 발견함
다른 방법들은 over-train 또는 under-train이 되어 poor generalisation capabilities를 leading함
따라서 mean final reward를 사용
- iteration 개수 지정
- 지정한 만큼 학습하면, n개마다 training iteration의 평균 리워드 계산
- reward가 계속 오르고 있으면 더 학습(수 지정해야 됨)
- reward가 stable한 경우 학습종료
Memory
MDPs가 memoryless하다는 특징은 오목한 obstacles(막다른 길)를 만날 때 문제가 됨. 이전 일들을 기억 못하기 때문에 계속 제자리를 빙빙 돌게 될 수 있음
따라서 memory를 추가하기 위해 LSTM을 사용함
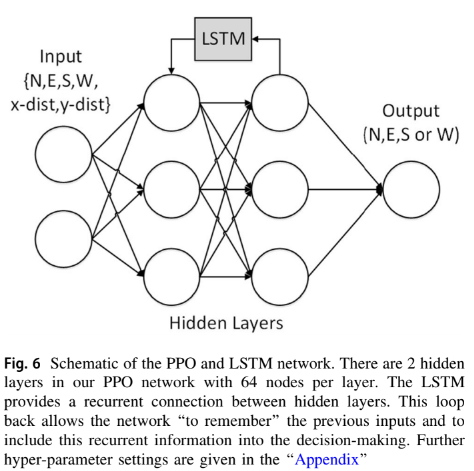
LSTM에 대한 설명들은 생략
sequence의 length는 agent가 기억해야 하는 step의 개수로, 이를 충분히 설정해야지 오래 전의 것도 기억을 할 수 있음
그러나 sequence가 길어질수록 학습시간이 길어짐
Training
- TesorFlow model은 Unity environment와 분리되어 있고 소켓을 통해 소통함
- brain은 50million training episodes를 통해 학습
(using the incremental curriculum learning) - 각 episode는 separate navigation tasks로 Unity 3-D에서 생성됨
- obstacles는 랜덤으로 생성
Simulation operation
- 훈련이 끝나면 이를 사용할 수 있도록 Internal mode로 변경
- Unity는 agent의 현재 state를 stored TensorFlow에 전달
- 저장된 모델은 그에 맞는 최선의 action 반환
- 이때, 더이상 학습은 없기 때문에 model graph는 frozen되어 있음
- setup을 바꾸면 다시 학습 가능
Evaluations
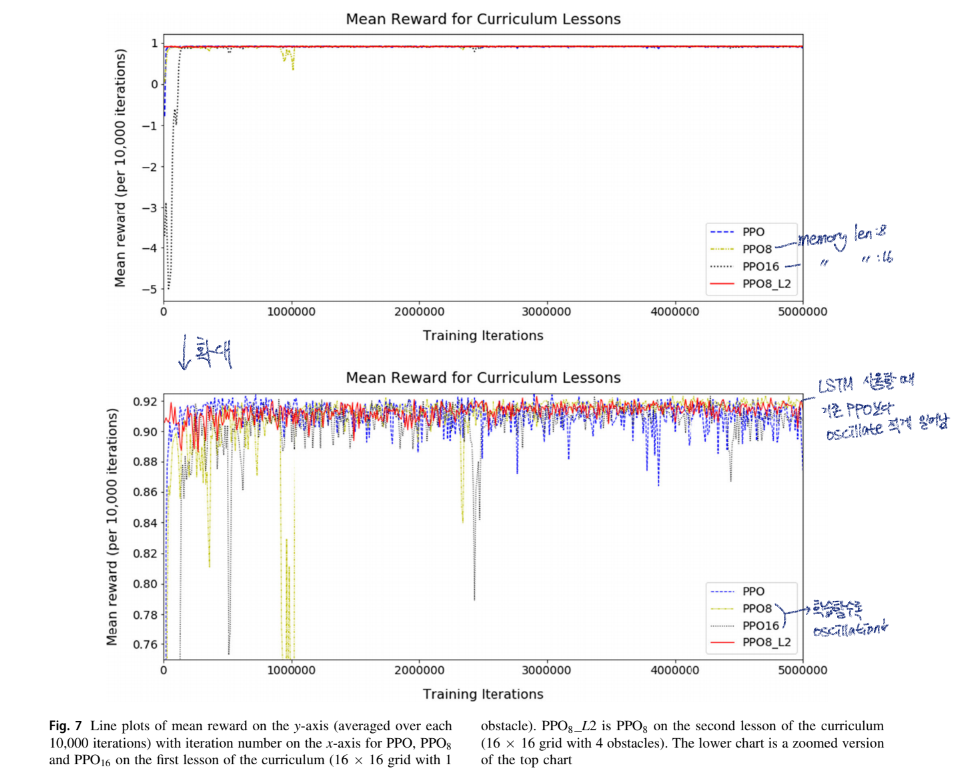
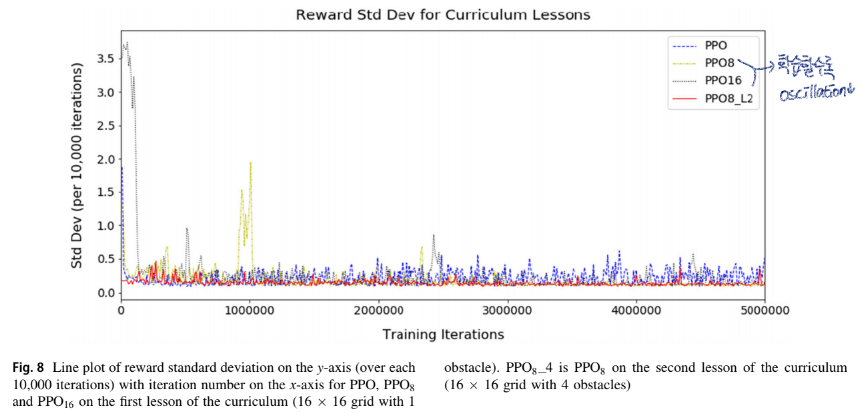
-
memory의 길이가 길수록 학습 시간이 오래 소요됨
-
PPO16은 0.9 reward까지 가장 오랜 시간이 걸림
-
PPO8은 3M train 후 가장 작은 oscillation이 일어남
-
PPO8_L2는 이미 한번 학습을 했었기 때문에 oscillation이 가작 작게 일어남
AI의 정착 시간에 따라 각 수업의 길이를 변경하고 학습을 위한 충분한 훈련을 받도록 하기 위해 점진적인 커리큘럼 학습을 사용하는 이유 -
PPO with memory는 충돌하는 경향이 있으며 드물게 고착됨
Safety assurance
안전 문제
- 직접적 (e.g. 충돌)
- 간접적 (e.g. 시간지연)
여기서는 directly caused harm에 집중할 것임
Identifying safety requirements
safety requirements에 대해 정의학 ㅣ위해 systematic functional failure analysis (FFA)를 사용함
해당 분석에서는 각 기능을 순차적으로 검토하고, 표준 가이드워드를 사용하여 기능의 편차를 고려함. 이러한 기능적 편차의 잠재적인 최악의 신뢰 가능한 영향을 식별하고 시스템의 safety requirements를 도출함
Demonstrating assurance
safety requirement : the navigation recommender system shall never plan a move that leads to collision with an obstacle
위의 것을 충족하기 위해서는 three areas의 assurance를 필요로 함
- assurance of the training
- assurance of the learned model
- assurance of the overall performance of the drone
thrid는 system testing과 동일
그러나 세 번째만 만족한다는 것은 충분하지 않음
Assurance of the training performed
알고리즘을 학습하기 위해 사용된 데이터와 training이 수행된 simulation environment를 고려해야 함
핵심 질문
- 시뮬레이션 사례가 실제 환경에서 강력한 성능을 보장할 만큼 충분한가?
- obstacle 배치, goal의 위치, drone의 초기 위치 등을 랜덤하게 생성하여 다양한 조건 제공
- 훈련이 저확률 고위험(edge cases) 시나리오를 잘 처리하고 있는가?
- 훈련 사례의 설계는 높은 수준의 다양성을 유지하도록 조정됨
- 16×16 그리드에서 32개의 장애물이 배치된 경우를 고려하면, 이 배치의 가능한 조합은 약
- 모든 가능한 조합을 평가하는 것은 현실적으로 불가능 + 일반화 방해
훈련 데이터의 일부로 edge cases를 선택적으로 포함하고 실제 환경에서 새로운 시나리오를 처리할 수 있도록 충분히 일반화할 수 있는 데이터 다양성 보장해야 함
Assurance of the learned model
학습된 모델 자체의 충분성에 대한 증거 생성도 중요함
이는 실제 환경이나 시뮬레이터에서 모델을 테스트하여 얻을 수 있음
본 논문에서는 simulator에서만 테스트하여 보증 수준에 제한이 있음
핵심 질문
- 테스트 케이스가 훈련 케이스와 충분히 구별되는가?
- 테스트 케이스가 실제 상황을 충분히 대표하는가?
목표 : 학습된 모델이 모든 실제 시나리오에서 safety requirements를 만족할 것임을 입증
완벽하게 테스트하는 것은 불가능하지만 식별된 시나리오의 coverage를 최대화하는 것이 중요
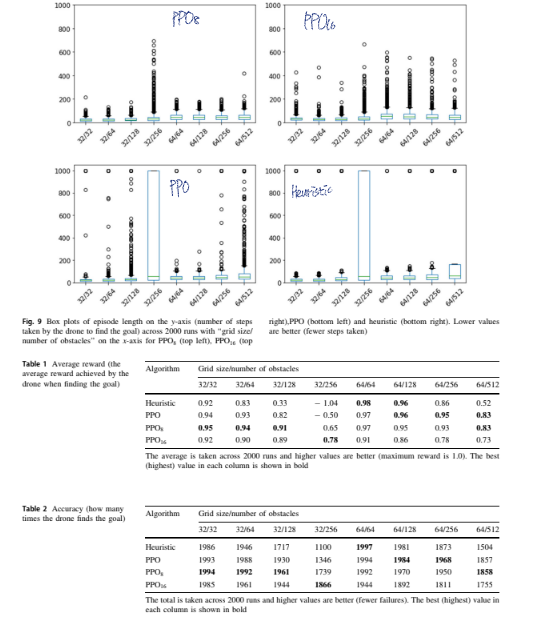
본 논문에서는 설명된 테스트는 구별되는 훈련 케이스를 사용하며, 2000개의 무작위로 생성된 grid layout을 사용
각 grid layout은 다른 모든 grid layout과 독립적이며, 이 layout 집합은 시나리오의 좋은 coverage를 제공해야 함
C# Random class는 뺄셈 난수 생성 알고리즘을 기반으로 하고 있어, 이를 통해 2000개의 layout sequence가 테스트 중 좋은 coverage 제공 가능함
더하여 모델을 훈련했을 때 사용한 것과 다른 grid size와 해당 grid 내에서 다른 수의 obstacles로 평가함. 각 학습된 모델은 8가지 다른 구성으로 테스트 됨
Assurance of the overall performance of the drone
시스템이 드론 플랫폼에 통합될 때에도 safety requirements를 계속 충족한다는 증거 제공이 중요
이미 시스템의 추가 보증을 얻기 위한 실제 환경(‘‘목표’’) 테스트의 역할에 대해 논의함. 이는 시스템이 실제 환경에서 어떻게 작동하는지에 대한 증거를 제공할 뿐만 아니라, 시스템 성능이 다른 구성 요소와의 통합으로 인해 부정적인 영향을 받지 않는다는 증거도 제공함. 목표 테스트는 실제 센서 데이터로 인한 불일치를 식별할 수 있는 기회를 제공하며 실제 환경에서의 테스트는 또한 앞서 설명한 가정들을 검증할 수 있게 해줌
Discussion
본 논문에서는 sensor data를 이용한 dron navigation recommender를 제안함. PPO를 incremental curriculum learning을 포함시켜 수정함. 이를 통해 복잡한 환경을 점진적으로 학습함.
더하여 드론이 이전 step에 대해 기억하고 경로를 반복하지 않게 하기 위하여 LSTM을 추가함
해당 모델을 기존 PPO와 단순한 huristic method와 비교함. 복잡하지 않은 경우는 huristic이 가장 좋았고, 복잡하거나 장애물이 많은 경우는 memory length가 16인 PPO가 더 나은 성능을 보임.
이 모델은 drone navigation뿐만 아니라 여러 분야들에 사용 가능함. 각 도메인에 알맞는 센서와 데이터를 선택하면 알고리즘 사용 가능함.
Appendix
The main Grid-World ML-agents hyper-parameter settings
for training. We use the same settings for our PPO, PPO
with LTSM length 8 and PPO with LSTM length 16.
- Number of hidden layers: 2
- Number of hidden units in each layer: 64
- Beta—strength of the entropy regularisation, ‘‘policy
randomness’’: 2.5e-3 - Gamma—discount factor for future rewards: 0.99
- Lambda—regularisation parameter: 0.95
- Epsilon—acceptable threshold of divergence between
the old and new policies: 0.2 - Learning rate—strength of each gradient descent update
step: 3.0e-4 - LSTM length: 8 or 16
