Aligning LLMs using Reinforcement Learning from Market Feedback (RLMF) for Regime Adaptation
Introduction
금융 시장 : 다양한 변수와 역학이 숨겨져 있거나 관측 불가능
→ 예측 매우 어려움
→ 신뢰할 수 있는 시장 시뮬레이션을 구축하여 random한 시장 가치 변동을 학습하는 방식이 아직 효과적으로 구현되지 X
⇒ 금융 시장 예측 : one-shot learning problem. 오직 하나의 실제 시장 데이터만 존재
traditional ML techniques를 사용해 input observations를 output price movement (market/environment reaction)과 mapping하는 방식
→ dynamic market regime에서 발생하는 correlation, covariate shifts(상관관계 및 공변량 변화)로 인해 out-of-domain data에 일반화되지 못한다는 한계
⇒ 과거의 market data에 완벽하게 적합한 모델을 만들더라도, 미래의 시장 예측의 정확성 보장은 못함
해결책
- teacher-student policies를 활용한 two-stage training(2단계 학습방식)
- pre-trained LLMs를 base policies로 사용
- natural market feedback을 활용하여 RL 기반 정렬 수행
특히, RLMF loss function을 도입하여 LLM 정렬 및 지속적인 regime adaptation이 가능함을 확인함
Preliminaries and Background
Regime-Switching in Finance
전형적 regime switching problem
outcome of market process는 past history와 random shocks에 의해 결정 됨
discrete random variable은 시간 t에서의 regime 상태를 나타냄
각 regime은 다음과 같은 시장 프로세스의 요소들에 영향을 미치는데
한국어로 위부터 절편(기대값), 자기상관 계수, 변동성(표준편차)
수식으로 표현하면
이 됨
최근 DL 기반 기법은 중간 단계에서 regime을 명시적으로 분류하는 과정 없이 input data로부터 자동으로 regime state를 내포하는 distributional latent embeddings(분포적 잠재 표현)을 학습하는 방식으로 발전함. (이는 POMDP에서의 belief b를 학습하는 과정과 유사)
본 논문에서도 이와 같은 접근 방식을 따르지만, 기존의 DL 및 RL 기반 기법과 달리 policy를 동적으로 적응 및 업데이트하는 새로운 방법론을 제안함.
Reward based alignment of Language Models
pre-trained LLM을 reward feedback 및 RL을 통해 fine-tuning하면 사용자의 지시를 따르는 능력이 크게 향상됨.
이러한 과정에서 가장 널리 사용되는 방법론 : RLHF
RLHF pipeline 개요
- supervised fine-tuning, SFT
- pre-trained LLM을 domain 특화 data로 fine-tuning하여 초기 정책 생성
- reward model training
- 훈련된 reward model 가 LLM의 생성 결과를 평가할 수 있도록 함
- 일반적으로 LLM이 생성한 두 개의 응답을 비교하여 scalar reward 값 제공
- 기존 RLHF에서는 사람이 라벨링한 선호 데이터셋을 활용해 reward model을 MLE로 학습하지만 본 논문에서는 다른 방식으로 접근함
- aligned policy fine-tuning with RL
-
trained reward model과 기존 policy인 를 바탕으로, RL을 통해 aligned된 policy를 학습
-
이때, RL 알고리즘은 PPO 사용
-
더하여 KL-divergence penalty 부과를 통해 기존 policy에서 크게 벗어나지 않도록 규제
→ mode collapse 및 비정상적인 high-reward 생성 방지
-
Alignment using RLMF
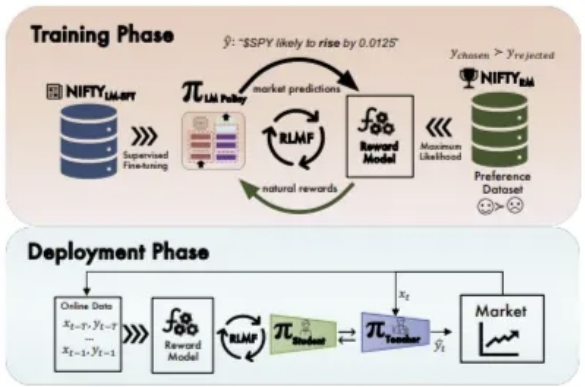
approach에는 two distinct phases 존재
-
training phase
- aligned language model을 teacher policy로 훈련
- reward model 학습
이들은 RLHF 기법 기반, NIFTY dataset에서 sample을 추출하여 진행
-
deployment phase
Dataset

- D_{LM}
-
each sample (JSON-object line)은 고품질로 가공된 (one-turn) coservational query를 포함
-
각 query x_q는 프롬프트 와 응답 로 구성되어 밑의 형태를 가짐
-
해당 dataset은 pre-trained LLM policy를 SFT 방식으로 fine-tune하는 데 사용
-
- D_{RL} : NIFTY-RL
-
선호(preference) 데이터셋 구성
-
rejection sampling, RL fine-tuning에 활용
-
선택된 응답 와 거부된 응답()의 pair 포함되어 밑의 형태로 정의
-
는 보다 더 선호됨
-
Supervised Fine-tuning Teacher Policy
- sequence x (tokens x_1, … x_T로 구성)의 loss
-
autoregressie cross-entropy loss
-
from vocabulary of size V
-
Training a Reward Model
- SFT language model로 initialized된 reward model 학습
- preferences labels를 binary classification 문제로 공식화
- negative log-liklihood loss로 optimizing튜플 왼쪽부터 차례대로 입력 프롬프트, 선호되는 예측, 선호되지 않는 예측 : reward model의 output
Deriving the RLMF objective
intuition
- market에 대한 과거 경험과 현재 습득한 정보(뉴스, SNS, 주변인과의 대화)를 바탕으로 다음날의 시장 변동 예측
- feedback : 다음 날 아침 실제 시장의 움직임
- feedback이 기존 경험을 완전히 무시할 정도로 급격해서는 X
- 대부분의 경우, 시장 변동을 기존 경험과 현재 시장 환경 때문이라고 해석하는 것이 적절
- feedback : 다음 날 아침 실제 시장의 움직임
Technical Details
-
Market Feedback Loss
expectation format으로 표현한 건 생략..
- 모델이 생성한 시장 예측이 실제 반응과 얼마나 근접한가를 최소화하는 방식
- regular RL fine-tuning loss
또는 KL-divergence를 포함하여
- final RLMF objective function
: market feedback reward coefficient. 시장 데이터로부터의 피드백을 얼마나 강하게 반영할지 조절
Algorithm

- teacher policy fine-tune
- teacher policy를 이용해 reward model 훈련
- 학습한 reward model을 통해 teacher policy 재학습?
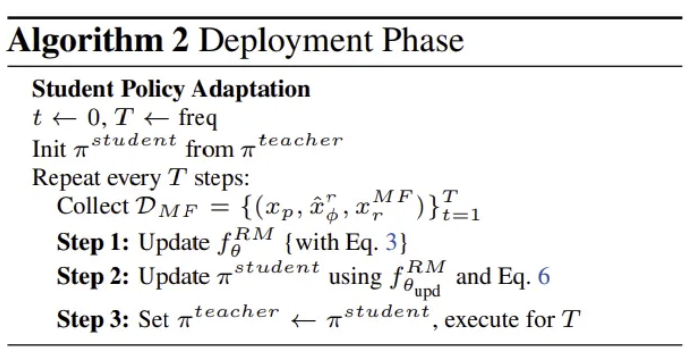
- reward model 업데이트
- student model을 updated reward model 통해 업데이트
- teacher policy를 updated student policy로 변경
teacher policy는 현재 실행되고 있는 모델
student policy는 teacher policy의 최신 버전
둘 간의 정보 우열은 없음.
teacher → student → teacher의 반복적인 업데이트 과정이 regime adaptation의 핵심
Limitations and Future Directions
- LLM을 최신 or 더 큰 모델 사용하지 않음, RL 기반 정렬 기법을 채택하고 RL-free 기법을 사용하지 않음
- 이는 새로운 접근 방식의 실현 가능성과 효과성을 보이는 것에 주 목표를 두었기 때문
- 더 큰 모델을 활용한 연구는 향후 연구 과제
- 특정 금융 업무에 대한 직접적인 적용을 다루지 않음
- 그러나 주식 거래, 포트폴리오 할당 같은 작업에 적용될 수 있을 것
Financial News-Driven LLM Reinforcement Learning for Portfolio Management
Abstract
LLM에서 도출된 sentiment analysis(감성 분석)을 RL framework에 통합하여 거래 성과 향상
- sentiment analysis : 금융 관련 뉴스, 소셜 미디어, 애널리스트 보고서 등에서 시장 심리를 추출하는 과정
- 금융에서는 투자 심리를 파악하는 데 사용
→ quantitative 접근 방식과 qualitative 접근 방식 간의 간극을 좁히고, 질적 시장 신호를 활용하는 것이 금융 거래에서 의사 결정을 개선하는 데 중요한 역할을 할 수 있음을 시사함
Intruduction
최근 강화 학습(RL)은 금융 거래 분야에서 주목받으며, 순차적인 의사 결정을 기반으로 거래 전략을 적응하고 최적화하는 알고리즘을 제공하고 있음
- RL 모델은 복잡한 시장 환경을 탐색하며 지속적으로 전략을 업데이트하여 수익을 극대화할 수 있음
- 그러나 RL 알고리즘은 데이터 기반 의사 결정에는 효과적이지만, qualitative factors(e.g. sentiment)를 반영하지 못하는 경우 많음
→ RL에 감성 분석을 통합하는 것은 이러한 한계를 극복할 수 있는 방법
Methodology
RL은 넘어감
Trading Reinforcement Learning Algorithm
trading RL 알고리즘은 flexibility, reward optimization, and transaction cost considerations를 균형 있게 처리 하여 거래 결정을 simulation하도록 설계됨
- 각 요소는 agent가 수익성 있는 거래 행동을 배우면서 위험을 관리하고 과도한 비용을 피할 수 있도록 구성됨
본 논문에서는 trading reinforcement learning을 빌드하기 위해 OpenAI Gym과 호환되는 맞춤형 환경을 구현함
- 관찰 공간, 행동 공간 및 단계별 상호 작용을 정의하는 표준화된 방법 제공
- PPO와 같은 다양한 RL algorithms가 상호 작용하여 거래 전략을 최적화할 수 있도록 설계됨
- action space
- 연속적인 2차원 공간으로 정의 → 세밀한 거래 결정 내릴 수 있음
- action type : a scalar between 0 and 2
- value < 1 : buy action
- 1 < value < 2 : sell action
- value == 1 : hold
- action amount : a scalar between 0 and 0.5
- agent의 잔액(매수 시) 또는 보유 주식(매도 주식)의 비율
- action type : a scalar between 0 and 2
- 연속적 구조는 실제 거래를 더 잘 모방함
- 실제 거래에서는 거래 규모가 고정된 양이 아니라 다양하기 때문
- 연속적인 2차원 공간으로 정의 → 세밀한 거래 결정 내릴 수 있음
agent가 행동을 선택하면 알고리즘은 선택된 행동 유형과 양에 따라 행동 해석, 조정함
- 매수 : agent가 현재 잔액으로 매수 가능한 최대 주식 계산, 행동 양에 따라 조정
- 매도 : agent가 현재 보유한 주식 수를 기반으로 매도할 주식 수 계산, 행동 양에 맞게 조정
알고리즘의 reward function은 수익성 및 안정성을 모두 촉진하도록 설계됨
- 수익 기반 보상 주요 보상은 agent의 계좌 잔액 변화에 기반하여, 보유한 주식(실현되지 않은 이익)과 매도된 주식에서 얻은 현금(실현된 이익)을 모두 반영
- 계좌 안정성 패널티 계좌 잔액이 초기 잔액에서 얼마나 벗어나는지를 기준으로 안정성 패널티 적용. 더 안정적인 계좌 가치 보상, 변동성이 적은 행동 촉진
- 거래 비용 패널티 실제 거래 수수료를 시뮬레이션하여, agent가 불필요한 거래 최소화하도록 유도
이를 통해 과도한 거래 없이 순자산을 성장시키는 방향으로 이끔
Integration of Sentiment Analysis
sentiment data는 financial news에서 추출
- quantitative values로 mapped
- 알고리즘의 state observations, action adjustments, and reward calculations에 통합
sentiment data는 agent’s observation space에 include되어 시장 감성에 대한 통찰 제공
- [-1, 1] 범위로 스케일링
- 양수 : optimistic
- 음수 : pessimistic
- 0 : neutral
reward function은 sentiment alignment를 통합하도록 조정
- sentiment reward sentiment score가 가격 움직임 방향과 일치하는 경우, agent는 sentiment score에 비례하는 추가 보상 얻음 → agent가 시장 감성과 일치하는 거래하도록 유도
- volatility adgustment (변동성 조정)
- agent가 변동성이 큰 조건에서 sentiment에만 의존하지 않도록 하기 위해, 최근 가격 변동성에 따라 조정
- 높은 변동성 기간에는 sentiment reward가 약간 줄어 가격 변동성의 예측 불가능성 반영 → agent가 감성을 효과적으로 통합하도록 유도, 최근 시장 안정성 기반 신뢰성 조정
Extension to Portfolio Management
포트폴리오 관리에 적용하려면 몇 가지 새로운 복잡성이 추가됨
- agent가 자산을 관리하고 개별 자산의 감정 및 시장 조건을 고려하여 거래 결정 내려야 함
- 각 자산은 고유한 가격 변동과 감정 데이터 지님
- agent는 전체 순자산을 극대화하기 위해 자본을 자산 간에 효과적으로 배분하는 방법을 학습해야 함
주식별 특성과 감정 데이터를 통합하여 더 정교하고 감정에 민감한 포트폴리오 관리를 가능하게 함
포트폴리오 설정
- 각 자산(주식) : 고유한 observation space 지님
- space에는 가격 data, 계좌 정보 및 감정 지표 포함
- space는 matrix로 구성
- 행 : 다른 주식
- 포트폴리오 environment의 action space에서는 agent가 포트폴리오 내 각 자산에 대해 독립적인 행동 취할 수 있음
뭐 이거 말고는 크게 다른 거 없어 보임
Limitation & Futurework
-
news 데이터 기반으로 감성 분석을 함
→ 하루 중 시장 감성의 변화를 완전히 포착하지 못할 수 있음
⇒ 트위터, 레딧과 같은 소셜 미디어 감성을 통합하면 더 포괄적으로 이해할 수 있을 것
-
본 논문에서 평가한 모델은 고정된 hyperparameter와 시장 조건을 사용함
→ 다양한 시장 환경에 일반화되지 않을 수 있음
⇒ hyperparameter tuning, fine-tuning, 다양한 시장 주기에서의 모델 강건성 탐구 필요
Learning to Generate Explainable Stock Predictions using Self-Reflective Large Language Models
Abstract
SEP : 요약-설명-예측 framework
- verbal self-reflective agent와 PPO를 활용하여 LLM이 스스로 설명 가능한 주식 예측을 학습할 수 있도록 완전한 자율 학습 환경 제공
- reflective agent : 과거 주식 변동을 self-reasoning 과정을 통해 설명하는 방법 학습
- PPO trainer : test 시 입력 텍스트를 기반으로 가장 가능성 높은 설명을 생성하도록 모델을 학습시킴
- 장점 : 반영 과정에서 생성된 응답을 활용한 학습 샘플을 통해, 인간 주석자 필요 X
Introduction
EMH(효율적 시장 가설) : 금융 시장에서 주가는 모든 이용 가능한 정보를 반영하며, 새로운 정보에만 반응해야 함
기존의 딥러닝 방법 : black-box model, 예측 결과의 설명 가능성 제공X
→ 사용자가 결과를 신뢰하고 자본 투자하기 어려움
현재 주식 예측에 LLM을 적용한 연구는 많지 않음 + 주로 pre-trained LLM을 사용하거나 간단한 instruction tuning 방식에 의존하고 있음
→ 본 논문에서는 RL framework를 설계하여 LLM이 주식 예측을 위한 설명을 생성할 수 있도록 fine-tuning하는 방안을 탐색함
LLM을 활용한 explainable stock problem을 해결하기 위한 두 가지 주요 과제
- social text는 매우 불규칙하며 서로 다른 텍스트가 주가에 미치는 영향은 다양함
-
e.g. 예상치 못한 실적 발표나 위기 상황과 같은 속보 뉴스 → 주가에 큰 영향 / 근거 없는 의견이나 모호한 발언 → 변화 X
⇒ 예측 모델은 다양한 정보가 미치는 영향을 평가하고, 최적의 확률을 기반으로 예측을 수행할 수 있어야 함
-
일반적으로 회귀 기반의 신경망 훈련을 통해 해결 가능
-
LLM이 기본으로 갖추고 있는 능력 X
-
- 설명을 포함할 경우 문제의 난이도 증가
-
RL을 이용해 LLM을 훈련하려면 각 가격 변동 사례에 대한 좋은 예제와 나쁜 예제 필요
→ 금융 전문가들의 막대한 노력과 비용 요구 ⇒ 확장성 부족
⇒ LLM이 완전한 자율 방식으로 explainable stock prediction을 학습할 수 있도록 돕는 SEP framework 제안
-
SEP 구성하는 세 가지 모듈
-
Summarize module
LLM의 강력한 요약 능력 활용하여 대량의 text data를 핵심 정보가 담긴 요약 형태로 변환
-
Explain module
self-reflective agent를 이용하여 주어진 요약된 사실들을 바탕으로 올바른 주식 예측 수행, 예측 근거 설명 과정 반복 학습
- LLM은 스스로 예측 오류를 수정하여 정답과 오답이 포함된 학습 데이터 생성 → 추가적 인간 개입 없이 미세 조정 데이터로 활용 가능
-
Predict module
특화된 LLM을 PPO를 통해 미세 조정 → 새로운 test data에 대해 가장 가능성 높은 주식 예측과 설명을 생성할 수 있도록 학습
Related Works
LLM in Finance
- BloombergGPT sentiment analysis 및 named entity recognition과 같은 여러 금융 관련 downstream 작업에서 긍정적 성과 보임
- FinMA
- FinGPT 금융 데이터를 학습하여 특정 금융 테스크를 수행하도록 fine-tuned된 모델들
최근 연구들은 text sequence를 활용하여 LLM을 이용한 주식 예측을 시도하고 있음. instruction-tuning 또는 기업 관계 그래프를 결합한 pre-trained model을 사용하는 방식이 주목받고 있음.
Methodology
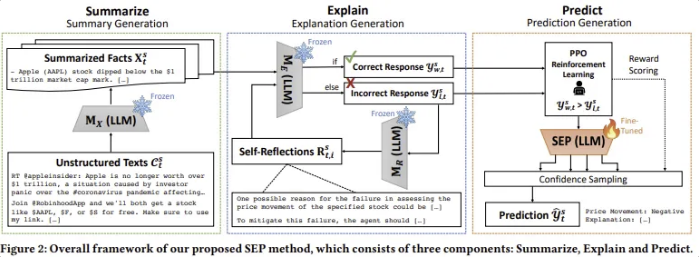
- summarize module : 비정형 text input에서 사실 정보 요약
- explain module : 주식 예측에 대한 설명 생성, 반복적인 self-reflection 과정 통해 예측 개선
- predict module : LLM을 fine-tuning한 후 신뢰도 기반 주식 예측 수행
Preliminaries
-
problem formulation
주어진 주식 와 과거 T일 동안의 관련 텍스트 데이터 를 활용하여 다음 거래일의 주가 변동 예측 수행
- 는 두 가지 요소로 구성
- : 주가 상승(1) 또는 하락(0)에 대한 binary price movement
- : 예측 결과에 대한 설명
- 각 날의 텍스트 데이터는 다양한 뉴스 및 트윗으로 이루어져 있음
- 이를 요약하여 예측 모델에 입력
- 는 두 가지 요소로 구성
-
data collection and clustering
기존 ACL18 StockNet 데이터셋 기반 새로운 데이터셋 구축
- 기존 데이터셋을 확장하여 2020~2022년 동안의 데이터 수집
- 주가 데이터 : Yahoo Finance에서 수집
- 트윗 데이터 : Twitter API 활용하여 수집
- 트윗 양이 폭발적으로 증가 → BERTopic 활용하여 대표적인 트윗 clustering
Summary Generation
-
주식 s에 대한 특정 날짜 t의 비정형 텍스트 데이터 입력
-
LLM 가 해당 데이터 기반 요약된 사실 정보 생성
Explanation Generation
-
Explanation Prompting
Explan module의 prompt는 두 개의 변수 입력 포함
- 특정 주식 s
- 이전 모듈에서 추출된 일련의 정보
이를 기반으로 LLM 는 응답 생성
이전 요약 prompt와 유사하게 dataset에서 두 개의 사례를 선택하여 few-shot 예시로 사용
- 한 개는 가격 상승(positive), 한 개는 가격 하락(negative)로 선택 → majority label bias 방지
- prompt는 ReAct와 유사하게 설계되었지만 예측과 설명이 단계에서 동시에 이루어지는 방식으로 구성
-
Self-Reflective Process
주식 예측을 위해 훈련된 것이 아닌 LLM → 앞서 생성된 설명 부정확할 수 O
⇒ LLM을 autonomous agent로 사용하여 반복적으로 스스로의 응답을 개선하는 self-reflection loop를 수행하도록 함
-
초기 응답 생성
첫 번째 응답 을 초기값으로 설정
-
정확성 평가 및 피드백 생성
- 생성된 가격 변동 가 실제 정답과 일치하는지 확인
- 틀린 경우, LLM 이 이전 input 및 output 바탕으로 피드백 생성
- 피드백은 LLM이 이전 오류를 반성하고 향후 개선 방안 제시 역할
-
반성 내용 저장 및 새로운 예측 생성
- 반성 내용을 long-term memory에 추가
- 반성 내용 반영하여 LLM 가 새로운 예측 생성
- 최종적으로 성공적인 반성을 통해 올바른 예측을 생성한 경우
- 잘못된 예측을 한 경우로 저장됨
-
Prediction Generation
새로운 test 기간에서도 정확한 주식 예측과 설명을 생성하는 것이 목표
-
Model Fine-Tuning
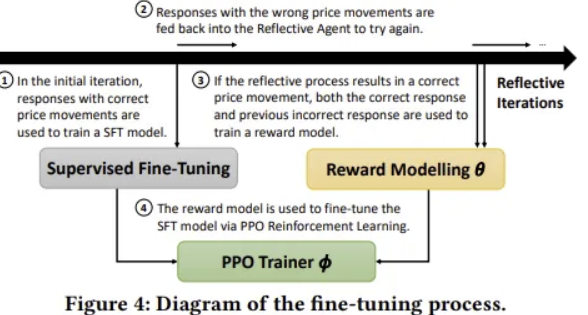
RLHF를 활용하여 진행
- 본 논문에서는 human feedback 대신 자기 반성 루프에서 생성된 binary evaluation 활용하여 최적의 응답 학습
- Supervised Fine-Tuning
- 초기 프롬프트에서 올바른 예측을 생성한 사례들을 demonstration data(지도 학습 데이터)로 수집
- 이를 활용하여 초기 정책 학습
- Reward Model 학습
- 성공적인 자기 반성 과정에서 수집된 올바른 응답과 잘못된 응답을 비교 데이터셋 D로 구성
- 해당 데이터를 사용하여 reward model 학습 - 올바른 응답에 더 높은 보상
- 학습에는 cross-entropy loss 사용
- PPO 기반 optimization
- 학습된 reward model을 통해 policy optimiation 수행
- 초기 지도 학습 모델 기반으로 강화학습 정책 훈련
- policy가 단일한 답변 패턴에 고착되는 것 방지 위해 KL-divergence penalty 항을 추가하여 loss 정의
-
Confidence-based Sampling
test data에 대해 예측 수행 시 다음 단계를 따름
- 비정형 텍스트 를 pre-trained LLM을 사용하여 요약
- 강화학습 정책 통해 요약된 데이터로부터 예측 생성
- Best-on-n sampling 기법 사용하여 n개의 응답 생성 후, reward model이 가장 높은 점수 준 응답 선택
Conclusion and Future Work
기존 모델보다 더 높은 예측 정확도와 설명 품질 달성
포트폴리오 최적화 모델을 fine-tuning함으로써 범용성 입증함
향후 연구해야 할 것들
- cumulative error 문제 해결
- 특정 단계에서 오류 발생 → 이후 단계에 영향 ⇒ 보다 견고한 모델 구축하여 사람의 개입 최소화하는 연구 필요
- 특정 단계에서 오류 발생 → 이후 단계에 영향 ⇒ 보다 견고한 모델 구축하여 사람의 개입 최소화하는 연구 필요
- 추가적인 데이터 소스 활용
- knowledge graphs or audio features 등의 추가적 데이터 소스 활용 통해 성능을 더욱 향상시킬 수 있을 것
- 주식 설명 평가 방법 개선
- 현재 생성된 주식 설명 평가에 대한 표준적 방법 부족
- 본 논문에서 제안한 평가 지표 개선, 보다 정교한 평가 체계 구축하는 후속 연구 필요
