📄Playing Atari with Deep Reinforcement Learning
written by Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller
Introduction
Vision 또는 speech와 같이 high-dimensional sensory inputs로부터 agent를 학습시키는 것은 강화학습의 오랜 과제. 이러한 데이터를 성공적으로 적용시킨 사례들은 linear value function이나 policy representation에 결합된 hand-crafted features에 많은 영향을 받음. 또한 feature들의 퀄리티에 성능이 조ㅘ우됨
딥러닝이 발전함에 따라 고차원의 데이터들을 추출하는 것이 가능해졌고, CNN, Multi-Layer Perceptrons, restricted Boltzmann machines, RNN 등을 통해 지도 및 비지도 학습에 사용됨. 성공적인 결과로 딥러닝을 강화학습에 도입하는 연구를 진행하게 됨
그러나 딥러닝을 강화학습에 적용하는 과정에 문제점 발견됨
- 대부분의 딥러닝 application은 손으로 label된 많은 양의 훈련 데이터를 필요로 함. 반면, 강화학습은 sparse, noisy, delayed한 reward signal이라는 scalar 값을 통해 학습해야 함
딥러닝은 인풋에 대한 결과가 직접 작성되어 계산의 시간이 적지만 강화학습에서는 어떠한 행위를 하면 trial and error를 통해 그 행위에 대한 결과를 알기까지 시간이 필요함. 이러한 delay는 어려움을 자아냄 - 딥러닝 알고리즘에서 각 데이터들은 독립적인 반면, 강화학습에서는 하나의 행위가 다른 것들과 연관성이 높음
- 강화 학습에서는 알고리즘이 새로운 행동을 배울 때마다 데이터의 분포가 변하게 됨. 이는 데이터의 분포가 고정되어 있다고 가정하는 딥러닝의 assumption과 충돌하여 문제 발생 가능함
본 논문에서는 CNN이 복잡한 강화 학습 환경에서 원시 비디오로 성공적인 control policy를 학습할 수 있음을 증명함.
CNN은 변형된 Q-Learning을 통해 학습, weight를 업데이트하기 위해 SGD 사용함. 또한 correlated data와 non-stationary distributions의 문제를 줄이기 위해 experience replay memory를 사용함. 이는 무작위로 이전의 transition을 추출하여 훈련 분포가 원활해지도록 함
DeepMind는 하나의 NN을 만들어 간으한 많은 게임을 학습시키는 것을 목표로 하였고, 게임에 대한 특정 정보나 게임의 우위를 위한 데이터 등을 제공하지 ㅇ낳음
오직 비디오의 시각 데이터와 보상, 그리고 터미널로부터 오는 신호 그리고 가능한 몇 개의 행동으로면 학습을 진행함. 그리고 다양한 게임들에 대해 동일한 Network architecture와 하이퍼파라미터를 사용함
Background
Agent가 환경과 상호작용하는 테스크에서 각 time-step마다 agent는 할 수 있는 행동(at) 중 하나를 선택하게 됨. 액션이 전달되는 emulator는 내부 상태를 변경하고 게임 점수를 수정함. 이때, agent는 게임 내부 상태를 알 수 없고, 현재 화면을 나타내는 raw pixel의 vector로 이루어진 이미지와 게임점수의 변화를 나타내는 reward(rt)만 전달받음
그러나 게임의 점수는 현재의 행동뿐만 아니라 이전에 거친 일련의 행동에 의존하여 결정되고, 행동에 대한 피드백은 수천 회의 time-step이 진행된 후 받게 됨
agent는 오직 현재의 장면만 관찰하기 때문에 전체적인 상황 이해 어려움
이를 해결 위해 action의 sequence 관찰하고 이를 통해 학습 진행함
이러한 formalism은 크지만 유한한 Markov Decision Process(MDP) 야기.
결과적으로 MDP에 standard한 강화학습 방법을 적용할 수 있고, 이것은 시간 t에서의 상태를 표현하기 위해 전체 시퀀스를 사용함을 의미함
agent의 목표는 future reward를 극대화시키는 방식으로 action을 선택하고 이를 emulator에 전달하는 것. 시간이 오래 지날수록 리워드의 가치는 점점 내려가는데, 이를 적용시키기 위해 discount factor r이 정의됨
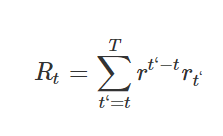
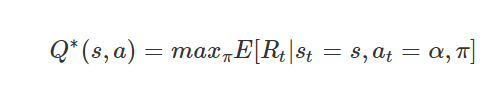
최적의 전략은 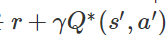
의 expaected value를 최대화시키는 것
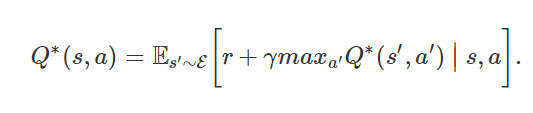
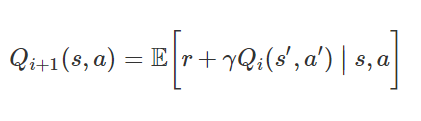
Related Work
이전 강화학습이 적용되었던 가장 유명한 사례는 TD-gammon
강화학습을 통해 스스로 플레이 방법을 터득하고, Q-learning과 유사하게 model-free한 구조로 MLP with one hidden layer의 네트워크 지님
그러나 GO나 Chess에 적용할 때에는 실패했고, 이러한 접근법은 TD-Gammon에만 최적화되었으며 어쩌만 주사위의 확률이 우연히 explore를 돕고, value function을 부드럽게 만들어 주었다는 착각을 불러일으킴
최근에야 딥러닝과 강화학습을 융합시키는 분야가 부활함
본 논문의 접근법과 가장 유사했던 이전의 작업으로는 NFQ(Neural fitted Q-Learning)가 있음. 이는 Q-Net의 파라미터들을 갱신시키기 위해 RPROP 알고리즘을 사용하여 2번 방정식에서 손실함수를 최적화시킴. 그러나 이것은 iterationㅇ르 돌기 위해 많은 계산양을 필요로 하는 BGD를 사용함.
본 논문에서는 SGD를 사용하여 iteration을 돌기 위해 필요한 계산 양을 줄였고, 큰 데이터셋까지 학습의 스케일을 높임
NFQ는 또한 처음으로 deep autoencoder를 사용함으로써 task의 low dimensional representation을 학습하였고, 시각입력을 사용함으로써 real-world control task를 성공적으로 NFQ 알고리즘에 적용함
그러나 이와 반대로 본 논문에서는 시각적 입력으로부터 직접적으로 철저한 강화학습을 적용시켰고, 결과적으로 Action-Value를 판별하는 것과 같은 특징들을 학습함
Deep Reinforcement Learning

장정
- 각 스텝의 experience가 잠재적으로 많은 weight update에 재사용되어 experience를 weight update 한 번에만 사용하는 이전의 방법보다 more data efficiency
- 연속적인 samples로부터 학습을 진행하는 것은 데이터들간의 high correlations 때문에 비효율적이기 때문에 samples를 e-greedy 알고리즘 통해 랜덤화하여 high correlations를 break하여 업데이트의 효율성 높임
- 원하지 않는 feedback loop 발생, 파라미터들이 로컬minimum으로 수렴 또는 발산함을 방지 가능
Preprocessing and Model Architecture
128 color palette를 가진 210 160 pixel images인 raw Atari frames를 RGB로 표현된 이미지를 Gray-Scale로 변환, 110 84의 이미지로 down-sampling
이후 게임의 진행부분만 보이도록 84 * 84로 잘라내서 Final Input값을 추출
알고리즘의 전처리 함수인 ϕ()ϕ()\phi() 에서 마지막 4개의 frames만 전처리를 하여 Stack에 넣어두고, 이를 입력에 대한 Q-function의 값을 구하기 위해 사용
Q-Value 구하는 방법
- history와 action을 input으로 하고 그에 대해 예측된 Q-value 구하기
- history만을 input으로 하고 모든 행동에 대해 예측된 Q-value 구하기
1을 사용하면 들어온 action에 대해 separate forward pass 진행해야함, 들어온 action에 따라 연산의 양도 선형적으로 늘어남
따라서 2번 통해 한 번의 single forward pass로 처리하여 연산 양 줄임
Experiments
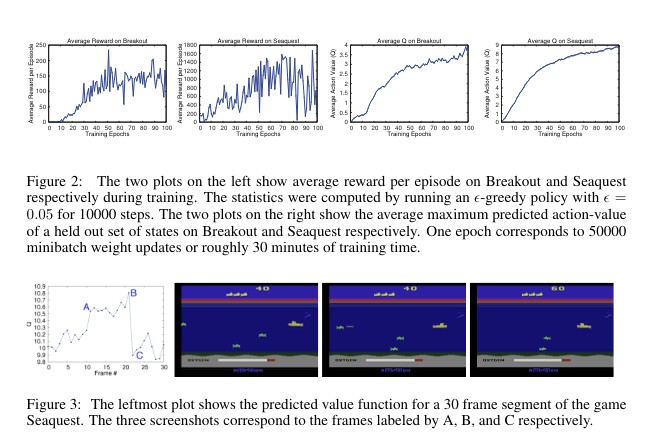
stable하게 학습시킬 수 있음
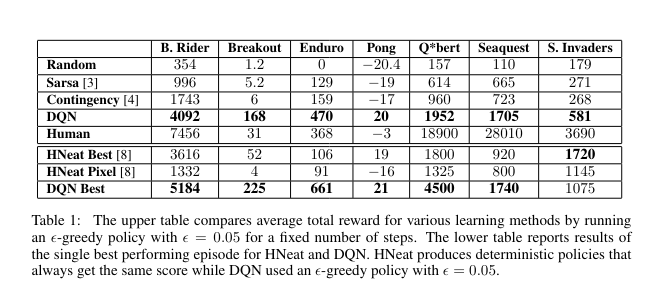
Conclusion
본 논문에서는 강화학습을 위한 새로운 딥러닝 모델을 제안함. 이를 바탕으로 raw pixel들만을 입력으로 사용하여 2600가지가 넘는 atari 게임을 위한 어려움 control policy를 학습하는 것이 가능함을 증명함
또한 딥 네트워크의 학습을 쉽게 하기 위해 SGD에 experienc replay memory를 적용한 Q-Learning의 변형을 소개함
해당 접근법은 architecture나 hyperparameter의 변화 없이 7개의 게임 중 6개에 게임에서 좋은 결과를 도출함
