📄Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
written by Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, and Victor Lempitsky
Introduction
Synthesizing realistic talking head sequences는 두 가지 이유로 인해 어렵다고 알려져 있음
- 인간의 머리는 높은 photometric, geometric and kinematic complexity를 지니고 있음
얼굴을 모델링하는 것뿐만 아닌 인 안쪽, 머리카락 및 의류를 모델링하는 것으로 인해 높은 복잡성 지님 - 인간의 시각 시스템은 사소한 실수에 대해서도 매우 민감함(the so-called uncanny valley effect)
이러한 문제들을 극복하기 위해 여러 연구에서는 synthesize articulated head sequences by warping a single or multiple static frames과 같은 방법을 제안함. Both classical warping algorithms and warping fields synthesized using machine learning (including deep learning)을 통해 실현할 수 있음.
그러나 수백만 개의 매개 변수를 가진 대규모 네트워크를 훈련해야 한다는 점과 같은 단점이 존재함
본 논문에서는 소수의 사진(few-shot learning)과 제한된 훈련 시간으로 talking head model을 생성하는 시스템을 제안함.
본 시스템은 단일 사진(원샷 학습)을 기반으로 합리적인 결과를 생성할 수 있으며, 몇 장의 사진을 추가하면 개인화의 정확도가 증가함
Relations
인간 얼굴의 외관을 통계적으로 모델링하는 것에 대한 연구는 많았음
이 연구들은 고전적인 기술과 최근 딥러닝을 통해 놀라운 결과를 얻었음
얼굴 모델링은 talking head modeling과 많은 관련이 있는 작업이지만 동일하지는 않음. talking head modeling은 머리카락, 목, 입 안쪽, 어깨/상체 의류와 같은 얼굴 이외의 부분도 모델링을 포함함
얼굴이 아닌 부분은 얼굴 모델링 방법의 간단한 확장으로는 처리 불가능함
본 논문에서 제안하는 시스템의 설계는 이미지 생성 모델링의 최근 발전에서 많은 영향을 얻음. architecture는 adversarial training을 사용하며, 더 구체적으로는 projection discriminators을 포함한 conditional discriminators의 아이디어를 사용함.
meta-learning 단계는 adaptive instance normalization mechanism을 사용함.
모델 비종속적 메타 학습자(MAML)은 메타 학습을 사용하여 이미지 분류기의 초기 상태를 얻은 다음, 적은 훈련 샘플로 보이지 않는 클래스의 이미지 분류기로 빠르게 수렴할 수 있음.
이러한 고차원적 아이디어는 본 논문의 시스템에도 활용되지만 구현 방식이 다름
유사한 적대적 목표를 사용하여 이미지 생성 모델을 훈련하는 데 중점을 둠. 즉, 메타 학습 프레임워크에 적대적 미세 조정을 도입한다는 것.
본 연구와 큰 관련이 있는 두 가지의 최근 연구는 text-audio 변환에 관한 것임. 이들의 설정(few-shot generative model learning)과 일부 구성 요소(독립형 임베더 네트워크, 생성기 미세 조정)을 본 논문에서도 사용함
Methods
1 & 2 Architecture and notation & meta-learning stage
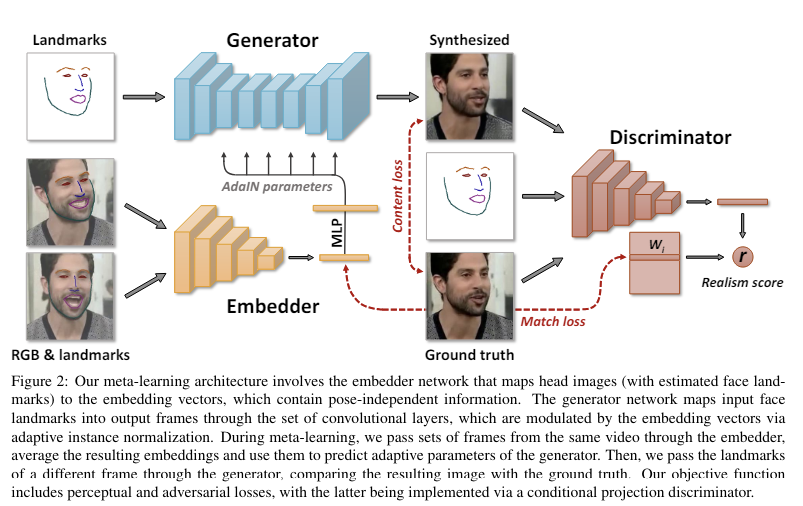
-
Embedder는 reference(source) video를 랜덤으로 추출한 이미지와 그 이미지의 landmark를 사용하여 N-dim의 vector로 임베딩함
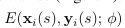
-
Generatoor는 reference video의 몇몇 프레임들을 embedding한 결과와 타겟 이미지의 landmark를 입력 받아 새로운 이미지를 합성함
-
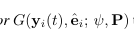
-
loss:
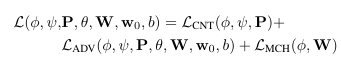
-
-
Discriminator는 합성된 이미지가 landmark를 잘 반영하고 있는지 판단함
-
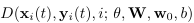
-
loss:
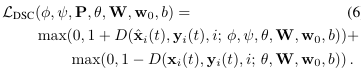
-
3. few-shot learning by fine-tuning
메타 학습이 수렴한 후, 우리 시스템은 메타 학습 단계에서 보지 못한 새로운 사람에 대한 말하는 머리 시퀀스를 합성하는 방법을 배울 수 있음
이전과 마찬가지로 합성은 landmark image에 조건을 둠. 시스템은 몇 장의 훈련 이미지가 주어지고 주어진 시퀀스에 해당하는 랜드마크 이미지라고 가정하여 few-shot 방식으로 학습됨
meta-learned embedder를 통해 embedding e_new 계산함
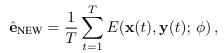
메타 학습 단계에서 추정된 파라미터를 재사용함. 이렇게 하는 경우 생성된 이미지가 그럴듯하고 현실적이지만 고도의 개인화를 목표로 하는 대부분의 응용 프로그램에서는 허용되지 않는 상당한 정체성 차이가 종종 발생함
이러한 정체성 차이는 종종 fine-tuning 단계를 통해 해결할 수 있음. fine-tuning 과정은 단일 비디오 시퀀스와 적은 수의 프레임을 사용하는 메타 학습의 단순화된 버전으로 볼 수 있음
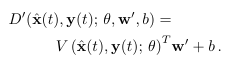
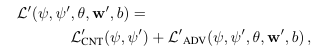
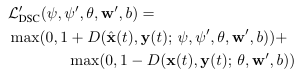
4. Implementation details
사람 특정 파라미터 ψ_i는 인스턴스 정규화 레이어의 아핀 계수로 사용, 인스턴스 정규화 기술 따름. 다만, landmark image를 encoding하는 downsampling block에서는 일반(비적응형) 인스턴스 정규화 레이어 사용함
embedder와 discriminator의 convolution part에 대해서는 잔차 다운샘플링 블록을 사용하는 유사한 네트워크 사용함. 두 네트워크 모두에서 벡터화된 출력을 얻기 위해, 공간 차원에 대해 global sum pooling 수행 후 ReLU 적용함
모든 convolution 및 fully connected layer에 대해 스펙트럼 정규화 사용함
L_CNT 계산 위해 실제 및 가짜 이미지에 대해 Conv1,6,11,20,29 VGG19 레이어와 Conv1,6,11,18,25 VGGFace 레이어의 활성화 사이의 L1 손실을 평가함
Convolution layer의 최소 채널 수를 64로, 최대 채널 수와 임베딩 벡터의 크기 N을 512로 설정. 네트워크는 Adam 사용하여 최적화.
embedder와 generator의 learning rate는 5x10^(-5)로, discriminater의 learning rate는 2x10^(-4)로 설정. discriminater는 generator가 한 번 업데이트될 때, 두 번 업데이트 스탭 가짐
Experiments
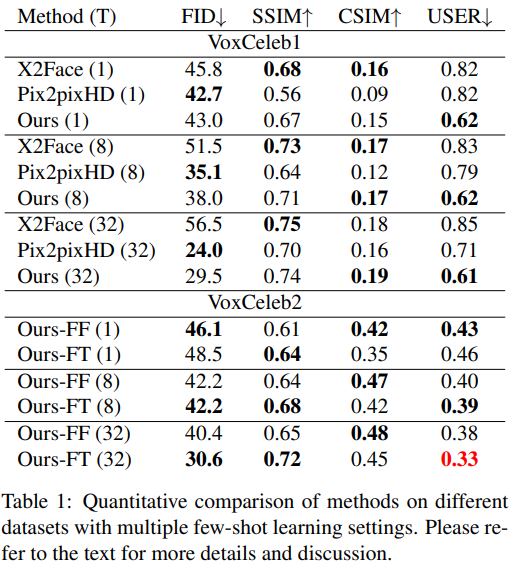


타겟 이미지를 잘 반영하고, 사용자의 평가 높음
Conclusion
본 논문에서는 높은 현실성을 표현할 수 있는 deep generator network인 framework for meta-learning of adversarial generative models에 대하여 소개함.
특별한 점은 새롱누 모델을 생성하기 위해 소수의 사진(최소 한 장)만 필요하다는 것임.
32장의 이미지로 훈련된 모델은 사용자 연구에서 완벽한 현실감과 개인화 점수를 달성함. 현재 이 방법의 주요 제한 사항은 표정 표현과 landmark 적응의 부족임. 다른 사람의 landmark를 사용하면 눈에 띄는 인물 불일치가 발생함. 따라서 이러한 것을 개선하기 위해서는 일부 landmark 적응이 필요함.
그러나 많은 응용 프로그램은 다른 사람의 꼭두각시 조종을 필요로 하지 않으며 대신 자신의 talking head를 구동하는 기능만 필요하다는 점을 지적함. 이러한 시나리오에서는 본 논문의 방식이 높은 현실감을 제공하는 솔루션을 제공함
