📄Post-training Quantization on Diffusion Models
written by Yuzhang Shan, Zhihang Yuan, Bin Xie, Bingzhe Wu, Yan Yan
Introduction
최근 denoising diffusion generative models는 생성 작업에서 현저한 성과를 거두었지만 노이즈 추정 네트워크의 긴 반복적인 과정과 각 반복마다 무거운 네트워크의 사용으로 인해 생성 과정이 느리고 비효율적임.
이전의 방법들은 전적으로 반복 과정에 초점을 두었지만, 본 논문에서는 네트워크의 압축 관점에 접근하여 Post-Training Quantization(PTQ)를 제안하고 이를 통해 문제해결을 하고자 함
PTQ를 통해 노이즈 추정 네트워크 계산을 가속화하고, 저장해야 하는 diffusion model의 가중치 리소스를 줄일 수 있었음
본 논문에서는 PTQ를 통한 diffusion model의 가속화의 새로운 가능성을 제시하고, 실험 결과를 통해 사전 훈련된 확산 모델을 8bits로 양자화할 수 있다는 것을 보여줌. 이는 훈련 없는 네트워크 압축 기술로, 다른 최신 기술들에 대한 플러그 앤 플레이 모듈로 활용될 수 있음
Related Work
Diffusion Model Acceleration
네트워크를 통한 노이즈 제거의 높은 비용과 긴 반복적 process로 인해 diffusion model은 widely implemented되기 어려움
이에 대한 이전 연구들은 확산 모델의 성능을 유지하면서 더 짧은 샘플링 경로를 찾는 방법을 추구해왔지만 매우 긴 경로에 대해 적용하기 어렵다는 한계가 존재함. 본 연구에서는 이러한 단축된 샘플링 경로 외에도 네트워크 압축을 통해 확산 모델을 더 가속화할 수 있다는 것을 보여줌
PTQ4DM은 이전의 빠른 샘플링 방법과 별개로 함께 플러그 앤 플레이 모듈로 사용될 수 있음. 본 연구는 최초로 post-training 방법을 통해 diffusion model을 quantizing하는 방법임
Post-training Quantization
신경망을 압축하는 가장 효과적인 방법 중 하나로, Quantization-aware training(QAT)와 Post-training quantization(PTQ)로 나뉨
QAT는 신경망 훈련 단계에서 quantization을 고려하고, PTQ는 훈련 후에 신경망을 quantization함.
PTQ는 훨씬 적은 시간과 계산 리소스를 소비하여 네트워크 배포에 널리 사용됨. PTQ의 대부분 작업은 각 레이어의 가중치와 활성화에 대한 양자화 매개변수를 설정함
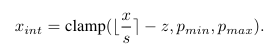
이를 위해 특정 양자화 매개변수를 선택하기 위해 작은 수의 보정 샘플을 사용함. 선택된 양자화 매개변수는 보정 샘플의 선택과 관련있음
ZSQ는 PTQ의 특수한 경우로, 네트워크에 기록된 정보를 기반으로 보정 데이터 세트를 생성함. 이전의 ZSQ 방법과는 다르게 diffusion model의 이미지 생성과정은 네트워크 추론만 사용함
PTQ on Diffusion Models
Preliminaries
-
Diffusion Models
diffusion probabilistic model(DPM)은 variational bound L_VLB를 최적화하는 것을 통해 학습됨
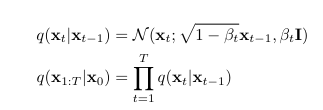
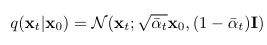
alpha_t = 1-beta_t
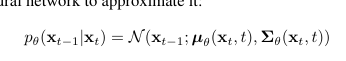
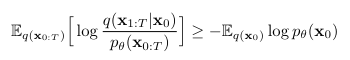
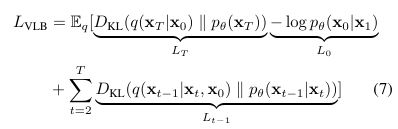
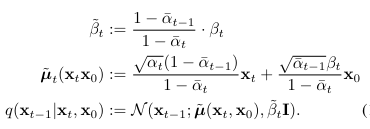
x_t-1을 p_theta를 통해 샘플링하여 denoising process 진행 -
Post-training Quantization
잘 훈련된 네트워크를 가지고 각 레이어의 가중치 텐서와 활성화 텐서에 대한 양자화 매개변수 선택. 해당 매개변수 사용하여 텐서를 quntization된 텐서로 변환함.
매개변수를 선택하는 가장 널리 사용되는 방법 중 하나는 양자화에 의한 오차를 최소화하는 것으로, 양자화 오차는 일반적으로 MSE, 코사인 거리, L1 거리 및 KL divergence와 같은 metric 함수 사용하여 계산함
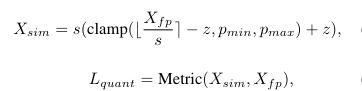
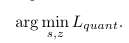
quantization 과정은 주로-
양자화해야 할 네트워크 연산 선택하고 나머지 연산을 완전 정밀도로 남김
-
보정 샘플 수집. 보전 샘플 분포는 실제 데이터 분포에 가능한 한 가깝게 유지
-
가중치 텐서와 활성화 텐서에 대한 양자화 매개변수 선택하기 위한 적절한 방법 사용
으로 이루어짐
-
Exploration on operation Selection
확산 모델에서는 이미지 생성 과정을 분석하여 어떤 연산이 양자화되어야 하는지 결정할 것임
확산 모델은 각 시간 단계에서 네트워크의 입력으로 xt와 t를 받고, 출력으로는 평균 µ와 분산 Σ를 반환함. 그 후, xt−1은 Eq 5에 정의된 분포에서 샘플링됨
확산 모델의 네트워크는 대부분의 이전 PTQ 방법과 마찬가지로 계산 집중적인 convolution layer와 fully-connected layer를 양자화해야 함. batch normalization은 convolution layer로 통합될 수 있음. special function인 SiLU 및 softmax는 full-precision으로 유지됨
네트워크의 출력인 µ와 Σ, 그리고 샘플링된 이미지 xt−1이 양자화될 수 있는지에 대한 두 가지 질문이 있는데, 이 두 질문에 대한 답으로 µ, Σ, 또는 xt−1을 생성하는 연산만 양자화함.
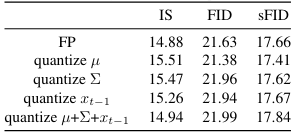
테이블에 표시된 것처럼, 이들이 양자화에 민감하지 않음을 관찰하였으며, 따라서 양자화될 수 있다고 나타냅니다.
Exploration on Calibration Dataset
두 번째 단계는 diffusion model을 quantization하기 위한 보정 샘플을 수집하는 것
보정 샘플은 다른 네트워크를 양자화하기 위해 훈련 데이터셋에서 수집될 수 있음. 그러나 확산 모델의 훈련 데이터셋은 네트워크의 입력이 아닌 x_0임
본 논문에서는 직관적인 PTQ 베이스라인들을 종합적으로 조사함으로써 네 가지 유의미한 관찰을 얻었고, 이에 따라 방법을 설계함.
- Observation 0
Distributions of activations changes along with time-step changing - Observation 1
generated samples in the denoising process are more constructive for calibration - Observation 2
sample x_t close to real image x_o is more beneficial for calibration - Observation 3
Instead of a set of samples generated at the same time-step, calibration samples should be generated with varying time-steps
실험결과는 본 논문에서 제시한 방법이 효과적이고 효율적임을 보여줌
개발된 PTQ4DM 보정을 통해 8비트 post-trained quantization된 확산 모델은 전체 정밀도와 동일한 성능 수준을 발휘할 수 있었음
Exploration on Parameter Calibration
보정 샘플이 수집되면, 확산 모델의 텐서에 대한 양자화 매개변수를 선택함. 텐서를 보정하는 데 사용되는 메트릭을 탐색
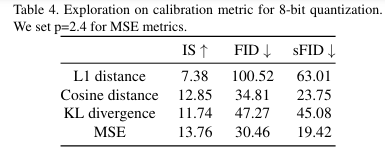
MSE가 가장 우수하기 때문에 diffusion model을 quantization하기 위해 MSE를 채택함
More Experiments
CIFAR10의 32x32 이미지 생성하는 diffusion model 및 ImageNet에서 다운샘플된 64x64 이미지를 생성하는 확산모델을 선택하여 DDPM과 DDIM 양쪽에서 이미지를 생성하는 실험 진행함
1024개의 보정 샘플을 생성하고 네트워크를 8비트로 양자화한 뒤, 10000개의 이미지를 평가하기 위해 샘플링 함
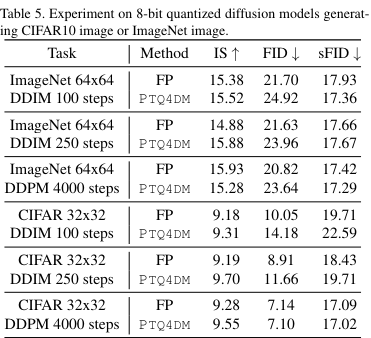
32×32 크기의 이미지를 생성하는 데 DDPM을 사용하는 설정에서, 본 논문에서 제시한 방법으로 양자화된 8비트 DDPM이 전체 정밀도 DDPM을 능가
Conclusion
두 가지 상충되는 요인이 denoising process의 속도를 낮춤
- 긴 반복
- 각 반복에서 노이즈를 추정하는 무거운 네트워크
이전의 주류 DM 가속화 작업은 1에 집중하는 것과 달리, 본 논문에서는 2에 대하여 탐구함
본 논문에서는 Pre-Training Quantization for Diffusion Models (PTQ4DM)를 제안함
해당 방법은 사전 훈련된 확산 모델을 상당한 성능 저하 없이 직접 8비트로 양자화할 수 있음. 이 방법은 DDIM과 같은 빠른 샘플링 방법에 추가될 수 있다는 특징이 있음
