📄Imagic: Text-Based Real Image Editing with Diffusion Models
written by Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang1 Tali Dekel, Inbar Mosseri, Michal Irani
Introduction
이미지 처리에서 실제 사진에 비단순한 의미적 편집을 적용하는 것이 오랫동안 흥미로운 과제였음

그러나 현재 많은 문제점에 직면하고 있는데,
- 특정 편집 세트에 한정됨
- 특정 도메인이나 합성 생성된 이미지에만 작동함
- 입력 이미지 외에도 편집 위치를 나타내는 이미지 마스크, 동일한 주제의 여러 이미지, 또는 원본 이미지를 설명하는 텍스트와 같은 보조 입력 필요
와 같은 점들이 잇음
본 논문에서는 이러한 한계를 극복하는 Imargic이라는 새로운 텍스트 기반 의미적 이미지 편집 방법을 제안함
Imargic은 텍스트 임베딩 시퀀스 사이의 선형 보간을 통해 텍스트-이미지 확산 모델의 구성 능력을 보여줌
실제 고해상도 이미지에서 복잡한 편집 수행이 가능하며, 전체 구조와 구성을 유지할 수 있고 나아가 다른 방법에 비해 편집 품질과 원본 이미지의 충실성이 뛰어남
Related Work
이미지 합성 품질의 최근 발전을 바탕으로, 많은 연구들이 사전 훈련된 GANs의 잠재 공간을 활용하여 다양한 이미지 조작을 수행함
최근 diffusion model 또한 조작 작업에 활용되며, 놀라운 결과를 보여주고 있음
본 논문에서는 단일 실제 이미지에 작동하는 최초의 텍스트 기반 의미적 이미지 편집 도구를 제공하며, 해당 이미지의 고유성을 유지하고 자유 형식의 자연어 텍스트 프롬프트를 사용하여 비강체적 편집을 적용함
Imagic: Diffusion-Based Real Image Editing
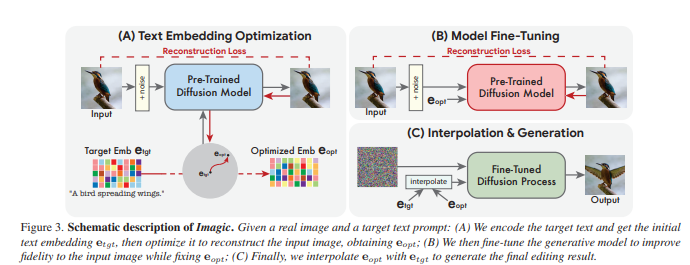
Text embedding optimization, Model fine-tuning, Text embedding interpolation stages로 구성
- Text embedding optimization
목표 텍스트를 통과시켜 가장 입력 이미지와 일치하는 텍스트 임베딩 찾기
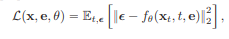
- Model fine-tuning
최적화된 임베딩을 이용하여 입력 이미지를 가장 잘 재구성하는 방향으로 모델 파라미터 최적화 - Text embedding interpolation
목표 텍스트 임베딩과 최적 임베딩 사이를 선형으로 보간하여 원하는 편집 적용
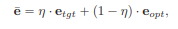
Implementation Details
해당 프레임워크는 general하고 can be combined with different generative models
두 state-of-the-art text-to-image generative diffusion 모델인 Imagen과 Stable Diffusion을 통해 증명함
-
Imagen
64x64 픽셀 이미지에 대한 확산 모델을 포함하며, 64x64 픽셀 이미지를 256x256 픽셀로 슈퍼 해상도(SR)하는 확산 모델 및 256x256 픽셀 이미지를 1024x1024 해상도로 슈퍼 해상도하는 또 다른 모델로 구성이들 중 64x64 확산 모델을 사용하여 텍스트 임베딩을 최적화하고, 최적화된 임베딩을 사용하여 입력 이미지를 fine-tune함. 또한 원본 이미지로부터 고부차 세부 정보 캡처위해 SR 확산 모델을 fine-tune함
해당 프로세스는 이미지 당 약 8분 소요
-
Stable Diffusion
pre-trained auto encoder의 잠재 공간에서 확산 프로세스 적용
1000단계 동안 텍스트 임베딩 최적화하고, diffusion model을 1500단계동안 fine-tune해당 프로세스는 단일 Tesla A100 GPU에서 약 7분이 소요
Experiments

various editing categories on general input images and text가 가능함을 알 수 있음

versatility를 볼 수 있음

slightly tweaking η for each seed를 통해 다양한 옵션을 가질 수 있음
→ different options, as natural language text prompts can generally be ambiguous and imprecise를 사용자가 선택할 수 있음을 알 수 있음
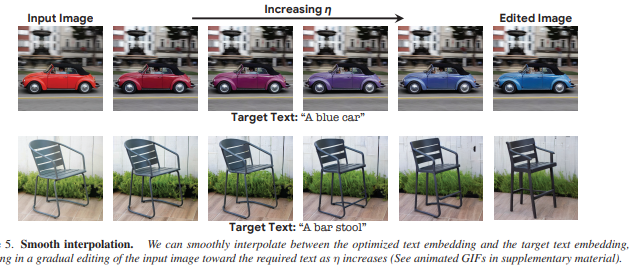
complex non-rigid edits 수행을 성공적으로 함을 알 수 있음
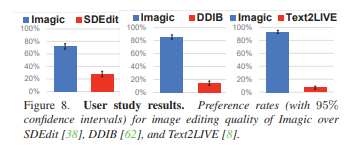
다른 모델에 비해 사용자에게 있어서 선호도가 높음을 알 수 있음
Limitations
- 경우에 따라 원하는 편집이 매우 미묘하게 적용되어 목표 텍스트와 잘 일치하지 않는 경우 발생
- 편집은 잘 적용되지만 줌이나 카메라 각도와 같은 외부 이미지 세부 사항에 영향을 미치는 경우 발생

Conclusions and Future Work
본 논문에서는 Imagic이라는 새로운 이미지 편집 방법을 제안함
단일 이미지와 원하는 편집을 설명하는 간단한 텍스트 프롬프트를 입력으로 받아들이고, 입력 이미지의 최대한 많은 세부 사항을 보존하면서 해당 편집을 적용하는 것을 목표로 함
이를 위해 사전 훈련된 텍스트-이미지 확산 모델을 활용하여 입력 이미지를 나타내는 텍스트 임베딩을 찾고, 확산 모델을 이미지에 더 잘 맞도록 세밀하게 조정한 뒤 이미지를 나타내는 임베딩과 대상 텍스트 임베딩 사이를 선형보간하여 의미 있는 혼합물을 얻어냄
이를 통해 보간된 임베딩을 사용하여 수정된 이미지를 제공할 수 있었음. 다른 편집 방법과 다르게 단순한 스타일 도는 색상과 같은 더 간단한 편집과 함께, 요청된대로 이미지 내 객체의 포즈, 기하학 및 구성을 변경할 수 있는 정교한 비유체적 편집 생성 가능함/
후에 입력 이미지에 대한 충실도, 정체성 보존 능력, 임의 시드 및 보간 매개변수 η에 대한 민감도를 더 개선하는 데 중점을 둘 것임
순수한 생성 방법보다는 주로 입력 이미지를 기반으로 하기 때문에 어느 정도는 기존의 텍스트 기반 생성 모델의 사회적 편향에 노출될 수 있음. 더하여 악의적인 의도로 가짜 이미지 생성이 가능하기 때문에 이를 해결하기 위해 수정/생성 된 contents를 식별하기 위한 추가 연구가 필요함
