📄Scalable Diffusion Models with Transformers
written by William Peebles and Saining Xie
Introduction
transformer로 인하여 머신러닝은 르네상스 시기를 겪고 있음. 그러나 다른 분야들에 비하여 이미지 생성은 transformer를 이용한 framework가 적음
standard U-Net(기존의 generative modeling framework)과 비교하였을 때, additional spatial transformers에 필요한 요소인 self-attention blocks는 interspersed at lower resolutions.
본 논문에서는 new class of diffusion models based on transformers에 초점을 둠. 이때 이를 Diffusion Transformers, 즉 DiT로 부름
DiT는 ViT를 참고하여 생성됨
더하여 scaling behavior of transformers를 network complexity vs. sample quality의 측면에서 연구함
transformer가 U-Net 기반을 성공적으로 대체함
Related Work
Transformers
다양한 분야의 specific architectures를 대체함
remarkable scaling properties under increasing model size, training compute and data in the language를 보여줌
autogressively predict pixels를 하도록 훈련되고, 더하여 discrete codebooks로 훈련됨
20B parameters까지 scaling할 수 있는 훌륭함을 보여줌
본 논문에서 제시되는 모델의 backbone으로 사용됨
Denoising diffusion probabilistic models (DDPMs)
sampling techniques의 improve에 많은 영향을 미침
픽셀을 예측하는 것 대신, 노이즈를 예측
노이즈를 점차적으로 삭제해가며 이미지를 생성함
Architecture complexity
대체적으로 parameter counts는 모델의 복잡도에 poor proxies.
이를 대신하여 본 논문에서는 복잡도로 계산의 길이를 분석함
더하여 transformer class에 집중하도록 함
Diffusion Transformers
Preliminaries
-
diffusion formulation
-
Gaussian diffusion models aussume a forward noising process which gradually applies noise to real data

-
diffusion models are trained to learn the reverse process that inverts forward process corruptions

-
reverse process model은 log likelihood의 variational lower bound로 학습
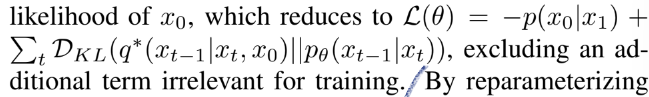
-
-
Classifier-free guidance
-
encourage the sampling procedure to find x such that logp(c|x) is high에 사용
-
베이즈 룰을 따라서 계산됨
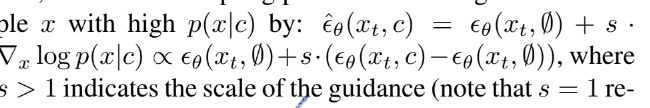
-
diffusion model을 평가할 때 랜덤으로 c를 드롭하고 null로 대체
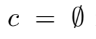
-
-
Latent diffusion models
-
two-stage approach를 따름
- 이미지를 smaller spatial representations로 압축하는 autoencoder E 학습
- diffusion model of images x 대신 diffusion model of representations z = E(x) 학습
새로운 이미지는 representation z를 diffusion 모델에서 샘플링함으로써 생성, subsequently 그것을 이미지로 학습한 디코더 x=D(z)를 통해 이미지로 디코딩
-
Diffusion Transformer Design Space
based on the Vision Transformer(ViT) architecture which operates on sequences of patches
DiT는 ViT의 best practices를 가지고 있음
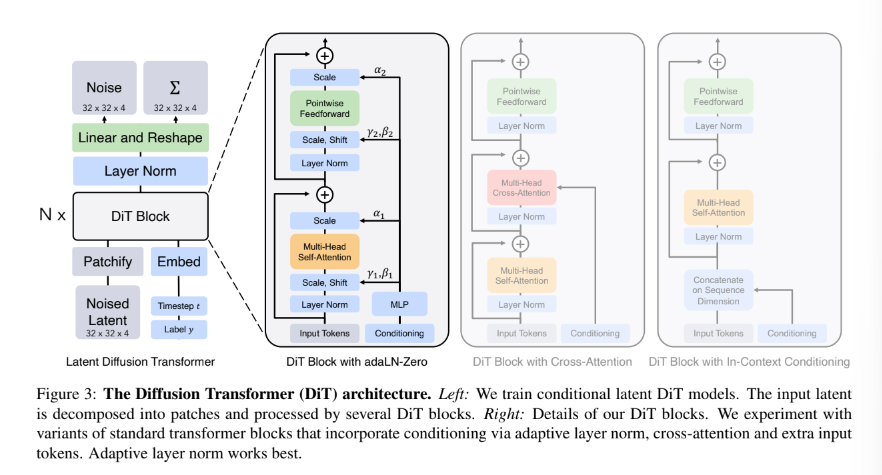
- Patchify
convert the spatial input into a sequence of T tokens
standard ViT frequency-based positional embedding 적용하여 패치화 - DiT block design(transformer block 후보들)
- In-context conditioning
append the vectore embeddings of t and c as two additional tokens in the input sequence
ViT의 cls tokens과 유사
새로운 Gflop 도입되나 무시 가능 - Cross-attention block
concatenate the embeddings of t and c into a length-two sequence, separate from the image token sequence
모델의 Gflops의 약 15% - Adaptive layer norm(adaLN) block
replacing standard layer norm layers in transformer blocks with adaptive layer norm
adaLN은 적은 양의 Gflops 더하여 compute-efficient 향상시킴 - adaLN-Zero block
U-Net models가 zero-initializing하는 것과 같은 역할을 하는 modification of the adaLN DiT block
- In-context conditioning
Model size

Transformer decoder
output은 original spatial input과 shape이 같아야 함
이를 위해 standard linear decoder 사용
마지막 layer norm apply 후 pxpx2C tensor로 decode
predicted noise and covariance를 얻기 위하여 최종적으로 디코딩 된 토큰들을 original spatial layout으로 rearrange
Experimental Setup
training
ImageNet dataset 사용하여 학습
final linear layer을 0으로 초기화하고 다른 layer들은 ViT의 standard weight initalization techniques 사용
모든 모델은 AdamW를 사용하여 학습
learning rate는 10^(-4)로 설정
배치사이즈는 256으로 설정
data augmentation은 horizontal flip만 사용
ViT와 달리 learning rate warmup, regularization 필요하지 않았음
diffusion
선수학습된 Stable Diffusion의 VAE 모델 사용
VAE 인코더는 has a downsample factor of 8
RGB image x(256x256x3)를 z(=E(x), 32x32x4) 로 downsample, 모든 섹션에서 진행
VAE 디코더를 통해 디코딩
diffusion hyperparameters from ADM 재학습
Evaluation metrics
생성모델의 standard 평가 metric인 FID를 통해 성능 측정
정확한 비교를 위해 ADM's TensorFlow evaluation suite 사용
추가로 Inception Score, sFID, Precision/Recall도 측정함
Experiments
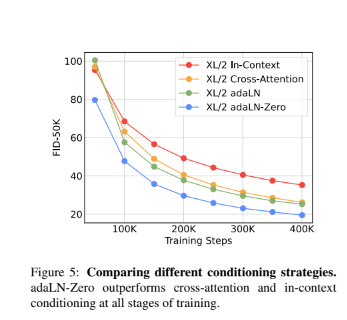
위의 그래프를 통하여 conditioning mechanism이 ciritically하게 모델의 퀄리티에 영향을 미침을 알 수 있음. 더하여 초기화 또한 중요함을 알 수 있음
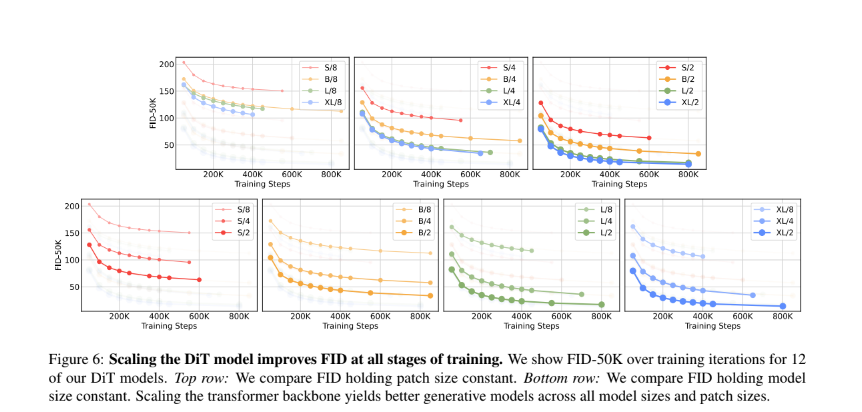
위의 그래프를 통하여 모델 사이즈가 커지고 패치 사이가 작아질수록 considerably diffusion model의 성능을 향상시킴을 알 수 있음
더하여 모델의 Gflops를 스케일링하는 것이 성능향상의 key라는 것을 알 수 있음

Gflop에 따라 이미지 퀄리티가 달라짐을 확인할 수 있음
state-of-the-art
-
256x256 ImageNet
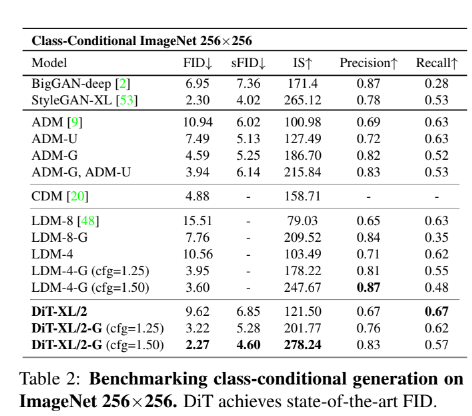
DiT-XL/2-G가 성능이 뛰어남을 확인할 수 있음 -
512x512 ImageNet
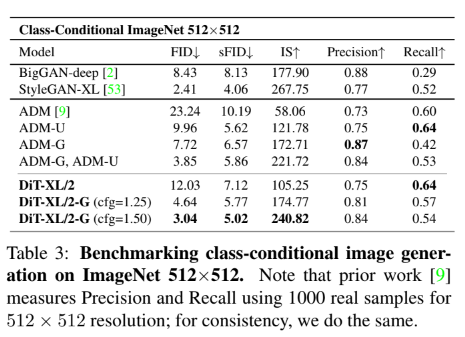
여기서도 또한 DiT-XL/2-G가 성능이 뛰어남을 확인할 수 있음
Scaling Model vs. Sampling Compute
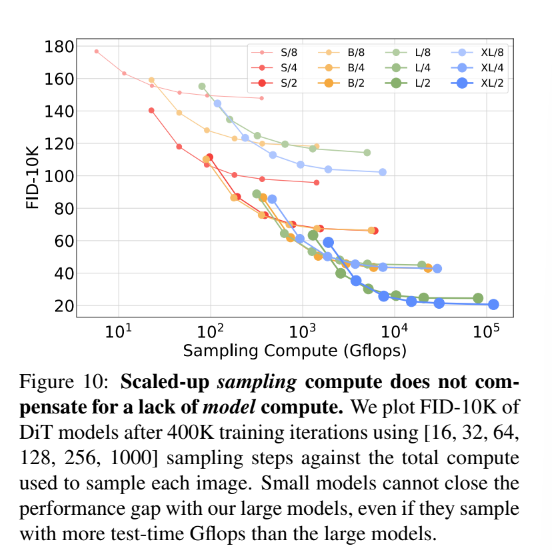
대체적으로 scaling-up sampling compute는 compenstae for a lack of model compute 할 수 없음
Conclusion
본 논문에서는 simple transformer-based bacbone for diffusion models인 Diffusion Transformer(DiTs)에 대하여 소개함
이는 이전의 U-Net 모델들보다 성능이 뛰어나고, 트랜스포머 모델의 excellent scaling properties를 계승함
future work는 DiT를 더 큰 모델과 토큰들을 통해 scale이 가능하게 하는 것.
더하여 DiT는 text-to-image 모델의 기반 또한 될 수 있을 것임
