📄AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
written by Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Duhua Lin, and Bo Dai
Introduction
T2I(Text-to-Image) diffusion models는 아티스트와 아마추어들이 비주얼 콘텐트를 텍스트 프롬프트를 사용하여 생성하는 것에 대해 많은 영향을 주었음
지금까지 다양한 모델들이 개발되었지만, 그들은 정적 이미지만 생성해내기 때문에 애니메이션과 같은 동적 콘텐츠 생성에는 적합하지 않고 더하여 비용과 계산적 비효율로 인해 실용적이지 않음
본 논문에서 제안하는 AnimateDiff는 기존의 고품질 개인화된 T2I 모델을 애니메이션 생성기로 직접 변환 가능함
해당 모델의 핵심은 비디오 데이터셋으로부터 합리적인 모션을 학습하는 플러그 앤 플레이 모션 모듈을 훈련하는 접근법
AnimateDiff의 훈련 단계
- 기본 T2I에 도메인 어댑터를 미세조정하여 대산 비디오 데이터셋의 시각적 분포와 일치시킴
- 기본 T2I를 함께 확장하고, 새로운 초기화된 모션 모듈을 소개하여 비디오에서 모션 모델링 최적화
- 미세 조정 기술(LoRA) 사용하여 사전 훈련된 모션 모듈을 특정 모션 패턴에 적응시킴
이러한 접근을 통해 본 논문에서는,
- 특정 미세 조정 없이 개인화된 T2I의 애니메이션 생성 능력 활성화시킬 수 있는 실용적 파이프라인 제시
- Transformer architecture가 모션 사전을 모델링하는 데 충분함을 검증하고, 비디오 생성에 대한 중요한 통찰력 제공
- 새로운 모션 패턴에 사전 훈련된 모션 모듈을 적응시키기 위한 가벼운 미세 조정 기술인 MotionLoRA 제안
- 접근방식을 대표적인 커뮤니티 모데로가 비교하여 포괄적으로 평가하고 다른 상업적 도구와 비교, 호환성 보여줌
에 대하여 이야기 함
Related Work
Text-to-image diffusion models
Text-to-image 생성을 위한 diffusion models는 최근 많은 주목을 받고 있음
- GLIDE
text conditions에 대해 소개하고 incorporating classifier guidance가 더욱 만족스러운 결과를 도출해낼 수 있다는 것에 대해 증명 - DALL-E2
CLIP 공동 특징 공간 활용하여 text-image alignment 향상 - Imagen 대형 언어 모델과 cascade architecture 통합 통해 photorealistic results 달성
- Latent Diffusion Model(=Stable Diffusion)
diffusion process를 auto-encoder의 잠재 공간으로 이동하여 효율성 향상 - eDiff-I
다양한 생성 단계에 특화된 확산 모델 앙상블을 사용
Personalizing T2I models
사전 훈련된 T2I로 창작 용이하게 하기 위해 많은 작업이 효율적인 모델 개인화에 초점 맞추고 있음
- DreamNooth
보존 손실 사용하여 네트워크 전체를 미세 조정하고 소수 이미지만 사용 - Textual Inversion
각 새로운 개념에 대한 토큰 임베딩 최적화 - Low-Rank Adaption
기존 T2I에 추가적인 LoRA 레이어 도입하여 가중치 잔차만 최적화
Annimating personalized T2Is
기존 작업 많지 않음
- Tune-a-Video
단일 비디오에서 소수의 매개변수 미세 조정 - Text2Video-Zero
사전 정의된 아핀 행렬 기반 사전 훈련된 T2I 애니메이션화하는 training-free method 소개
Preliminary
본 논문에서 소개하는 AnimateDiff의 base T2I model인 Stable Diffusion과 LoRA에 대하여 소개함
Stable Diffusion(SD)
open-sourced, well-developted community with many high-quality personalized T2I models for evaluation의 이유로 base T2I 모델로 선정
forward diffusion 식
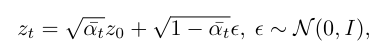
denoising network
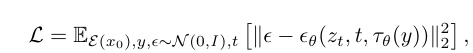
MSE loss 통해 계산됨
- ϵθ(·) is implemented as a UNet (Ronneberger et al., 2015) consisting of pairs of down/up sample blocks at four resolution levels, as well as a middle block
- Each network block consists of ResNet spatial self-attention layers, and cross-attention layers that introduce text conditions
Low-rank adaptation(LoRA)
approach that accelerates the fine-turning of large models and is first proposed for language model adaption
model의 parameters를 retraining하는 것 대신 pairs of rank-decomposition matrices 더하여 optimizes only these newly introduced weights함
기존의 weights는 frozen시키고 학습가능한 파라미터를 제한함으로써 catastrophic forgetting 발생 확률을 낮춤
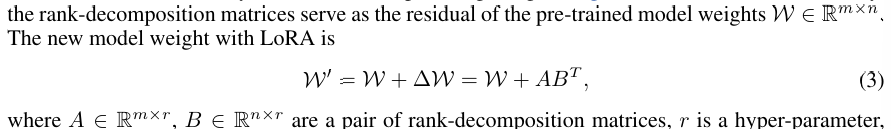
LoRA는 오직 attention layers에만 적용됨
AnimateDiff
core of this method
learning transferable motion priors from video data, which can be applied to pesonalized T2I without specific tuning
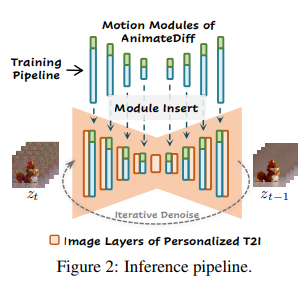
inference time에 our motion module(푸른색)과 optional MotionLoRA(초록색)는 directly personalized T2I에 insert됨. 이를 통해 animation generator(순차적으로 노이즈를 없앰으로써 애니메이션 생성하는 생성자)를 구성함
AnimateDiff를 구성하는 세 가지 요소인 domain adapter, motion module, MotionLoRA를 학습시킴으로써 위의 구조도를 achieve할 수 있었음
Alleviate Negative Effects from Training Data with Domain Adapter
비디오 훈련 데이터셋은 이미지 데이터셋에 비해 시각적 품질 낮아 모션 블러, compression artifacts. watermarks 등의 문제 발생 가능함. 이러한 품질 퀄리티 낮음은 애니메이션 생성 파이프라인에 부정적 영향 미칠 수 있음
퀄리티의 차이를 학습하지 않고 기존 T2I의 knowledge를 보존하기 위하여 fit the domain information to a separate network를 실시함. 추론 시 도메인 어댑터 제거함으로써 domain gap으로 인한 부정적 영향을 줄일 수 있었음
domain adapter layer는 LoRA를 사용하여 구한되고 기본 T2I의 self-/cross-attention layer에 삽입함
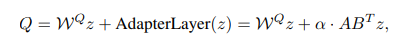
Learn Motion Priors with Motion Module
- 2차원 확산 모델을 3차원 비디오 데이터와 처리하도록 확장
- 효율적인 정보 교환을 위한 하위 모듈 설계
네트워크 확장은 이미지 레이어를 비디오 프레임에 독립적으로 적용하여 기존의 고품질 콘텐츠 유지
모듈 설계는 최근 비디오 생성 작업에서 탐구된 여러 디자인 기반으로 transformer architecture 사용하고, 시간 축에 맞게 약간의 수정을 통해 time transformer로 참조
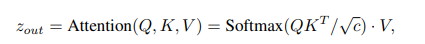
이를 통해 시각적 내용의 변화 학습하여 애니메이션 클립의 운동 역학 구성하도록 T2I model 확장시킴
Adapt to New Motion Patterns with Motion LoRA
pre-trained motion module은 일반적인 운동 우선 순위를 캡처하지만, 새로운 운동 패턴에 효과적으로 적응해야 할 때 문제 발생
해결 위하여 적은 수의 참조 비디오와 훈련 반복 통해 모션 모듈을 특정 효과에 대해 미세 조정할 수 있는 요율적인 미세 조정 접근 방법인 MotionLoRA를 사용함
MotionLoRA는 LoRA 레이어를 활용하여 새로운 운동 패턴의 참조 비디오에서 훈련되고, 적은 자원으로도 좋은 결과 얻을 수 있음. 이러한 낮은 순위 특성을 활용하여 개별적으로 훈련된 모델을 결합하여 추론 시에 다양한 모션 효과 달성 가능함
이를 통해 사용자는 비용 부담 없이 모션 모듈을 원하는 효과에 맞게 조정 가능함
AnimateDiff in Practice
-
training
domain adapter는 train with original objective
motion module and MotinoLoRA, as part of an animation generator, use a similar objective with minor modifications to accommodate higher dimension video data

-
inference
추론 시 personalized T2I model은 처음에 inflated되고, motion module for general animation generation이 injected됨.
선택적으로 MotinoLoRA가 personalized motion을 사용하여 애니메이션을 생성함
domain adapter의 경우, 단순히 추론 때 버리는 대신 개인화된 T2I모델에 주입하고 스케일러 alpha를 변경하여 기여 조정 가능함
Experiments
Qualitative Results

Quantitative Comparison
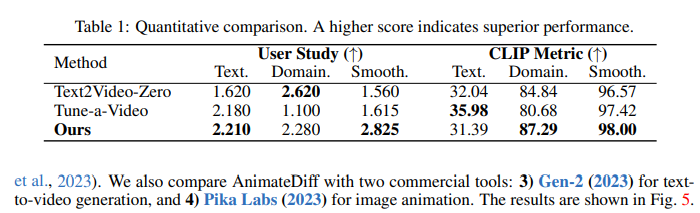
user study에서 본 논문에서 제시한 모델이 높은 값을 보여줌을 알 수 있음
CLIP metric에서 또한 높은 값을 가짐을 알 수 있음

Conclusion
본 논문에서는 quality를 희생하지 않고 pre-trained domain knowledge를 잃지 않고도 한 번에 개인화된 T2I 모델을 애니메이션 생성용으로 직접 변환하는 Animatediff를 제안함
이를 위해 의미 있는 운동 우선 순위를 학습하고 시각적 품질 저하를 완하하며 MotionLoRA라는 경량 미세 조정 기술을 사용하여 운동 개인화를 가능하게 하는 세 가지 구성 요소 모듈을 설계함
AnimateDiff는 기존의 내용 제어 접근 방식과의 호환성을 보여 추가적인 훈련 비용 없이 제어 가능한 생성을 가능하게 함
AnimateDiff는 개인화된 애니메이션을 위한 효과적인 기준을 제공하며 다양한 응용분야에 대한 잠재력을 지니고 있음
