📄Tabular Data: Deep Learning is Not all you need
written by Ravid Shwartz-Ziv, and Amitai Armon
Introduction
일반적인 데이터 유형은 tabular data가 있는데, 이는 행과 열로 이루어져 있음. tabular data는 다양한 분야에서 사용되며 relational database를 기반으로 하는 업무에 주로 사용됨. 지난 10년 동안 Gradient-boosted decision trees(GBDT)와 같은 모델들이 DNN보다 우수한 성능을 보여주었음.
DNN은 tabular data를 사용할 때, lack of locality, data sparsity, mixed feature types 및 데이터 구조에 대한 alck of prior knowledge 등의 다양한 어려움을 겪음. 더하여 block box로 인한 문제도 지니고 있음.
최근 tabular data에 대한 DN을 개발하려는 시도가 여러 번 있었는데, 그 중 일부는 GBDT보다 우수한 성능은 보인다고 주장되었다. 그러나 서로 다른 데이터셋을 사용했기 때문에 tabular data model을 정확하게 비교하는 것은 어려움. 그리고 일부 연구들은 이러한 모델들을 동일하게 최적화하지 않음.
따라서 DNN이 tabular data에 대하여 GBDT를 능가하는지 어떤 모델이 최고의 성능을 보이는지에 대한 결론이 불분명함. 이러한 점들은 연구 및 개발 과정을 방해하며, 해당 논문들의 결론을 명확하게 이해하는 데에 어려움이 발생함.
본 논문의 주 목적은 최근 제안 된 deep model 중 어떤 것이 tabular dataset problem에 적합한지 조사함.
이는 두 질문으로 평가함
- 논문에 등장하지 않은 데이터셋에 대해서도 모델들이 정확한가?
- 훈련 및 hyperparameter 검색에 소요되는 시간은 다른 모델들과 비교하여 어떤가?
이러한 질문에 대한 답을 위하여 최근 제안된 딥러닝 모델과 XGBoost를 다양한 tabular dataset에서 동일한 tuning protocol로 평가함.
Background
Deep Neural Models for Tabular Data
-
Differentialble trees
tabular data에서 decision tree ensemble의 성능이 우수하기 때문에 이러한 decision tree를 differentiable하게 만들 수 있음. decision tree의 미분 불가능하다는 문제를 해결하기 위해 internal tree node의 decision function을 smoothing함으로써 미분 가능하게 하고, tree function과 tree routing을 미분 가능하게 만드는 방법을 찾고 있음 -
Attention-based models
다양한 분야에서 널리 사용되고 있으며, 몇몇 저자들은 tabular deep network에 attention-like module 적용을 제안함. 최근 연구에서 datapoint 간의 상호작용을 나타내는 inter-sample attention과 주어진 샘플의 feature가 전체 행을 사용하여 상호작용하는 intra-sample attention을 제안함 -
TabNet
여러 데이터셋에서 잘 동작하는 딥러닝 end-to-end model. 인코더를 포함하며 순차적인 결정 단계에서 sparse learned mask를 사용. 인코더는 sparsemax layer를 사용하여 소수의 feature를 선택하도록 함. mask를 학습시킴으로써 feature에 대해 유동적인 결정을 할 수 있어 기존의 미분 불가능한 feature 선택 방법을 완화시킴 -
Neural Oblivious Decision Ensembles(NODE)
미분 가능하게 만든 동일한 깊이의 oblivious decistion tree(ODT) 포함함. ODT는 미분이 가능하여 backpropagation이 가능. 선택된 feature에 따라 데이터를 반할하고, 각각의 feature를 학습된 값과 비교. 한 번에 하나의 feature만 선택하여 균형잡힌 ODT를 얻을 수 있고, 이로 인해 미분이 가능해져 완전한 모델은 미분 가능한 trees의 ensemble 제공 -
DNF-Net
DNN에서 Disjunctive Normal Formula(DNF)를 시뮬레이트함. hard boolean formula를 미분 가능한 버전으로 대체하는 것이 제안됨. 주요 특징은 disjunctive normal neural form(DNNF) block으로 fully connected layer와 binary conjunction으로 이루어진 DNNF layer를 포함함. 완전한 모델은 여러 DNNF들의 ensemble -
1D-CNN
CNN구조가 feature 추출에서 잘 동작하지만 tabular data에서 feature ordering에 locality characteristic이 없기 때문에 거의 사용되지 않는다는 아이디어에서 기반. feature의 locality characteristic을 가진 더 큰 feature set을 만들기 위해 fully connected layer가 사용되며, 이후 몇 개의 1D-Conv layer가 shortcut과 같은 연결로 이어짐
Model Ensemble
모델의 성능을 향상시키고 분산을 줄이는 데에 널리 사용되는 방법. 여러 개의 모델을 동일한 작업을 해결하기 위해 훈련시키고, 예측들을 결합하여 최종 겨로가를 얻는 것을 목표로 함.
다른 모델들의 장점을 활용함으로써 더 안정적이고 정확한 예측을 제공함
enxemble은 주로 두 가지 유형으로 나뉨
- randomization 기반으로 한 방법
기본 학습자들이 독립적으로 훈련됨 - boosting 기반으로 한 방법
기본 학습자들이 순차적으로 훈련되어 이전 모델들의 오류 수정
본 논문은 ensemble에 TabNet, NODE, DNF-Net, 1D-CNN, XGBoost의 5개의 classifier를 사용했고, ensemble을 만들기 위해 두 가지 버전을 제시함
-
uniformly weighted mixture model로서 결합하는 방법
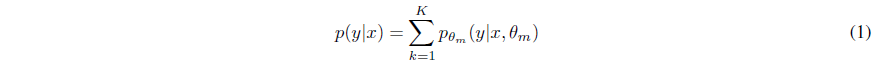
-
weighted average를 적용하여 결합하는 방법
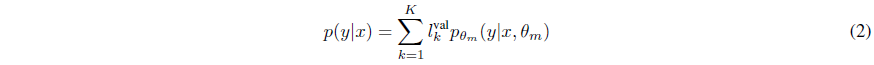
Comparing the Models
Experimental Setup
- Data-sets Description
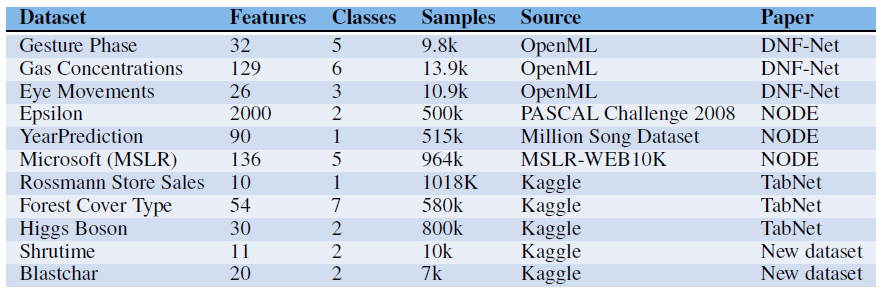
- Implementaion Details
hyperparameter 선택 위해 Bayesian optimization 사용하는 HyperOpt 사용
Results
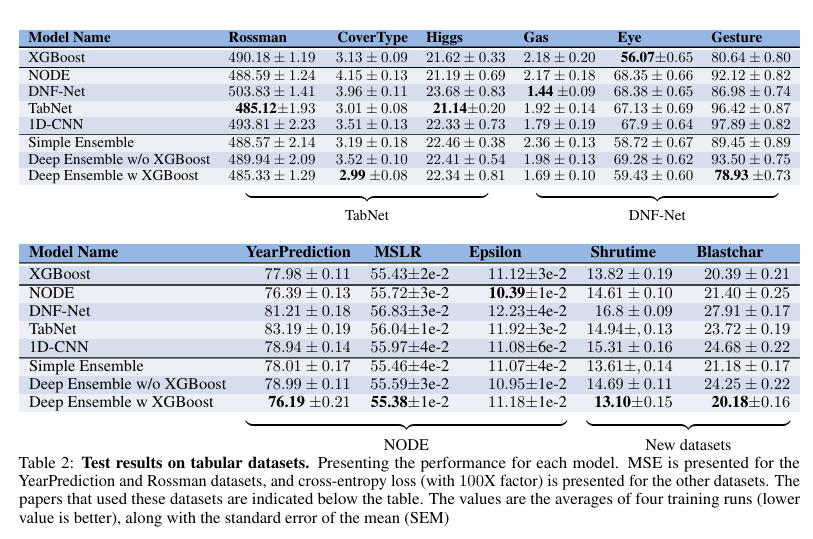
대부분의 경우, 논문에서 평가했던 데이터가 아닌 경우 좋지 않은 성능 보임
다른 Deep model과 비교했을 때, XGBoost가 더 좋은 성능 보임
모든 Deep model이 일관적으로 다른 모델보다 우수한 성능을 보여주지 않음
deep model과 XGBoost의 ensemble은 대부분의 경우 다른 모델들보다 우수한 성능 보임
XGBoost와 Deep model의 앙상블이 데이터셋 전체에서 가장 우수한 성능을 보임을 확인함. 이러한 결과로부터 XGBoost를 depp model과 결합해야 하는지, 아니면 nondeep model의 ensemble만으로도 유사한 결과를 얻을 수 있는지 확인해봄.
그 결과, deep model과 XGBoost를 결합하는 것이 이점을 제공함을 알아냄.
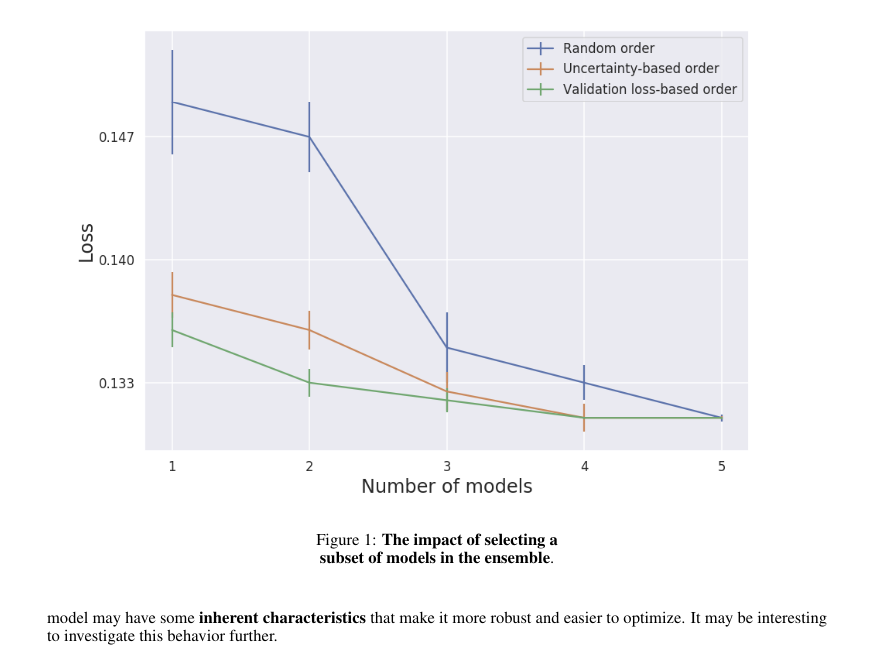
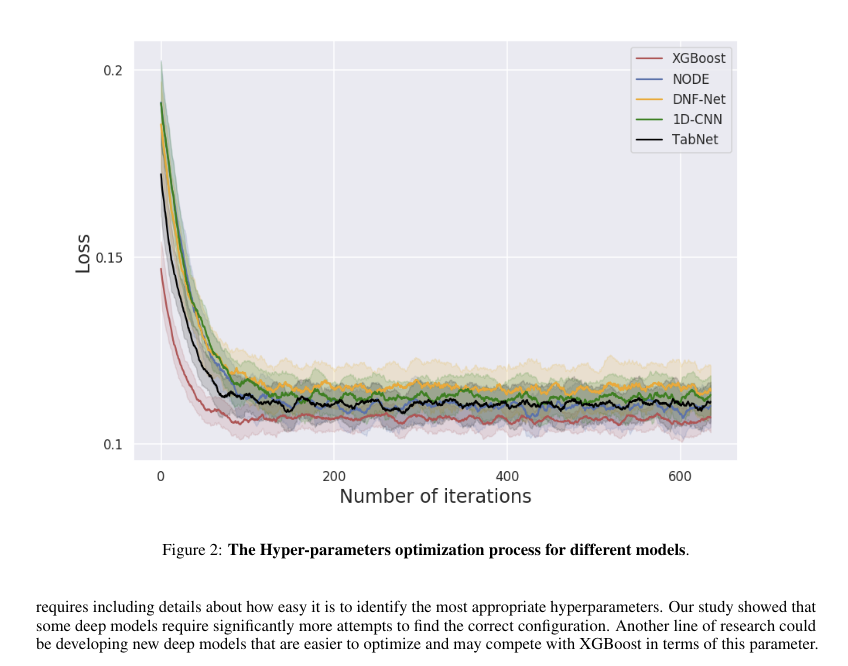
Discussion and Conclusions
본 논문에서는 최근 제안된 deep model이 tabular dataset에 대해 어떤 성능을 보이는지 조사함. 분석 결과, deep model은 원래의 논문에서 사용되지 않ㅇ느 데이터셋에서 약한 성능을 보였으며 XGBoost보다도 성능이 떨어졌음
본 논문에서는 이러한 deep model과 XGBoost의 ensemble을 제안함. 이는 individual model 및 non-deep classical ensemble보다 더 나은 성능을 보임. 더하여 실제 응용에서 중요한 performancem computational inference cost, hyperparameter optimization time을 연구함. 결과로 보고된 deep model의 성능은 그대로 받아들이기 힘들다는 결론을 얻음
결과적으로, 연구자들이 실제 응용에서 모델을 선택할 때는 여러 가지 요소를 고려해야 함. 시간제약이 있는 상황에서는 XGBoost가 최고의 결과를 얻고 최적화하기 쉽지만 최고의 성능을 달성하기는 어려울 수 있으며, 성능을 극대화하기 위해 deep model을 ensemble에 추가하는 것이 좋을 것임.
