📄SimMIM: a Simple Framework for Masked Image Modeling
written by Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu
Introduction
Masked signal modeling은 입력 신호의 일부를 마스킹하고 이 신호를 예측하는 방법을 학습하는 task 중 하나임. NLP에서 이러한 것에 기반을 두고 구축된 self-supervised learning 접근법은 masked signal modeling 분야를 크게 다시 그림
컴퓨터 비전에서는 self-supervised 표현 학습에 이를 활용하는 선구자들이 있지만, 이전에는 contrastive learning에 의해 거의 묻힘. 해당 task를 언어 및 비전 도메인에 적용하는 데 따른 다양한 어려움은 두 modality 간의 차이로 설명 가능함
- image는 더 강한 locality를 가짐. 서로 가까운 픽셀은 높은 상관관계가 있는 경향이 있어, 의미론적 추론이 아닌 가까운 픽셀을 복제하여 작업 수행 가능함
- 시각적 신호는 원시적이고 낮은 수준인 반면, text token은 사람이 생성한 수준 높은 개념임. 낮은 수준의 신호 예측이 높은 수준의 시각적 인식 작업에 유용한지에 대한 질문을 제기함
- 시각적 신호는 연속적이고 text token은 불연속적임. 연속적인 시각적 신호를 잘 처리하기 위해 clustering 기반 masked language modeling 접근 방식을 어떻게 적용할 수 있는지 알 수 없음
본 논문에서는 시각적 신호의 특성과 잘 일치하고 이전의 더 복잡한 접근법보다 더 유사하거나 더 나은 표현을 학습할 수 있는 간단한 프레임워크를 제시함
프레임워크의 key desings와 insights는 이러한 점들을 include하고 있음
- image patch에 random masking 적용
vision transformer에 적합하도록 image patch에 random masking 적용함
시각 및 언어 데이터의 정보 중복 정도가 다르기 때문에 mask 비율을 text domain과 다르게 적용함 - raw pixel regression task 사용
시각 신호의 연속적이고 순서가 있는 특성과 일치. 토큰화, 클러스터링 또는 이산화를 사용하는 분류 방법과 동등한 성능 보임 - extremely lightweight prediction head가 적용됨
매우 간단한 예측 헤드를 사용하여 이전보다 약간 더 나은 전이 성능을 보임. 속도향상, 높은 해상도, 다움스트림 작업과 같은 장점 지님
본 논문에서 제안하는 SimMIM 접근법은 간단하지만 표현 학습에 매우 효과적임
Related Work
Masked Language Modeling(MLM)
자연어 처리 분야에서 self-supervised larning 방식
문장이나 문장 쌍에서 보이는 토큰을 바탕으로 보이지 않는 토큰을 예측하여 표현 학습
3년 전부터 큰 영향을 미치고 있고, LLM의 학습을 가능케 하고, 방대한 데이터를 활용하여 언어 이해 및 생성 작업에서 일반화 성능이 뛰어남
Masked Image Modeling(MIM)
MLM 작업과 병행하여 발전했지만 오랫동안 비주류 위치에 있었음
최근 iGPT, ViT, BEiT 등이 vision transformer에서 해당 접근 방식을 다시 주목하며 특별한 디자인을 도입하여 강력한 표현 학습 가능성을 보여줌
SimMIM은 매우 간단한 프레임워크로, 보다 더 유사하고나 나은 효과를 보임
Reconstruction based methods
자동 인코더 접근 방식이 특히 관련이 있으며, 원래 신호를 복원하는 재구성 작업을 채택함
보이는 신호 재구성 철학에 기반하여, 본 논문의 접근 방식과는 다른 경로로 진행됨
Image impainting methods
표현 학습을 넘어서서, 마스크된 이미지 모델링은 이미지 인페이팅이라는 고전적인 컴퓨터 비전 문제
오랫동안 인페이팅 품질 향상을 목표로 연구되어 왔으며, self-supervised learning과 연결되지 않음
더 강력한 impaining 능력이 다운스트림 작업에서 더 나은 성능으로 이어지지는 않음
Compressed sensing
compressed sensing과 관련이 있으며, 대부분의 데이터는 거의 인지 손실 없이 제거될 수 있음
최근 희소 추론 연구에서도 대규모 이미지 특징을 제거해도 인식 정확도가 거의 떨어지지 않음
매우 적은 비율의 랜덤 선택 입력 image patch로도 인페이팅 작업을 통해 좋은 시각적 표현 학습 가능함
Approach
1. a Masked Image Modeling Framework
SimMIM은 input image signals의 일부를 masking하고 마스킹된 영역에서 원래의 signal을 예측하는 masked image modeling을 통해 표현을 학습함
프레임워크는 4개의 구성 요소 지님
-
Masking strategy
input image가 주어지면 마스킹할 영역을 선택하는 방법과 선택한 영역의 마스킹을 구현하는 방법 설계
마스킹 후 변환된 이미지가 input으로 사용됨 -
Encoder architecture
masking된 image에 대한 latent feature 표현을 추출한 다음 masking된 영역에서 원래 signal을 예측하는 데 사용
학습된 encoder는 다양한 vision task에 활용될 수 있을 것으로 기대됨
주로 Vanila ViT와 Swim Transformer의 두 가지의 일반적인 ViT architecture 고려함 -
Prediction head
latent feature 표현에 적용되어 마스킹된 영역에서 원래 신호의 한 형태를 생성함 -
Prediction target
예측할 원래 신호의 형태 정의
픽셀 값 또는 픽셀의 변환일 수 있음
Cross-entropy classification loss와 L1 or L2 regression loss를 포함한 일반적인 옵션으로 loss의 유형을 정의함
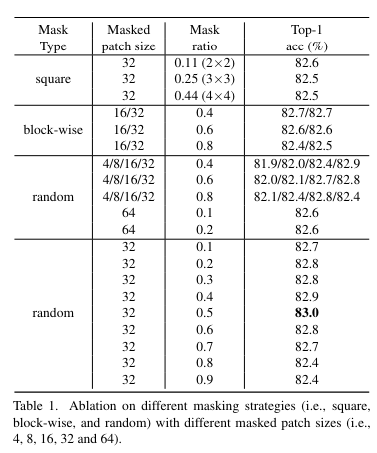
2. Masking Strategy
image patch는 ViT의 기본 처리 단위로 patch가 완전히 보이거나 완전히 masking되는 patch level에서 masking을 작동하는 것이 편리
Swim Transformer의 경우 서로 다른 해상도 단계의 등가 패치 크기인 4x4에서 32x32까지 고려하고, 기본적으로 마지막 단계의 패치 크기인 32x32 채택
ViT의 경우 기본 마스크 패치 크기로 32x32 채택
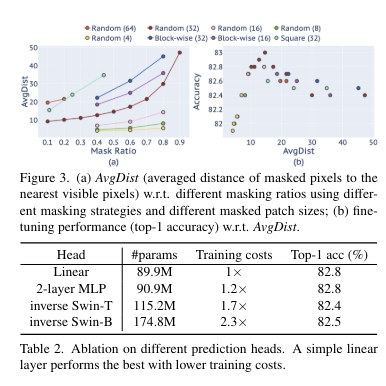
3. Prediction Head
input이 encoder의 output과 일치하고 output이 prediction target을 달성하는 한 임의의 형식과 용량을 가질 수 있음
초기 연구들은 heavy prediction head(decoder) 사용 위해 auto-encoder를 사용함
본 논문에서는 prediction head가 linear layer만큼 가벼울 정도로 매우 가벼워질 수 있음을 보임
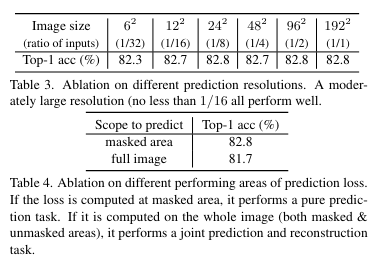
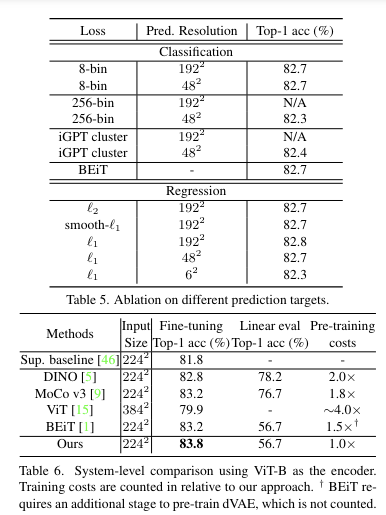
4. Prediction Targets
Raw pixel value regression
픽셀 값은 색상 공간에서 연속적. 간단한 option은 regression을 통해 masking된 영역의 pixel을 예측하는 것
일반적으로 vision architecture는 ViT에서 16배, 대부분의 다른 architecture에서 32배와 같이 downsampling된 해상도의 feature map을 생성함. 입력 이미지의 전체 해상도에서 모든 픽셀의 값을 예측하기 위해 feature map의 각 feature vector를 원래 해상도로 다시 mapping하고 해당 벡터가 해당 픽셀의 예측을 담당하도록 함
Experiments
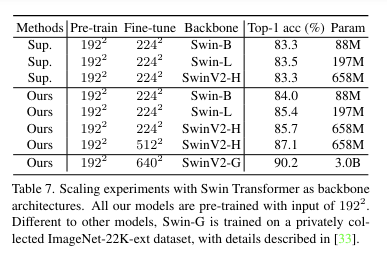


Conclusion
본 논문은 representation learing을 위해 masked image modeling을 활용하는 간단하면서도 효과적인 self-supervised learing framework인 SimMIM을 제안함
본 프레임 워크는 최대한 단순하게 구성됨
- 적당히 큰 mask patch 크기로 random masking 전략을 사용
- 직접 회귀 작업을 통해 RGB값의 원시 픽셀 예측
- prediction head는 linear layer만큼 가벼울 수 있음
본 논문은 강력한 결과와 단순한 프레임워크가 향후 이 분야의 연구를 촉진하고, AI 분야 간의 심층적인 상호작용을 장려할 수 있기를 바람
