그래프를 추천 시스템에 어떻게 활용할까? (기본)
우리 주변의 추천 시스템
- 아마존
- 메인 페이지 고객 맞춤형 상품 목록
- 특정 상품을 살펴볼 때 함께 or 대신 구매할 상품 목록
- 넷플릭스
- 메인 페이지 고객 맞춤형 영화 목록
- 유튜브
- 메인 페이지 고객 맞춤형 영상 목록
- 현재 재생 중인 영상과 관련된 영상 목록
- 페이스북
- 추천 친구 목록
- 추천 시스템과 그래프
- 사용자 각각이 구매할 만한 혹은 선호할 만한 상품을 추천함
- 그래프 관점에서 추천 시스템은 '미래의 간선을 예측하는 문제' 혹은 '누락된 간선의 가중치를 추정하는 문제'
내용 기반 추천 시스템
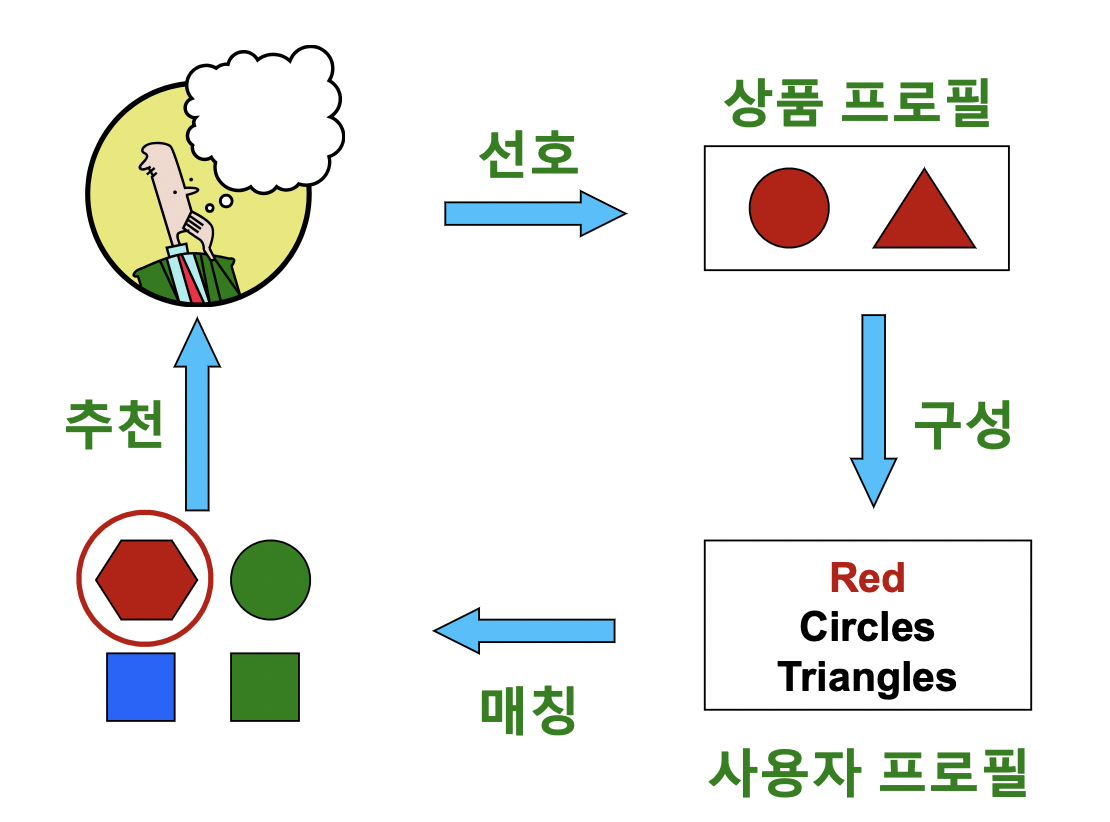
- 각 사용자가 구매 / 만족했던 상품과 유사한 것을 추천
- 동일한 장르의 영화 추천, 동일한 감독 영화, 동일한 배우 출현 영화 추천
- 동일한 카테고리 상품 추천
- 동갑의 같은 학교 졸업한 학생 친구로 추천
- 단계
- 1) 사용자가 선호했던 상품들의 상품 프로필 (Item Profile) 수집
- 상품 프로필은 해당 상품의 특성을 나열한 벡터, 영화의 경우 감독, 장르, 배우 등의 원-핫 인코딩이 상품 프로필이 됨
- 1) 사용자가 선호했던 상품들의 상품 프로필 (Item Profile) 수집
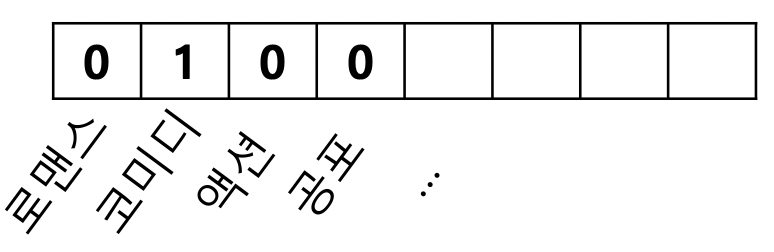
- 2) 사용자 프로필 (User Profile) 구성
- 사용자 프로필은 선호한 상품들의 상품 프로필을 가중 평균하여 계산. 사용자 프로필 역시 벡터.
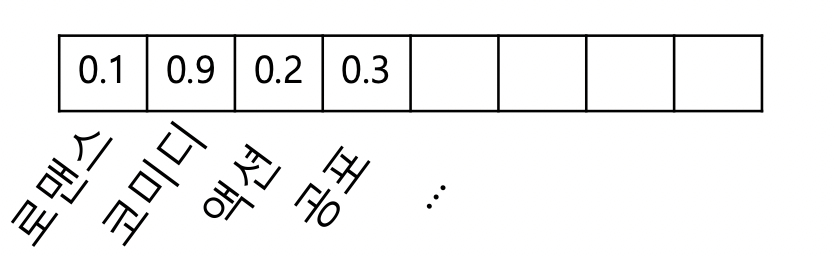
- 3) 사용자 프로필과 다른 상품들의 상품 프로필을 매칭
- 사용자 프로필 벡터 u 와 상품 프로필 벡터 v 에 대해 코사인 유사도 (내적/두벡터크기곱) 계산
- 사용자가 빨간 원, 빨간 삼각형을 선호했다면, 빨강 1, 원 0.5, 삼각형 0.5 이므로 후보들과 코사인 유사도를 계산하면 빨간 상품이 추천될 확률이 높음
- 4) 사용자에게 상품을 추천. 계산한 코사인 유사도가 높은 상품 추천
- 장점
- 다른 사용자의 구매 기록이 필요하지 않음 (자기 기록만 사용)
- 독특한 취향의 사용자에게도 추천 가능
- 새 상품에 대해서도 추천 가능
- 추천의 이유를 제공할 수 있음
- 빨간색 선호하니까 빨간색 추천
- 단점
- 상품에 대한 부가 정보가 없는 경우 사용 불가
- 구매 기록이 없는 사용자에게는 사용할 수 없음
- 과적합(오버피팅) 으로 지나치게 협소한 추천을 할 위험이 있음
- 빨간색만 계속 추천
협업 필터링
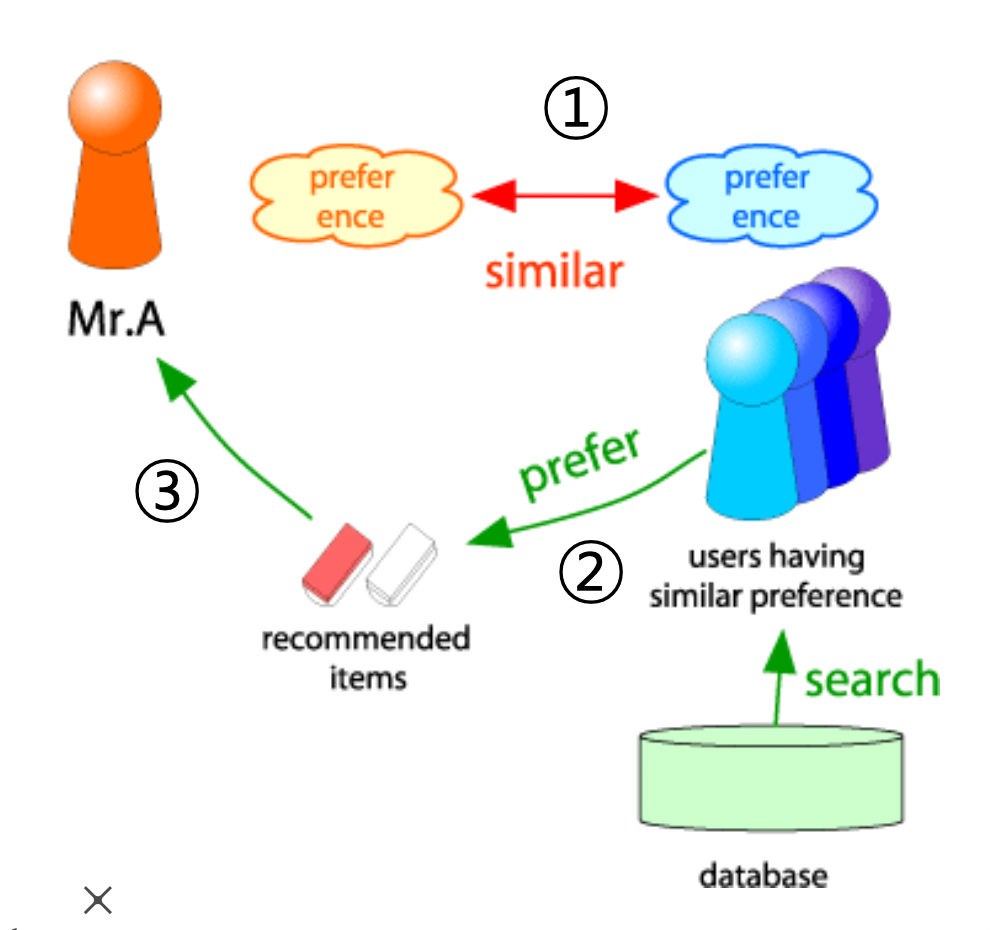
- 사용자-사용자 협업 필터링
- 단계
- 1) 대상 사용자 x 와 유사한 취향의 사용자들을 찾음
- 2) 유사한 취향의 사용자들이 선호한 상품을 찾음
- 3) 이 상품들을 x 에게 추천함
- 취향의 유사도를 어떻게 계산할까?
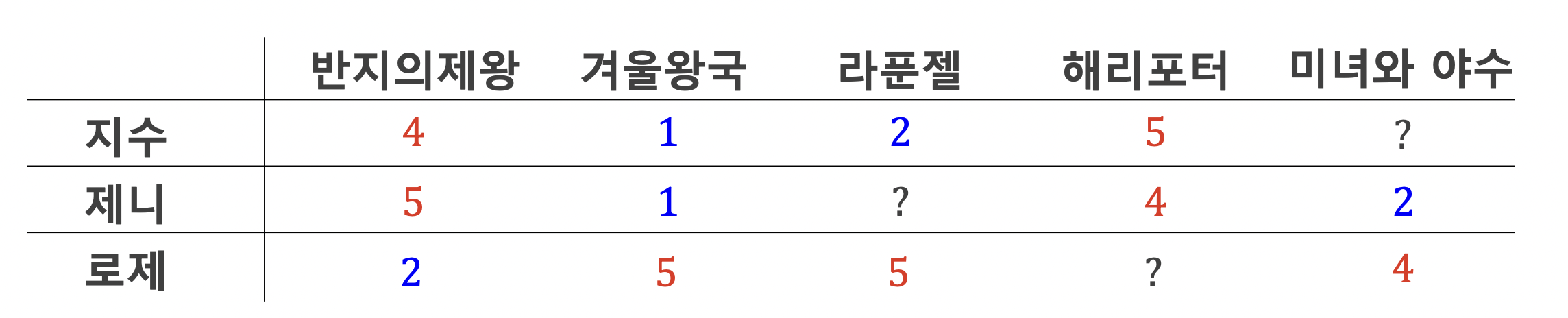
- 지수와 제니는 취향이 유사하고, 로제는 다른 취향을 가짐을 알 수 있음
- 피어슨 상관 계수 (Correlation Coefficient) 사용
- 상관 계수

- 두 사람이 한 상품에 대해 자신의 평균보다 높게 매기면 높아짐 (일치가 많아질 수록 양의값을 가짐)
- 각각 평균보다 높고 낮아지면 음의 값이 나옴 (불일치가 많아질 수록 음의값을 가짐)
- 분모는 정규화 목적

(*지수와 로제의 취향~ -> 지수와 제니의 취향~)
- 지수는 미녀와 야수를 좋아할 확률이 낮음, 비슷한 취향의 제니는 좋아하지 않고 다른 취향의 로제는 좋아했으므로
- 추천 과정
- 사용자 x 가 상품 s 에 대한 평가를 어떻게 할지, 에 대해 추정
- 상품 s 를 구매한 사용자 중, x 와 취향이 가장 유사한 k 명의 사용자 N(x;s) 를 뽑아냄
- 아래 수식 사용
- 사용자 x 가 상품 s 에 대한 평가를 어떻게 할지, 에 대해 추정
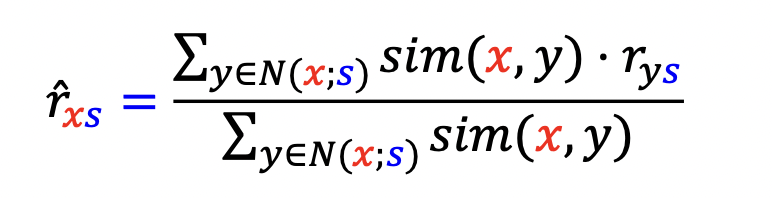
- x 가 구매하지 않은 여러 상품에 대해 위 과정을 진행하고 가장 추정 평점이 높은 상품을 추천
- 장점
- 상품에 대한 부가 정보가 없는 경우에도 사용 가능 (다른 사람의 평점 정보 필요)
- 단점
- 충분한 수의 평점 데이터가 누적되어야 효과적
- 새 상품, 새로운 사용자에 대한 추천 불가능
- 독특한 취향의 사용자에게 추천 힘듦
추천 시스템의 평가
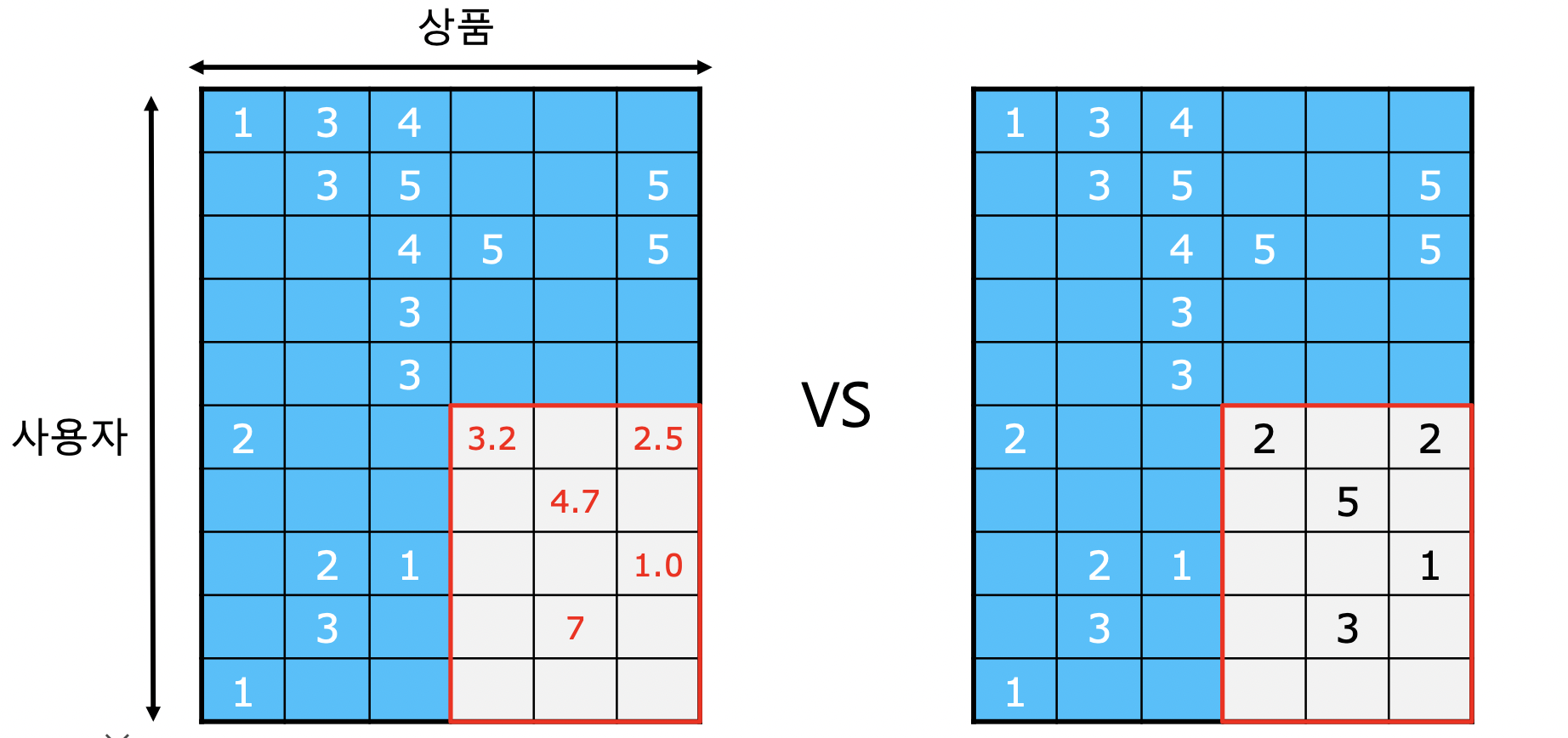
- 평점 데이터는 행렬로 표현 가능
- 훈련 데이터와 평가 데이터를 두고 평가 데이터의 평점을 추정함
- 추정 결과와 그라운드 트루스와 비교, loss 로 (MSE) 사용
- 이외에도 다양한 지표가 사용됨
- 추정 평점으로 순위를 매긴 후, 실제 평점의 순위와 상관 계수 계산
- 추천한 상품 중 실제 구매로 이루어진 것의 비율 측정
- 추천의 순서 혹은 다양성까지 고려하는 지표 사용
Further Reading
그래프를 추천시스템에 어떻게 활용할까? (심화)
넷플릭스 챌린지 소개
데이터셋
- 사용자별 영화 평점 데이터
- 트레이닝 데이터 : 2000~2005년까지 수집한 48만명 사용자의 1.8만개 영화에 대한 1억개 평점
- 테스트 데이터 : 각 사용자의 최신 평점 280만개
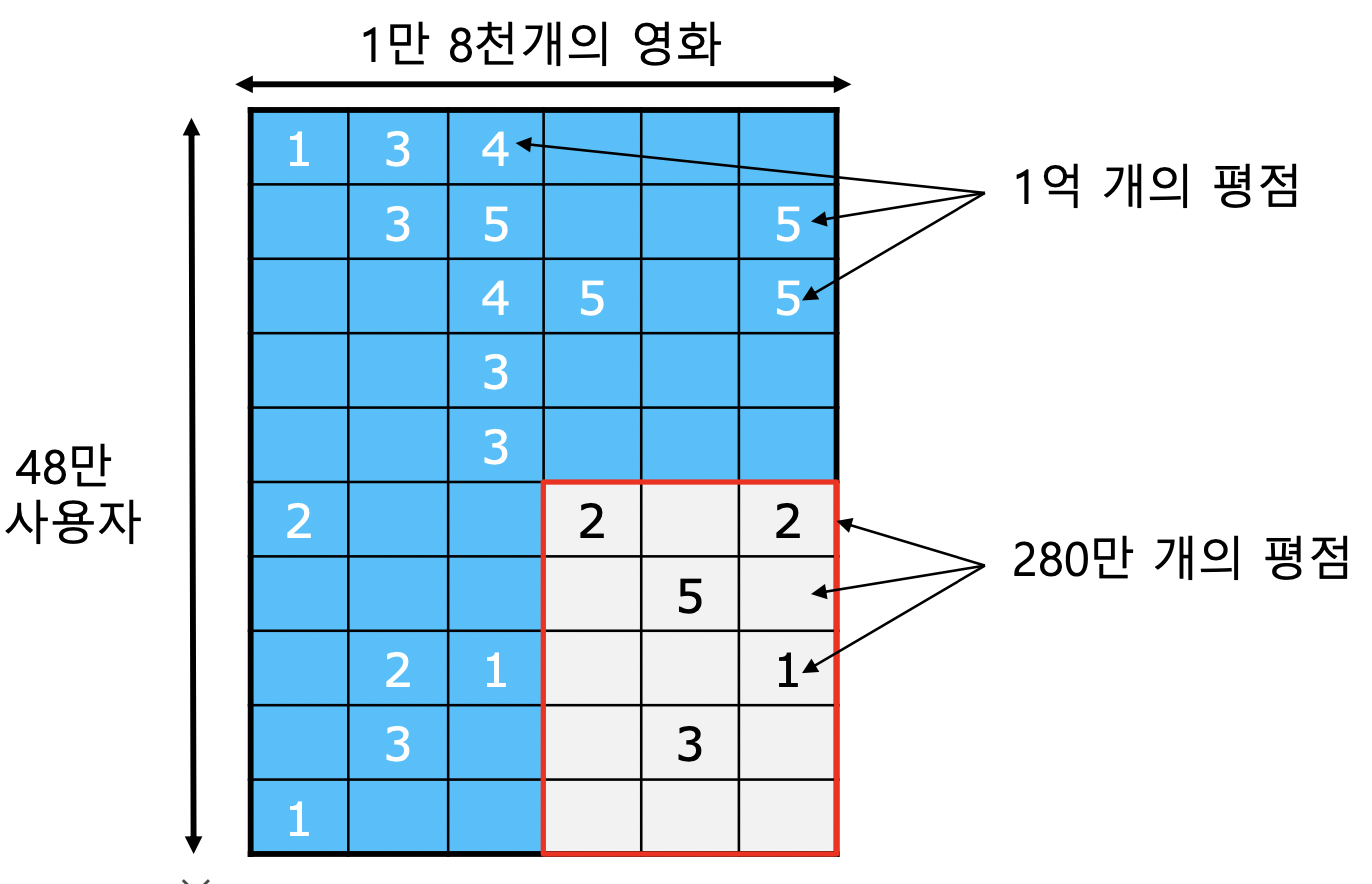
대회 목표
- 추천시스템 성능 10% 이상 향상
- MSE 를 0.9514 → 0.8563 까지 낮추면 100 만불 상금
- 2006~2009년 진행, 2700개 팀 참여, 추천시스템 성능 비약적으로 발전
- 성능

기본 잠재 인수 모형
개요
- 잠재 인수 모형 (Latent Factor Model, SVD 와 비슷하지만 다름) 의 핵심은 사용자와 상품을 벡터로 표현하는 것 (정점 표현 방법, 정점 임베딩)
- 사용자와 영화를 임베딩
- 고정된 인수 대신 효과적인 인수를 학습하는 것이 목표, 잠재 인수 = 학습한 인수
손실 함수
- 사용자와 상품을 임베딩하는 기준
- 사용자와 상품의 임베딩의 내적이 평점과 최대한 유사하도록 만듦
- 사용자 x 의 임베딩 , 상품 i 의 임베딩 , 사용자 x 의 상품 i 에 대한 평점 에 대해 pq 내적이 r 과 유사하도록 함
- 행렬 차원으로 보기
- 평점 행렬 R, 사용자 행렬 P, 상품 행렬 Q
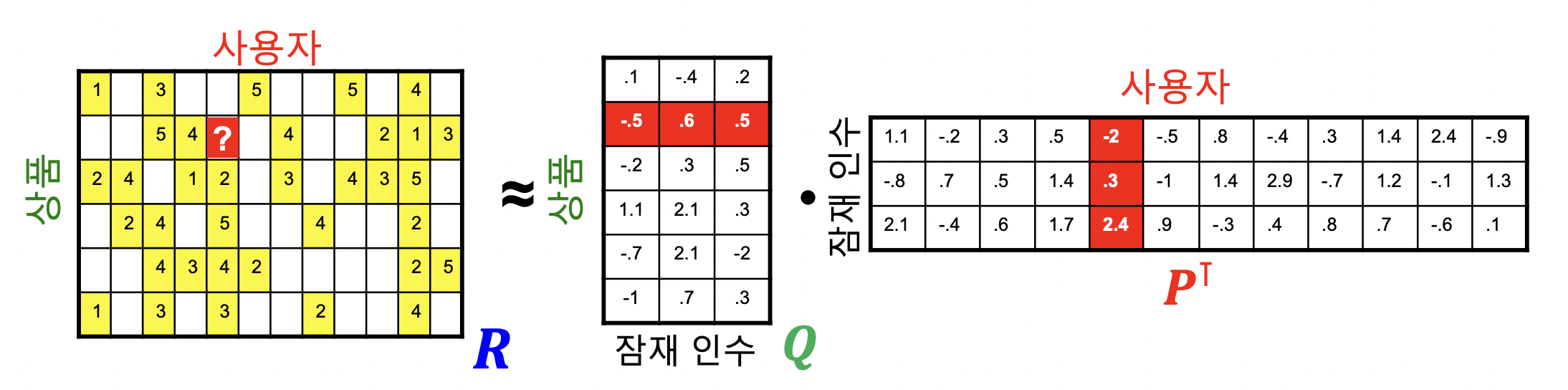
- 잠재 인수 모형은 아래 손실 함수를 최소화하는 P 와 Q 를 찾는 것을 목표로 함

- 위 손실 함수 사용할 시 오버피팅 (기계학습 모형이 훈련 데이터의 잡음까지 학습하여 테스트 성능 떨어지는 경우) 발생 가능
- 과적합을 방지하기 위해 정규화 항을 손실 함수에 더함 (L-2 Regularization 항 추가)

- 오차도 줄이고 모형 복잡도도 줄여야 함
- 임베딩이 너무 크면 잡음까지 배울 수 있기 때문에 임베딩을 줄여줌
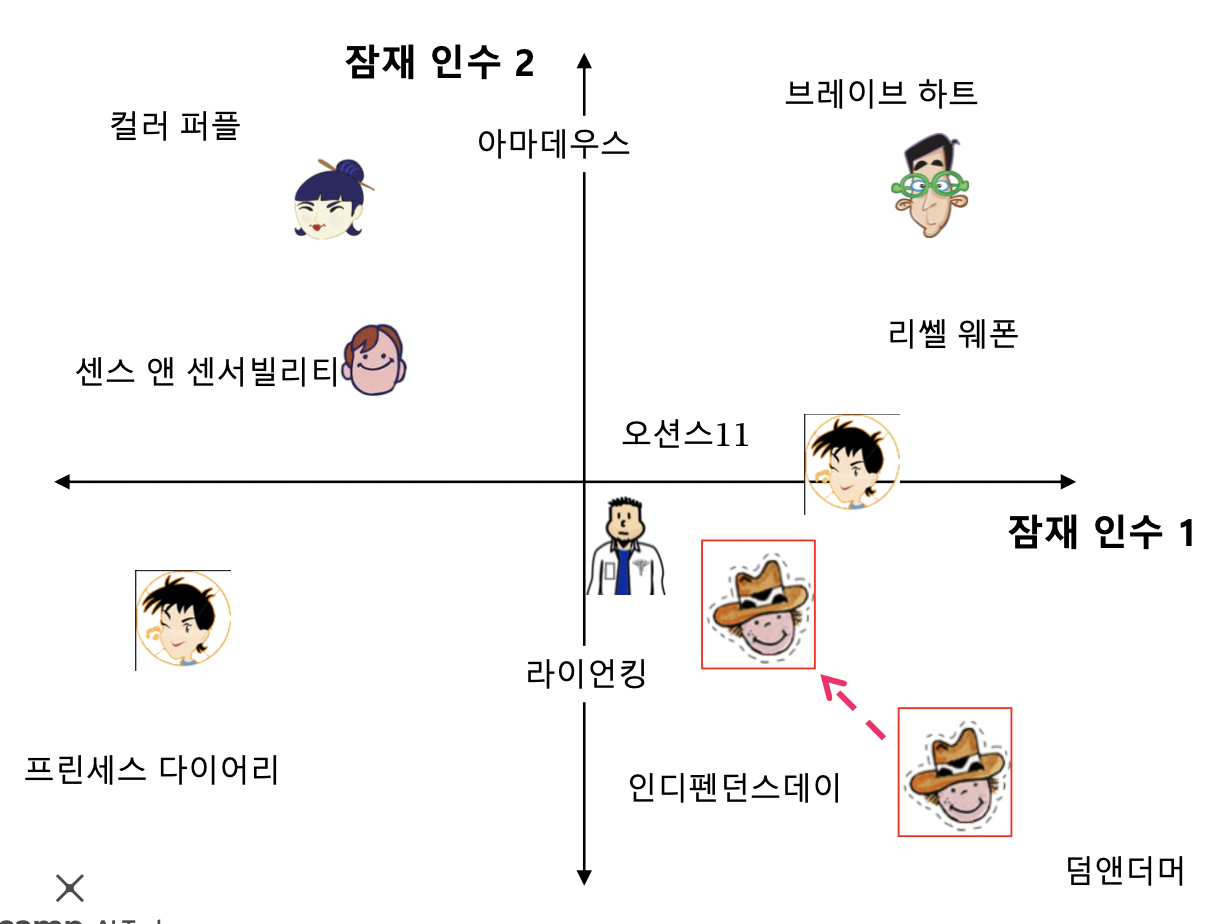
- 위 사진과 같이 정규화는 너무 큰 임베딩을 방지
최적화
- 손실함수를 최소화하는 P, Q 를 찾기 위해 (확률적) 경사하강법, SGD 사용
- 경사하강법은 손실함수를 안정적으로 변화시키지만 느리고 로컬 미니멈에 빠질 수 있음
- SGD 는 불안정하게 변화시키지만 빠르게 감소시키고 미니멈에서 나올 가능성을 높여줌 (덜 신중하게 걸음을 해서 빠르게 이동)
결과
- 기본 잠재 인수 모형 사용 MSE : 0.9
고급 잠재 인수 모형
사용자와 상품의 편향을 고려한 잠재 인수 모형
- 사용자의 편향은 해당 사용자의 평점 평균과 전체 평점 평균의 차
- A 의 평점 평균 4.0, B 의 평점 평균 3.5, 모든 사람의 평점 평균 3.7 이면 A 의 사용자 편향은 4-3.7 = 0.3, B 의 사용자 편향은 3.5-3.7 = -0.2
- 상품의 편향은 해당 상품에 대한 평점 평균과 전체 평점 평균의 차
- 영화 a 의 평점 평균 4.5, b 의 평점 평균 3.0, 전체 영화 평점 평균 3.7 → a 상품 편향 : 0.8, b 상품 편향 : -0.7
- 개선된 잠재 인수 모형은 전체 평균, 사용자 편향, 상품 편향, 상호작용으로 분리

- 예전에는 상호작용만 고려한 것에 비해 개선됨
- 손실 함수
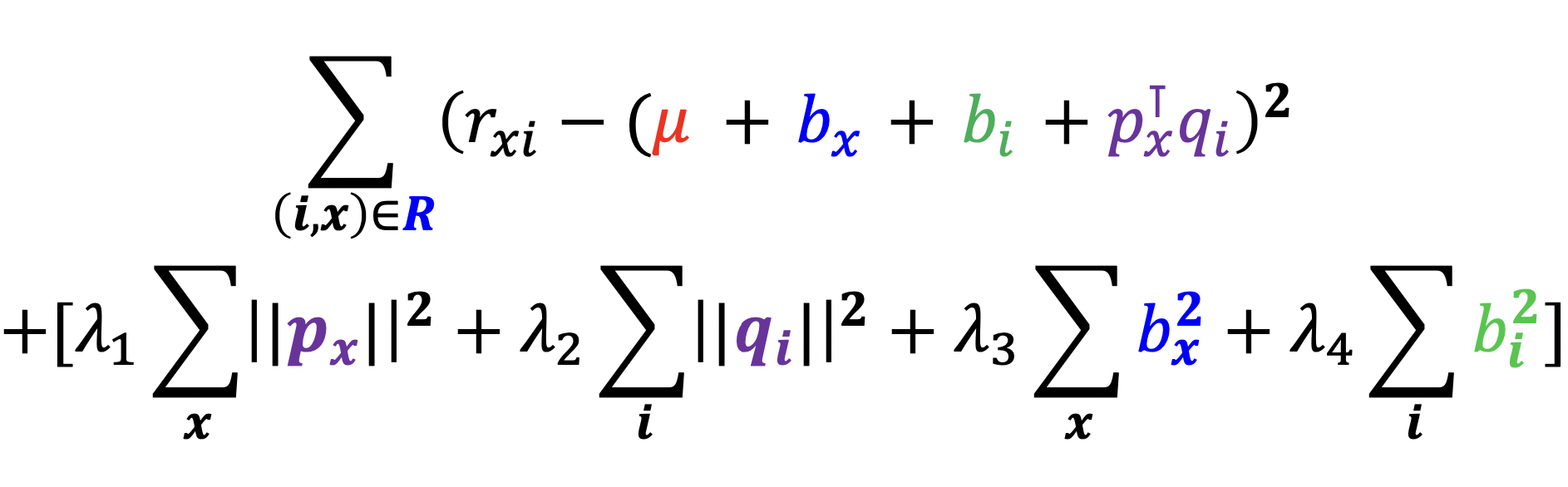
- 결과
- 사용자와 상품의 편향을 고려한 잠재 인수 모형 MSE : 0.89
시간에 따른 편향을 고려한 잠재 인수 모형
- 넷플릭스 시스템 (UI 등) 의 변화로 그 이후 평점이 크게 상승하는 사건이 있었음 (전체 영화)
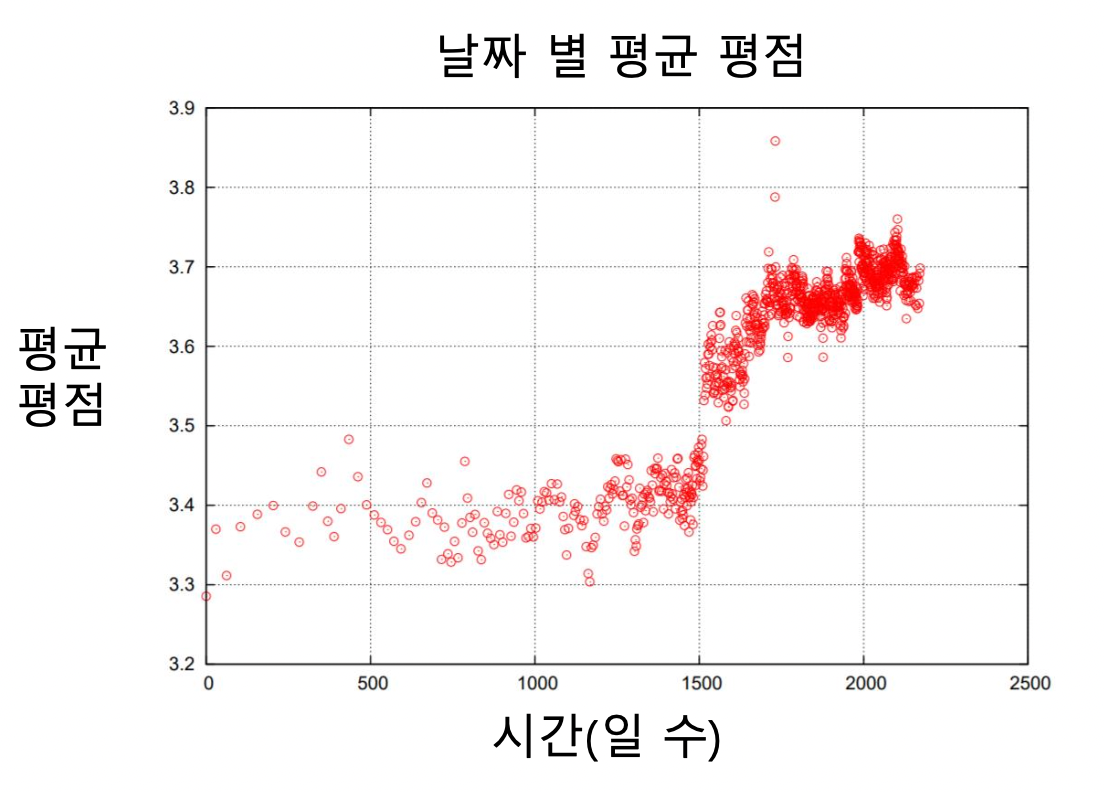
- 영화의 평점은 출시일 이후 시간이 지남에 따라 상승하는 경향이 있음 (각 영화)
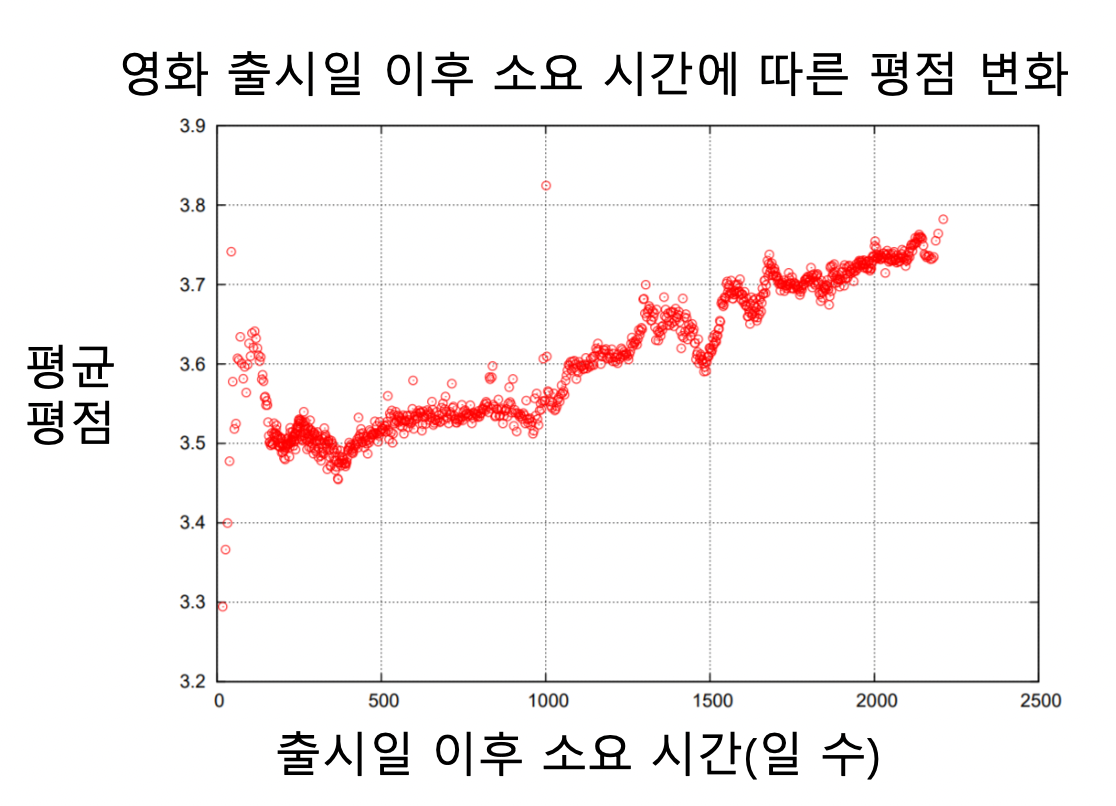
- 처음 높은건 영화를 기다리는 사람들
- 떨어지는건 다른 사람들
- 다시 올라가는건 추천받거나 찾아서 본 사람들
- 시간적 편향을 고려한 잠재 인수 모형

- 사용자 편향과 상품 편향을 시간에 따른 함수로 가정
- 결과
- 시간에 따른 편향을 고려한 잠재 인수 모형 MSE : 0.876
넷플릭스 챌린지 결과
앙상블 학습
- 개선된 잠재 인수 모형으로 거의 목표 오차 다와감
- BelKor 팀이 앙상블을 사용해서 목표 오차 달성
- 다른 팀들이 연합해서 앙상블하여 목표 오차 달성
- 두 팀 오차 정확히 일치 (먼저 20분 먼저 도달한 BelKor 팀 우승)
Further Reading
- http://infolab.stanford.edu/~ullman/mmds/ch9.pdf
- https://datajobs.com/data-science-repo/Recommender-Systems-[Netflix].pdf
참조
BoostCamp AI Tech

데이터로 문제를 해결하는 엔지니어를 꿈꿉니다.