Seeing the world in 3D perspective
3D 를 왜 배워야 할까?
우리는 3D 세상에 살고 있다.
앞으로 나타날 AI 로봇이나 자율주행 등도 3D 세상에 기반하기 때문에 3D 공간에 대한 이해를 해야한다.
우리가 3D 를 보는 방법
사진은 카메라를 통해 3D 세상의 것을 2D 공간에 projection 시킨 것이다.
3D 와 2D 는 직진 관계를 띄기 때문에 2D 이미지로부터 3D 를 구할 수 있다.
Triangulation
2D 이미지로 3D 를 구하는 방법이다.

3D 표현법
2D 이미지는 2차원 행렬을 3 (RGB) 만큼의 뎁스로 표현한다.
3D 이미지 표현법은 여러 방법이 있다.

3D Datasets
실내
ShapeNet
55 개 카테고리, 51,300 개의 3D 모델로 구성된 데이터셋으로 퀄리티가 좋고 3D 에서는 큰 사이즈이다.
PartNet
26,671 개의 3D 모델을 573,585 개의 part instance 로 구성한 데이터셋으로 segmentation 에 좋은 데이터셋이다. ShapeNet 을 개선하였다.
SceneNet
5백만개의 RGB-Depth 페어가 된 실내 사진들에 대한 데이터셋이다.
ScanNet
1500개의 스캔 데이터로부터 RGB-Depth 페어된 250만 개의 뷰 데이터셋이다.
실외 (주로 자율주행용)
모두 LiDAR 데이터가 기본적인 정보를 이루고 있다.
KITTI
Semantic KITTI
Waymo Open Dataset
3D tasks
3D Recognition
고양이의 3D 이미지를 보고 고양이라는 것을 판별하는 Recognition 태스크,
고양이라는 객체를 바운딩 박스로 탐지해주는 Detection 태스크,
이외 다양한 태스크들이 있다.
3D Semantic Segmentation
3D 이미지를 보고 각 부분이 무엇인지 판별하는 태스크가 있다.
Conditional 3D Generation
2D 에서의 Mask R-CNN 과 비슷하게 Mask 대신 Mesh 로 구현하였다.
3D 이미지에서 객체를 다른 모양으로 바꿔주는 태스크가 가능하다.
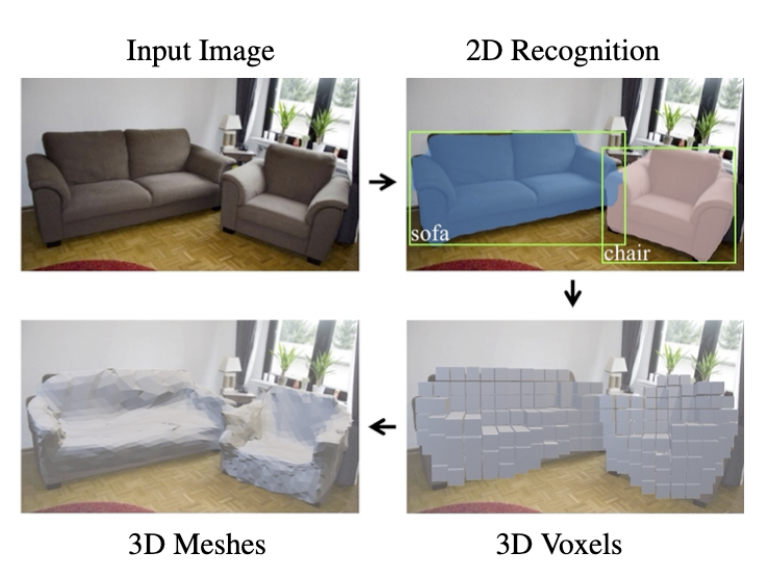
3D 활용 예시
Photo Refocusing
많은 스마트폰에서 제공하는 아웃포커싱 기능에도 3D 모델이 구현되어 있다.

depth map 을 이용하여 사진을 defocusing 하기
-
depth threshold [Dmin, Dmax] 를 설정하여 어느 부분에 focusing 할지 기준을 정한다.

-
focusing area 와 defocusing area 를 depth threshold 를 통해 계산한다.
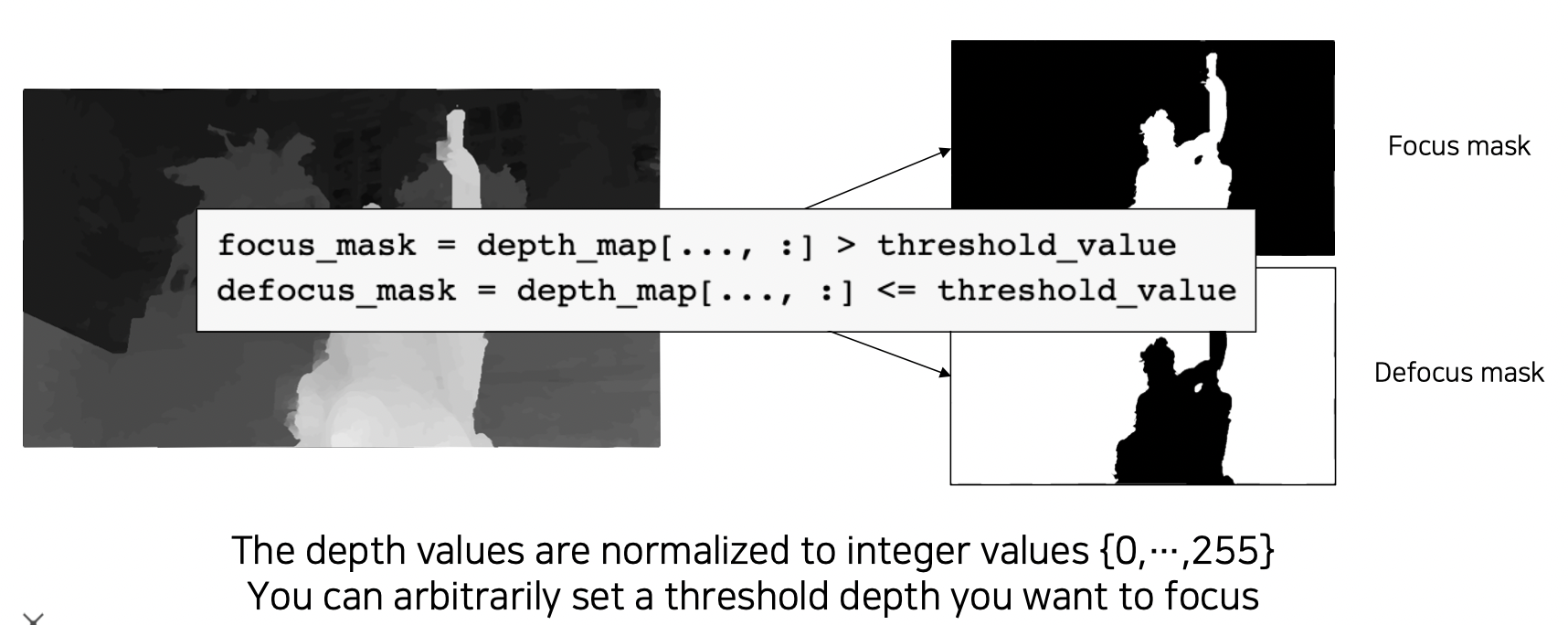
-
blur 처리된 입력 이미지를 생성한다.

-
Masked focused image 와 Demasked focused image 를 계산한다.

-
refocused 된 이미지를 생성하기 위해 masked된 이미지를 섞는다.

Further Reading
- Mesh R-CNN : https://arxiv.org/pdf/1409.1556.pdf
참조
BoostCamp AI Tech
