Ustage Week7 - Computer Vision
1.컴퓨터 비전 개요
.jpeg)
컴퓨터로 영상 데이터 (이미지, 비디오) 를 입력으로 받아 시각적 인식과 판단을 하는 것
2021년 3월 8일
2.이미지 분류 (1)
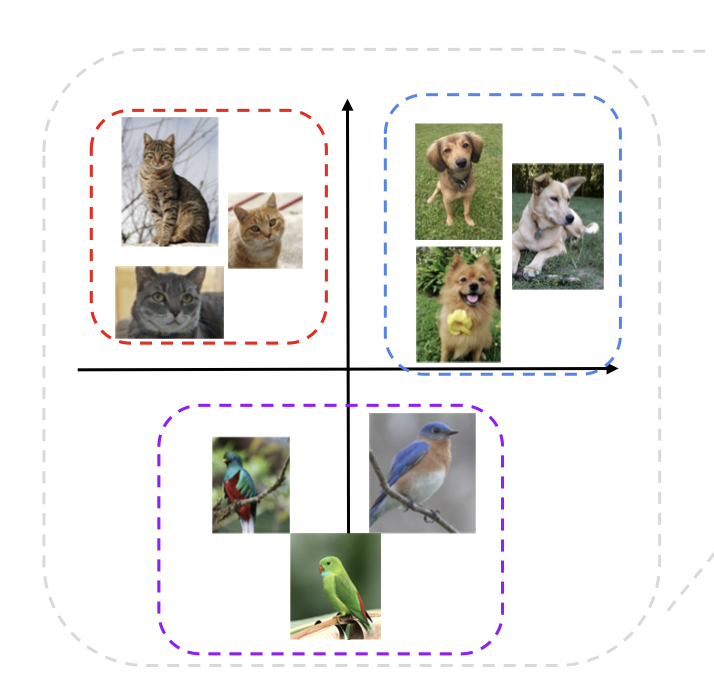
이미지를 보고 어떤 물체인지 분류하는 태스크
2021년 3월 8일
3.Data Augmentation
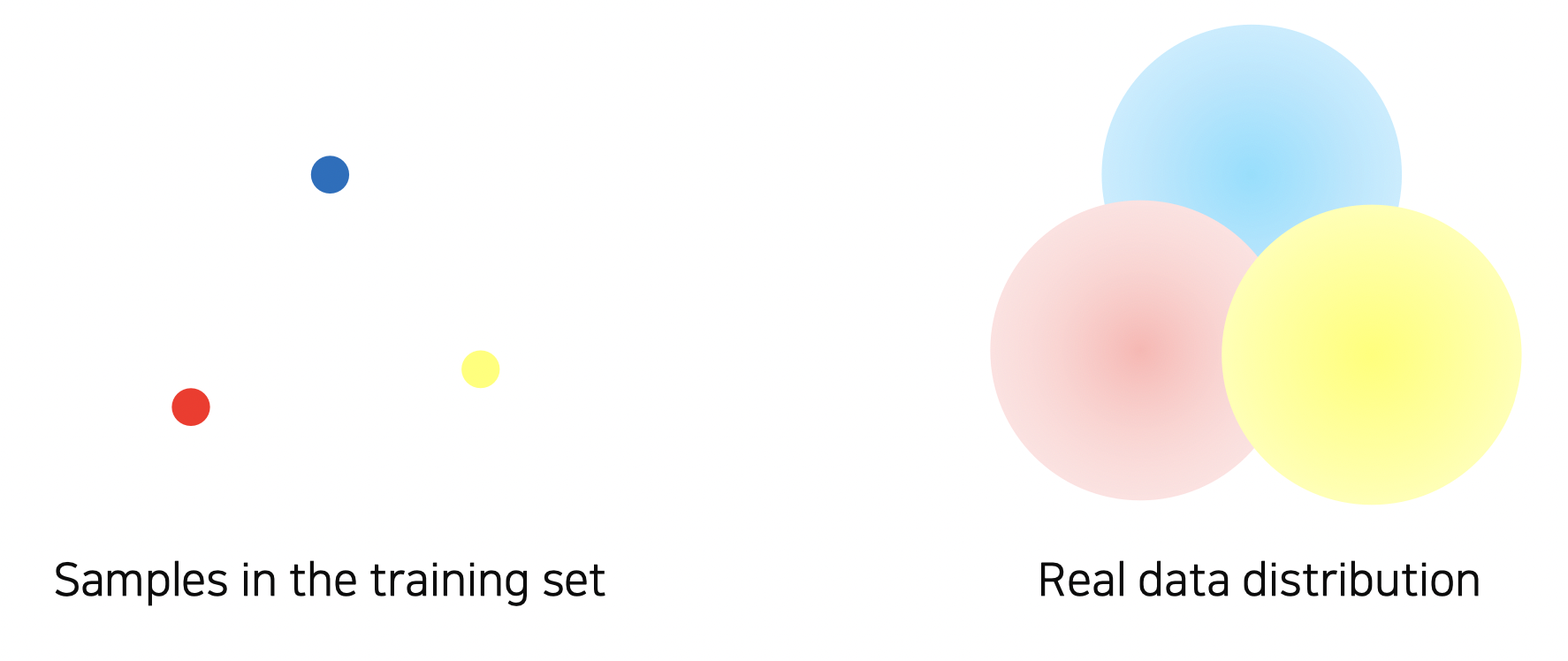
학습 데이터는 실제 데이터를 제대로 반영하지 못하는 문제를 해결하기 위해 데이터를 증강시킨다.
2021년 3월 8일
4.Leveraging Pre-trained Information
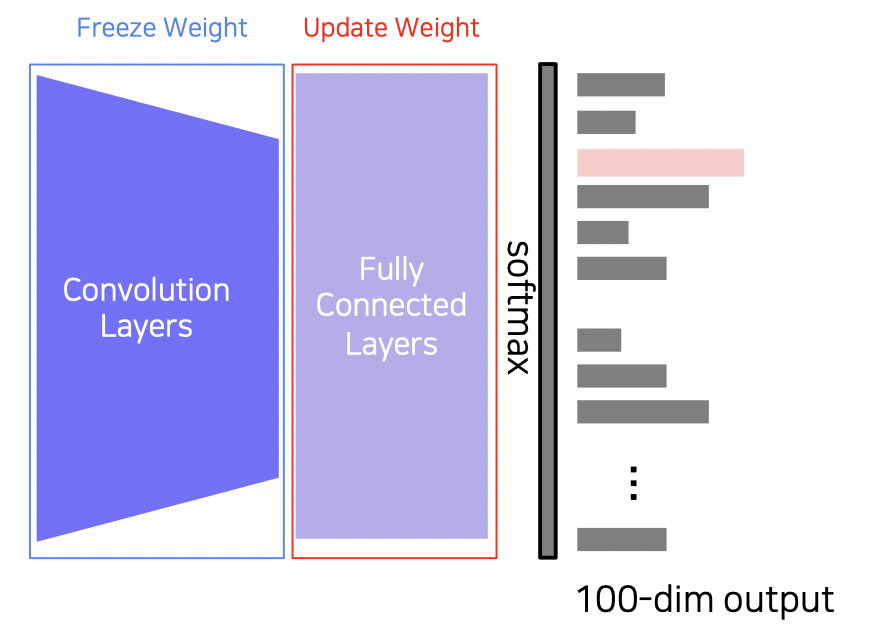
적은 데이터로 태스크를 수행하는 방법
2021년 3월 8일
5.이미지 분류 (2)
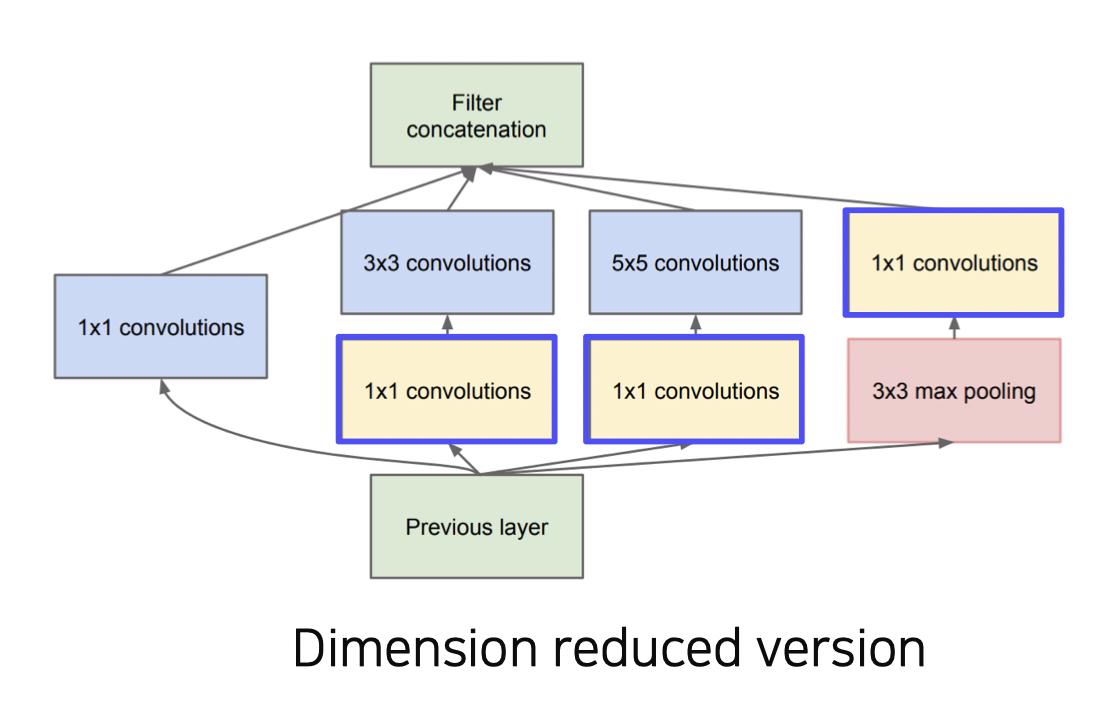
AlexNet 에서 VGGNet 을 거치면서 더 깊은 레이어를 가질 수록 성능이 좋아진다는 것을 확인하였다.그런데 어느 정도 이상 깊어지면 더 성능이 낮아지는 문제가 발생했다.
2021년 3월 9일
6.Semantic Segmentation
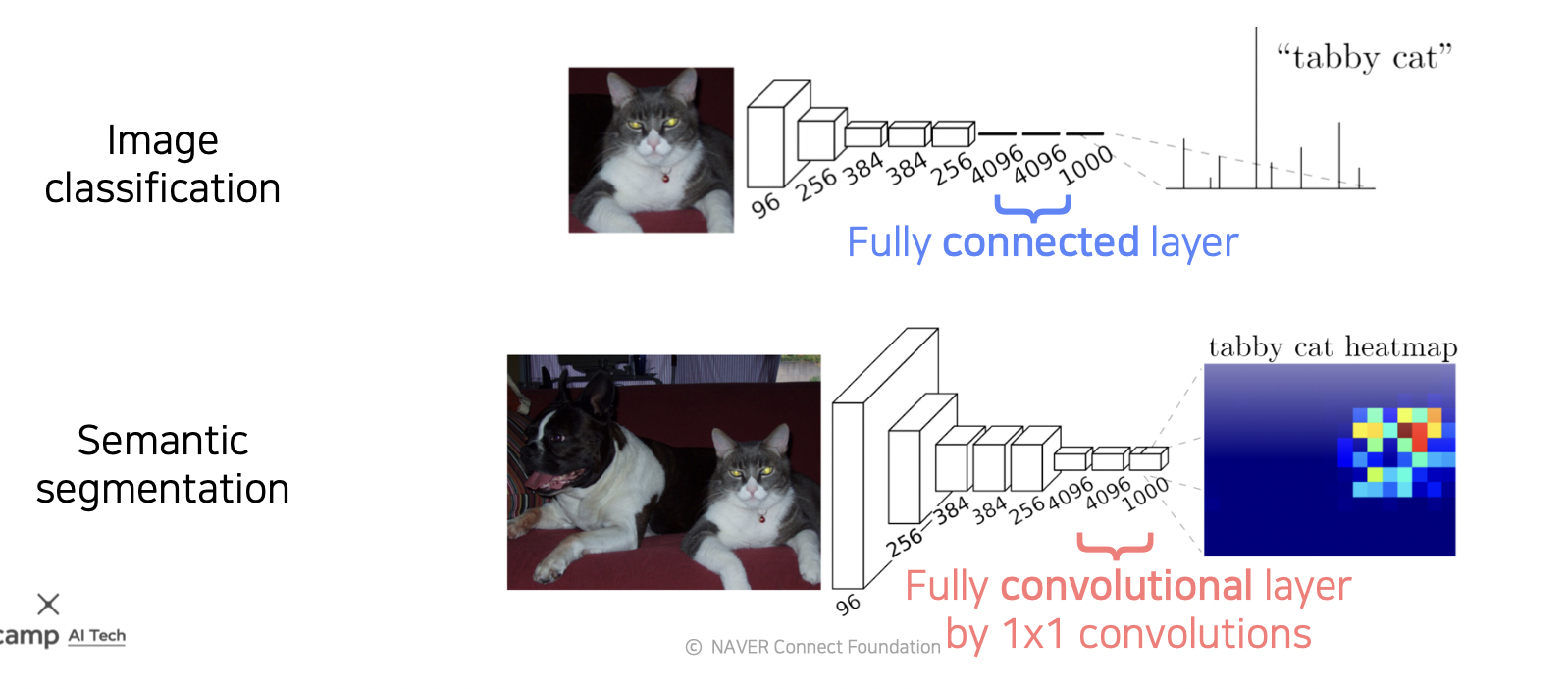
영상 단위로 분류하는 것이 아닌 영상의 픽셀 단위로 물체를 구분하는 태스크
2021년 3월 9일
7.Object Detection
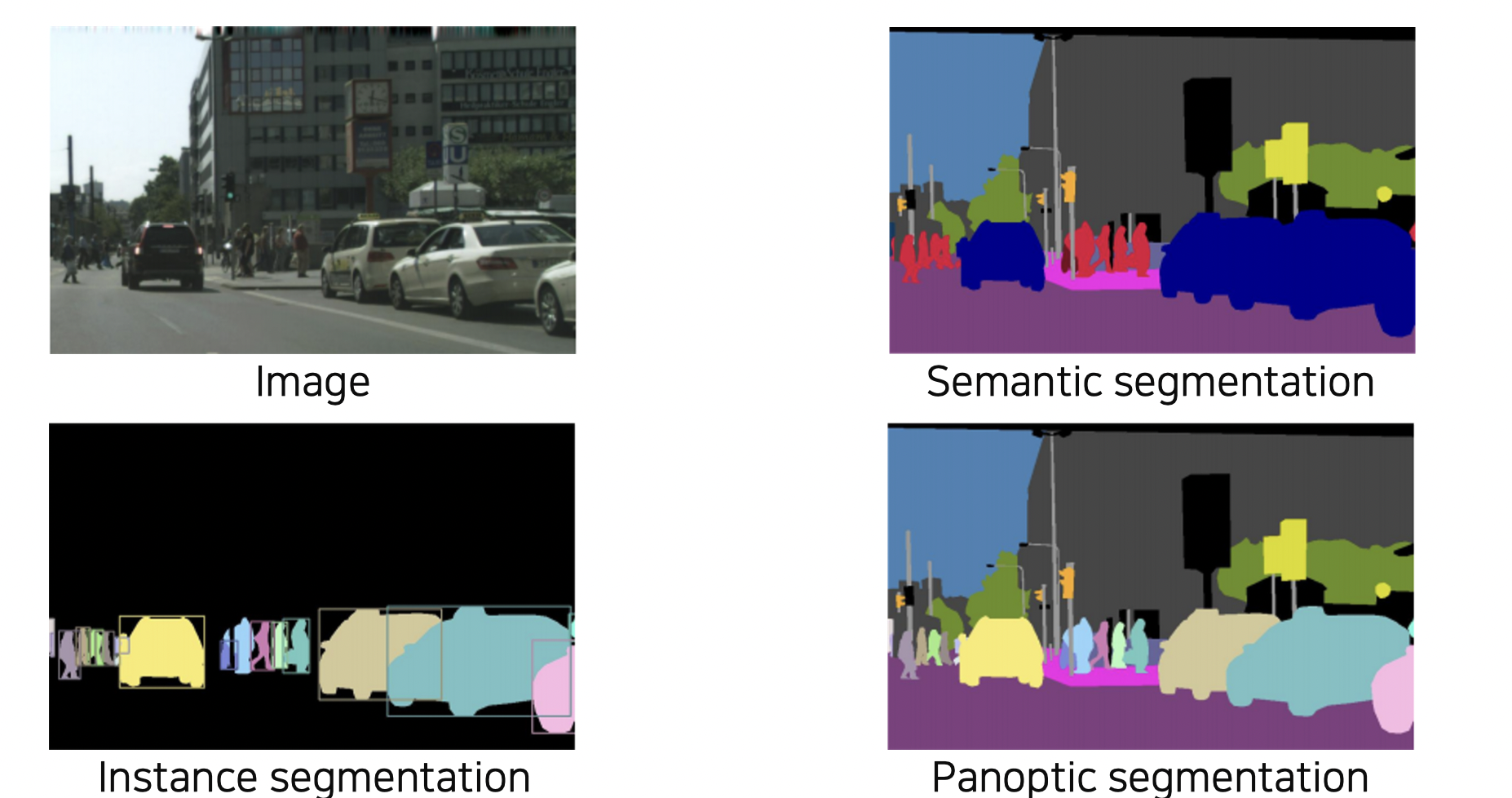
Instance segmentation 과 Panoptic segmentation 을 하기 위해 Object Detection 이 필요하다.
2021년 3월 10일
8.CNN 시각화
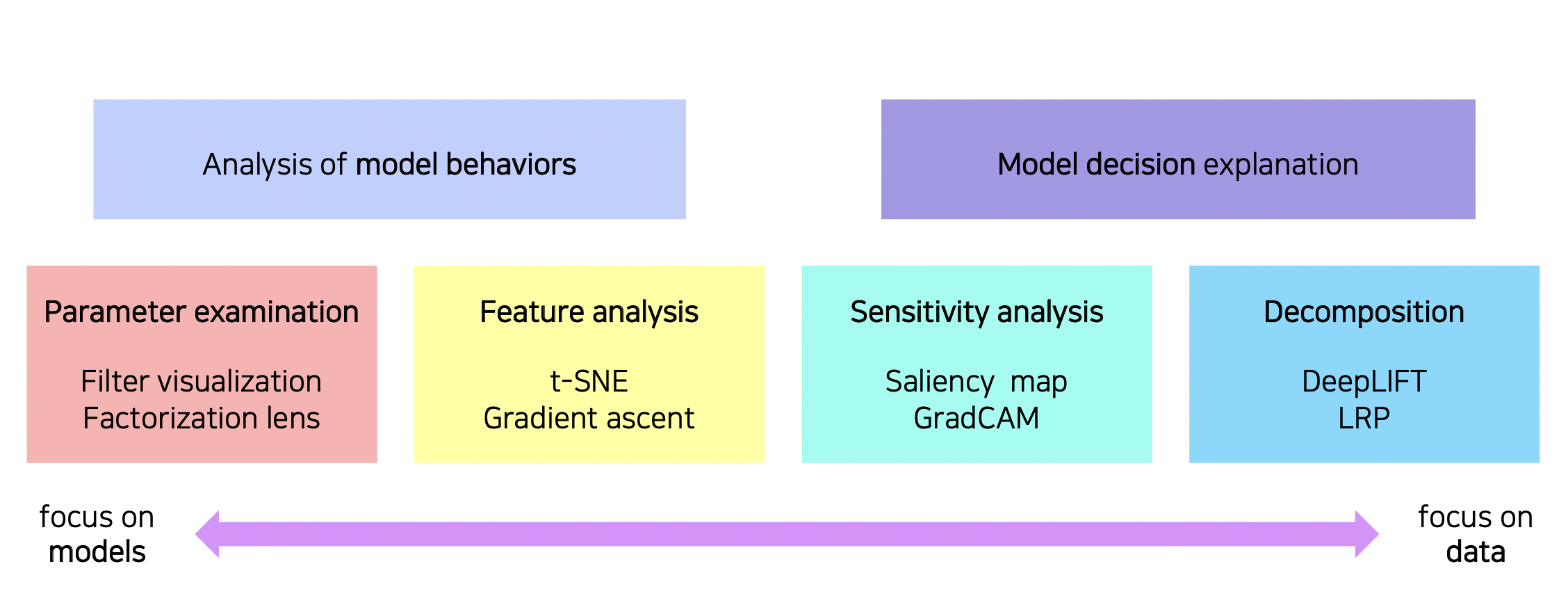
CNN 에 입력 데이터를 넣으면 현재 어떻게 수행되는지 파악할 수 있도록 시각화를 한다.
2021년 3월 10일
9.Instance/Panoptic Segmentation
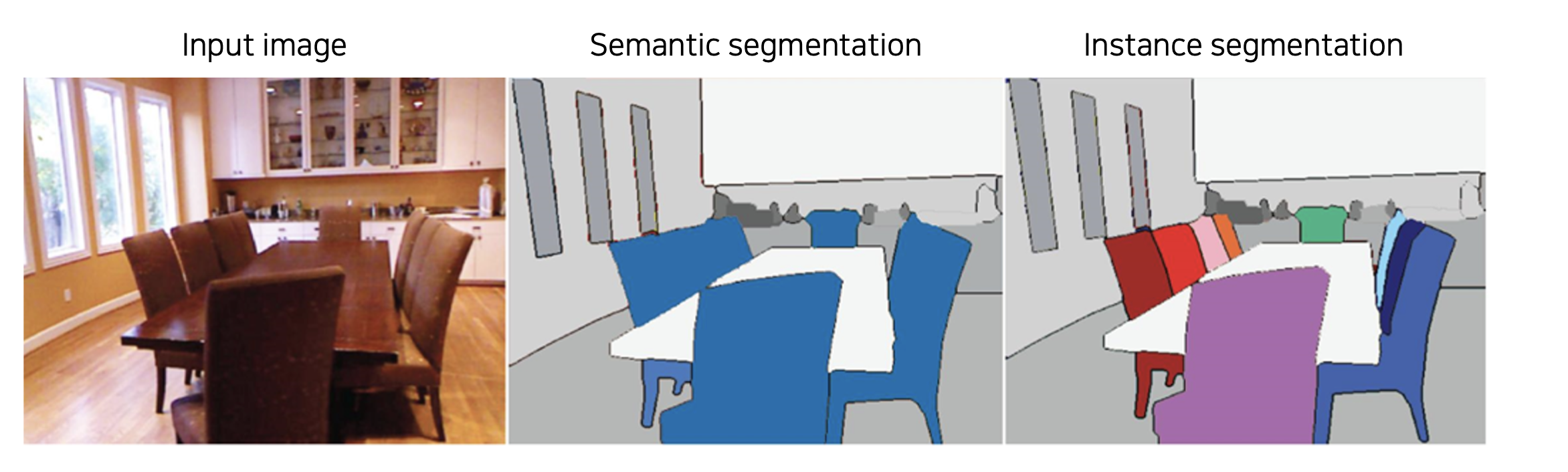
이미지에서 객체를 구분하는 수준까지 가보자.
2021년 3월 11일
10.Conditional Generative Model
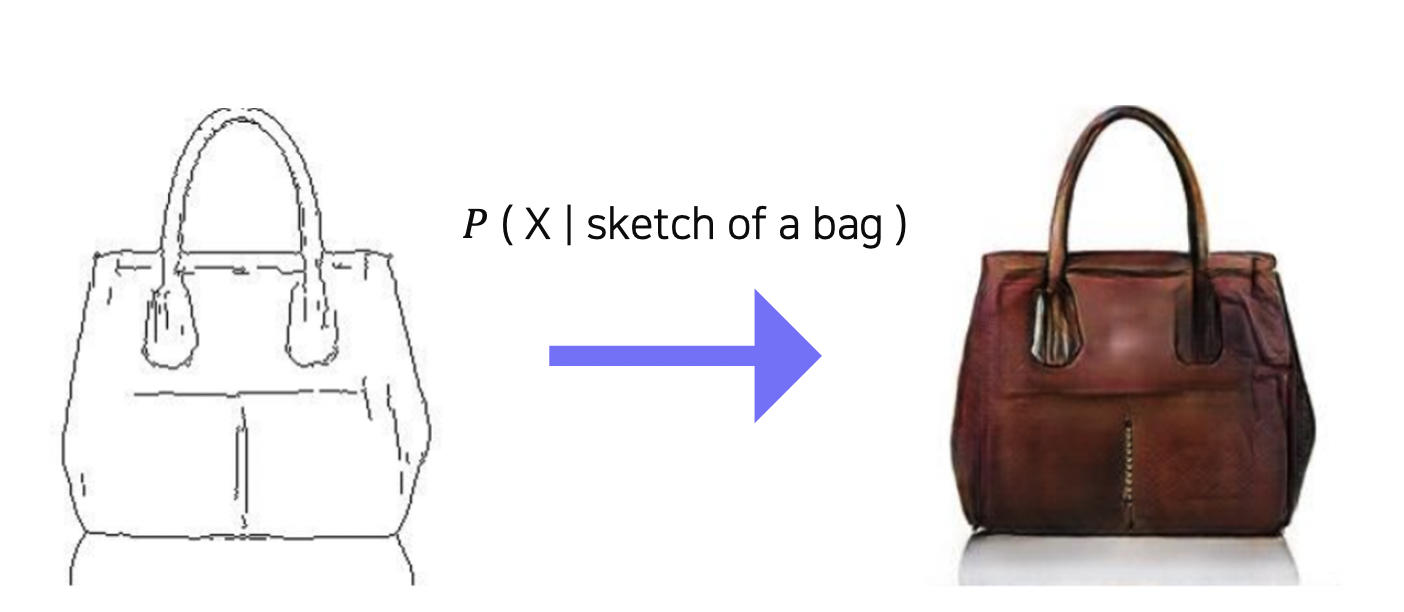
그림으로 그린 가방을 실제 가방으로 생성해준다면?
2021년 3월 11일
11.Multi-modal : Captioning and Speaking
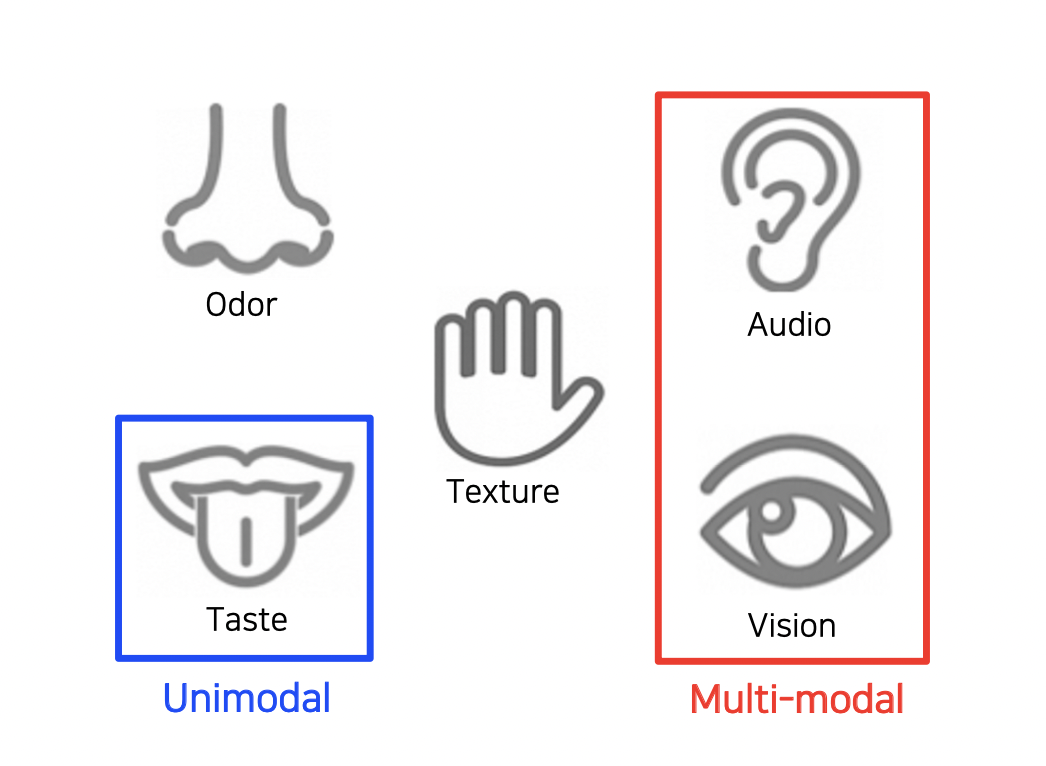
사람은 시각 정보 뿐만 아니라 Audio 나 Text 데이터 등을 함께 사용하여 인식을 한다.이렇듯 여러 종류의 데이터를 사용하는 것을 Multi-modal 이라고 한다.
2021년 3월 12일
12.3D Understanding

우리는 3D 세상에 살고 있다. 앞으로 나타날 AI 로봇이나 자율주행 등도 3D 세상에 기반하기 때문에 3D 공간에 대한 이해를 해야한다.
2021년 3월 12일