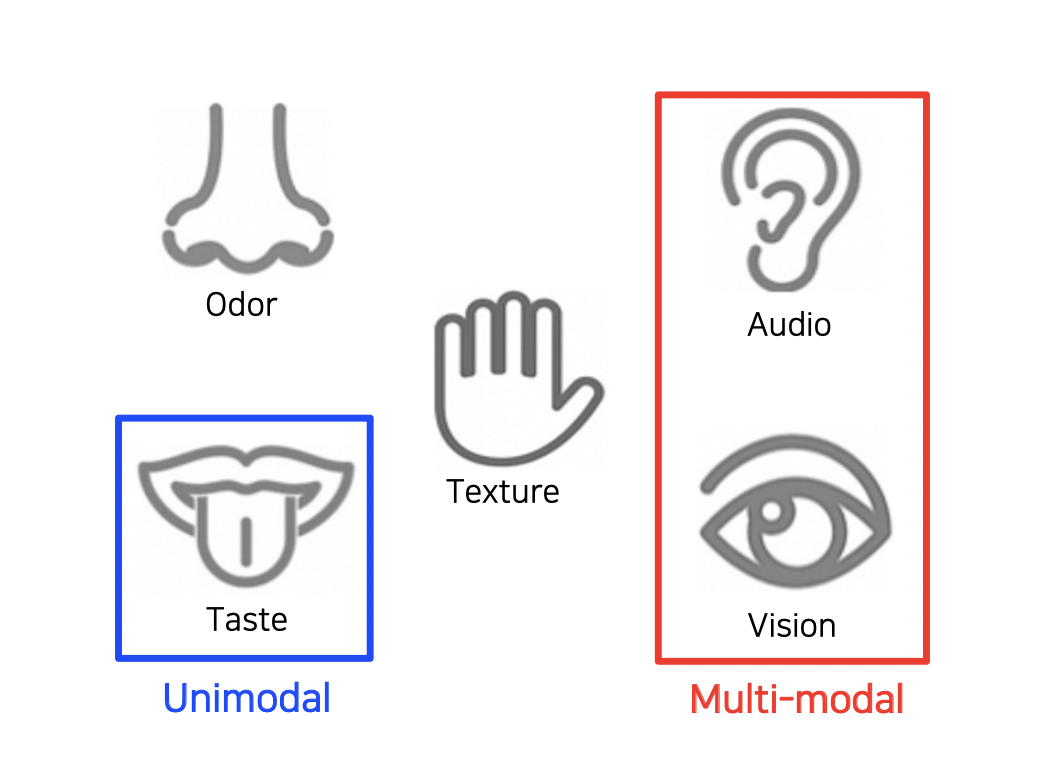
Multi-modal Learning 개요
사람은 시각 정보 뿐만 아니라 Audio 나 Text 데이터 등을 함께 사용하여 인식을 한다.
이렇듯 여러 종류의 데이터를 함께 사용하는 것을 Multi-modal learning 이라고 한다.
어려운 점
표현 방법
다른 종류의 데이터들은 표현하는 방법이 다르다.
데이터의 양
한 쪽 데이터가 너무 없는 등 다른 종류의 데이터들의 양이 맞지 않을 수 있다.
치우침
모든 데이터를 골고루 보지 않고 한 종류의 데이터만 치우쳐서 학습할 수 있다.
여러 방법
이러한 어려움들이 있지만 멀티 모달 러닝을 통해 기존에 해결하지 못한 문제를 해결할 수도 있다.
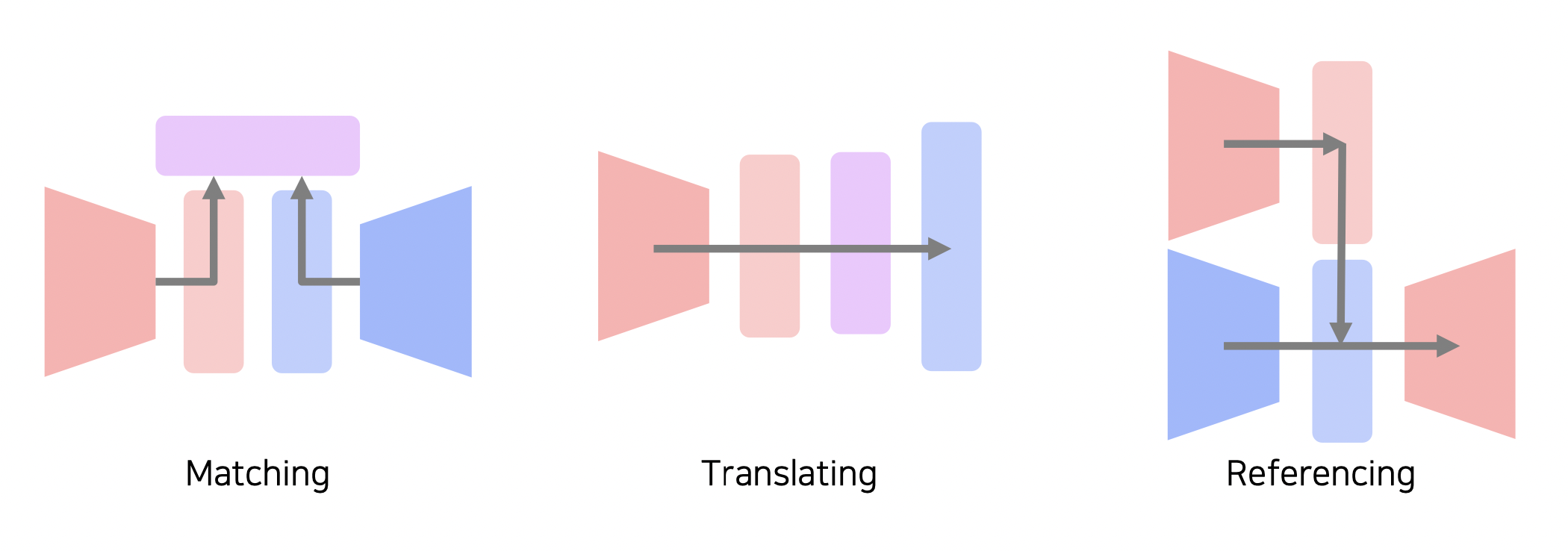
Matching
다른 종류의 데이터를 매칭하여 학습시킨다.
Translating
한 종류에서 다른 종류로 이해할 수 있도록 변환하여 학습시킨다.
Referencing
한 종류의 데이터를 참고하여 다른 종류의 데이터를 학습시킨다.
Multi-modal (1) - Visual Data & Text
Text Embedding
Text 데이터를 표현할 때 글자 단위로 임베딩하는 것은 학습에 있어 쉽지 않다.
일반적으로 단어 단위로 임베딩을 하고 다른 단어와의 관계를 알 수 있도록 만들어준다.
이전 포스트 참고
Word Embedding
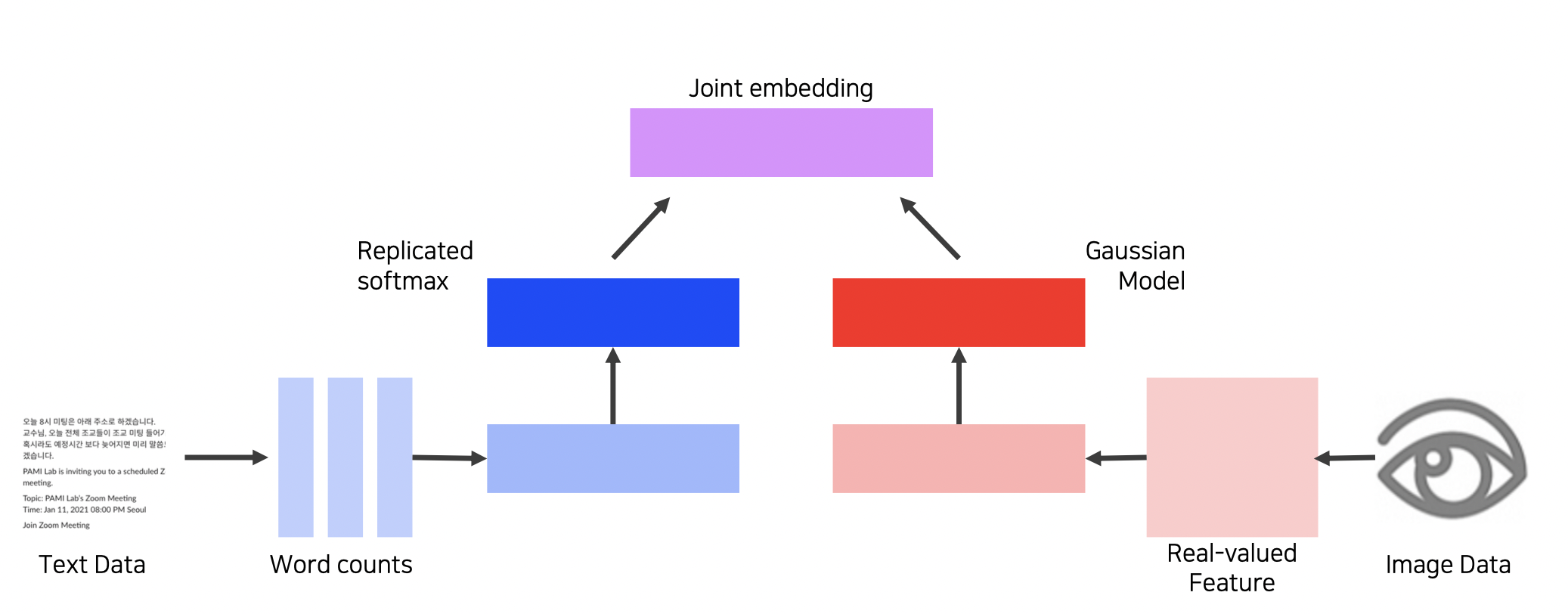
Joint Embedding (Matching)
다른 종류의 데이터에 대한 공통된 임베딩 방법이다.
Image Tagging
사진을 보고 어떤 단어와 가장 잘 어울리는지 판단하는 태스크에도 응용될 수 있다.
기학습된 단일 종류 데이터 임베딩들을 합쳐주는 방법이다.
Word2vec + CNN 등 가능
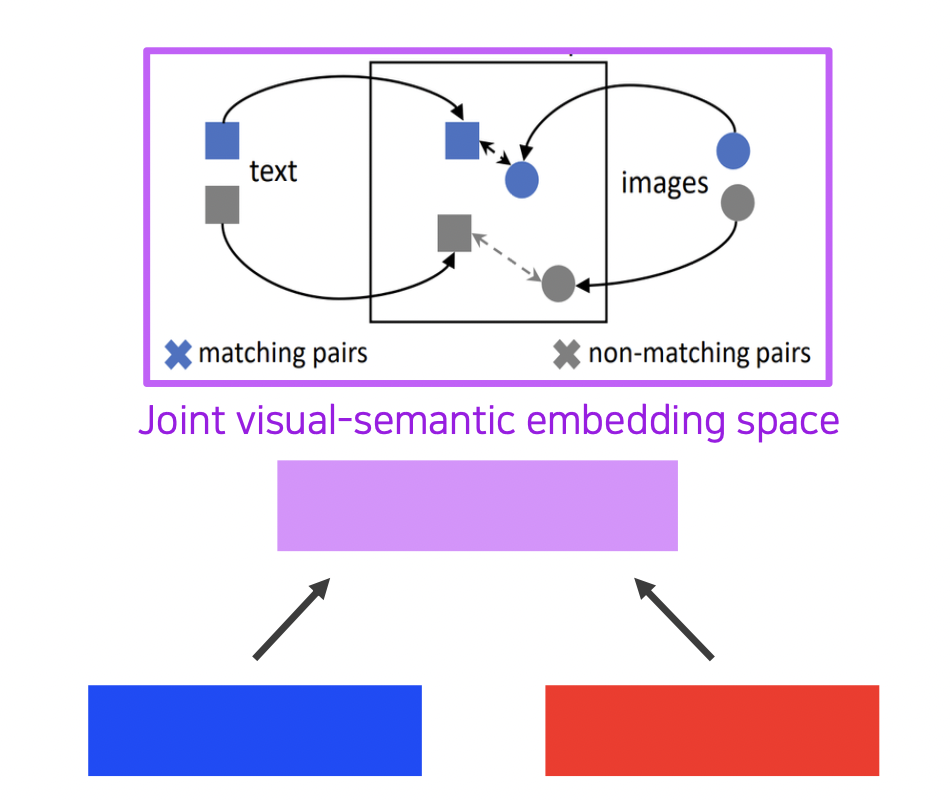
각 임베딩의 차원을 똑같이 맞추고 Metric learning 을 통해 두 임베딩이 가깝도록 joint embedding 스페이스를 학습시킨다.
Metric learning
매칭 되는 짝끼리는 가까워지고 아닌 경우에는 멀어진다.
신기하게도 강아지 사진 벡터에서 dog 라는 텍스트 벡터를 빼고 cat 이라는 텍스트 벡터를 더하면 고양이 사진이 나온다.

응용
음식 사진을 보고 레시피에 들어가는 단어들을 뽑아내거나,
재료 단어들만 보고 음식 사진을 나타낼 수도 있다.

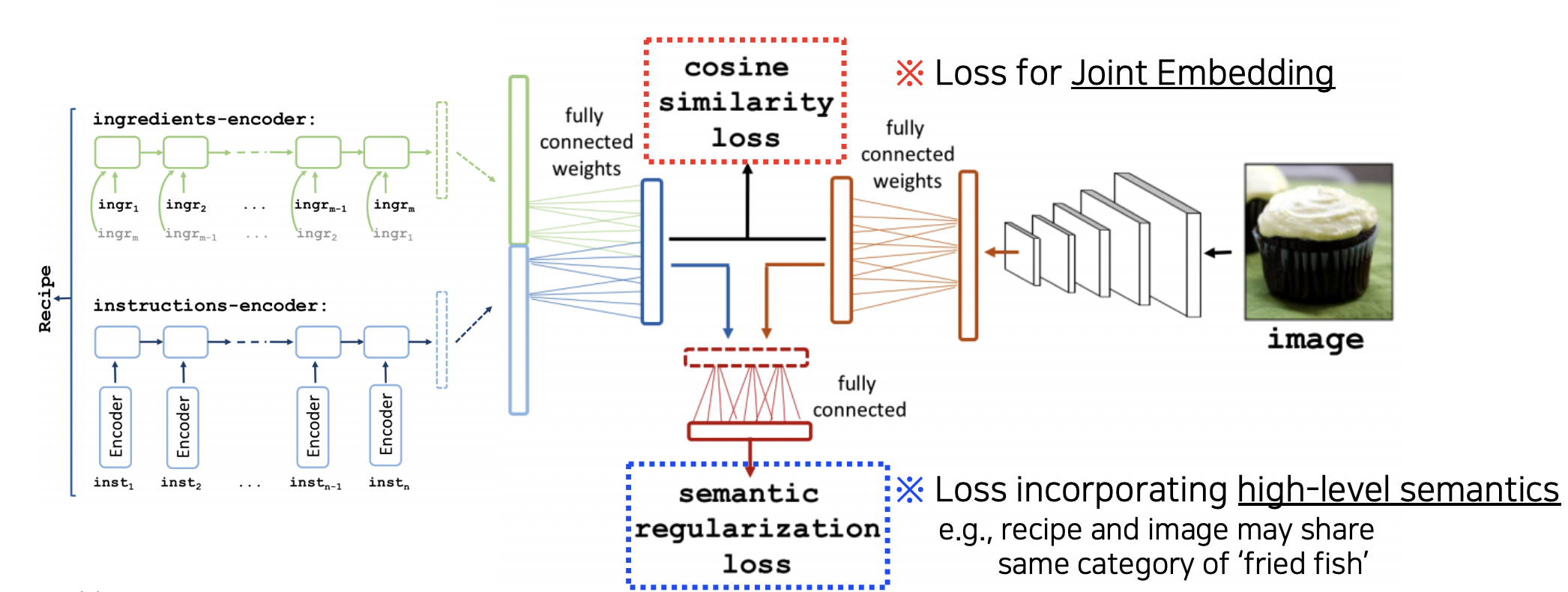
Cross Modal Translation (Translating)
비주얼 데이터와 텍스트 데이터 사이에 변환을 하는 예시로는
Image Captioning (사진을 보고 상황을 설명하는 태스크) 이 있다.

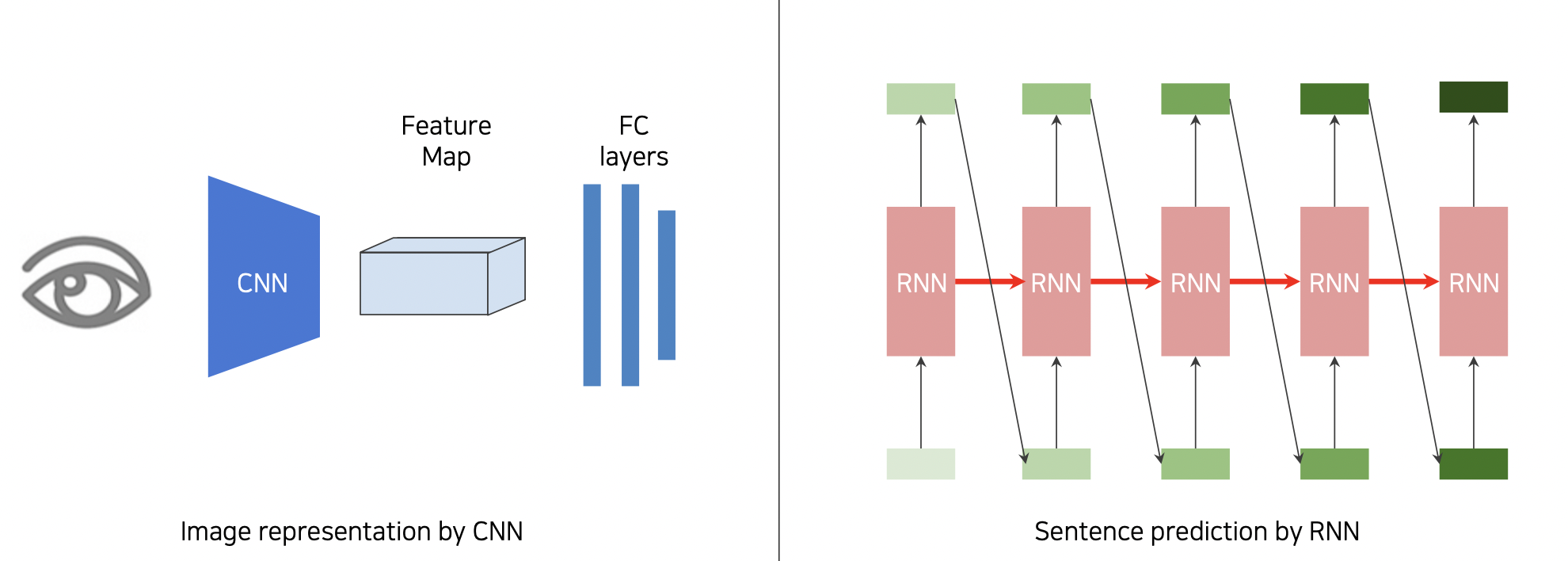
Image to sentence
CNN for image & RNN for sentence 를 사용한다.
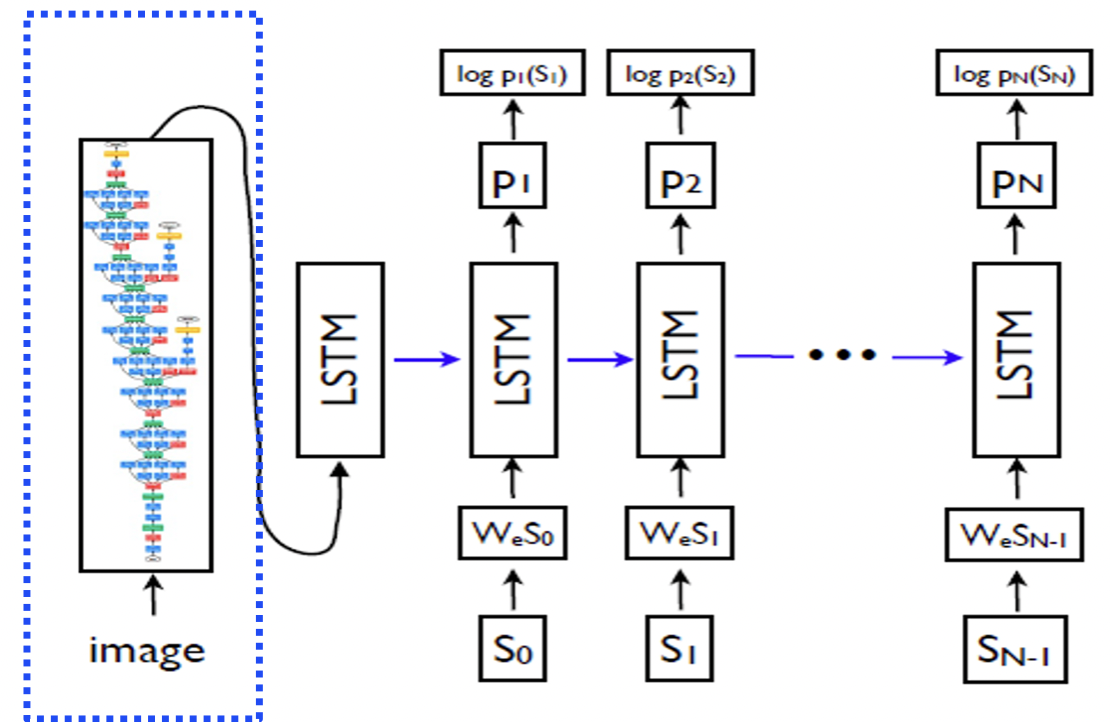
Show and tell 방법
인코더로 기학습된 CNN 모델을 사용하고 디코더로 LSTM RNN 을 사용한다.
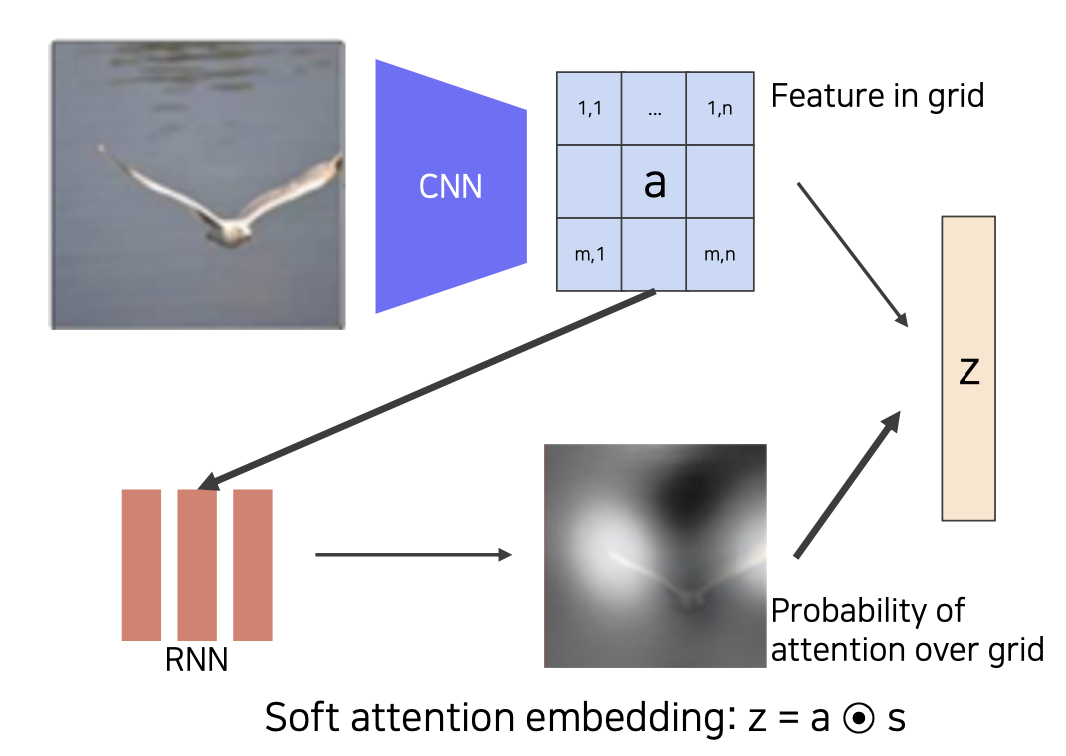
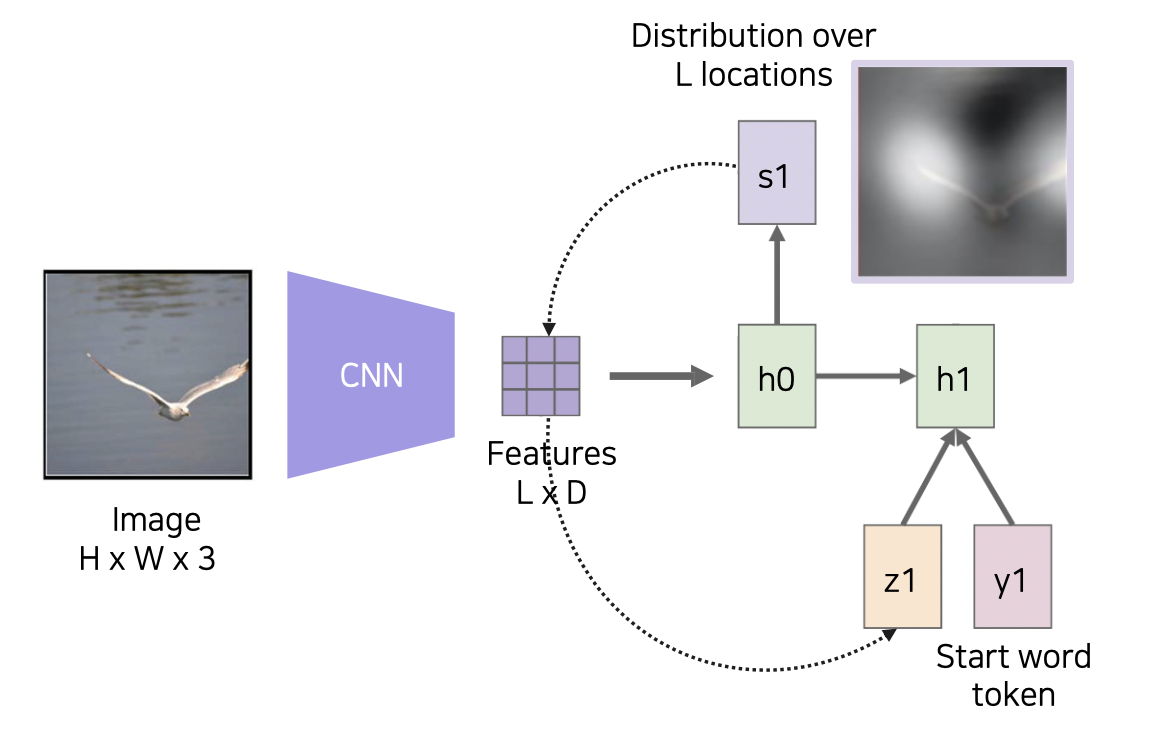
Show, attend, and tell 방법
이미지 내 물체에 대한 단어를 출력할 때 attention 을 통해 이미지에서 실제 그 부분을 보는 방법이다.
이미지를 CNN 에 넣고 14x14 피쳐맵으로 출력하여 위치를 기억한다.
이후 RNN 에 넣어 attention 을 진행하며 단어와 매칭되는 위치를 보게 만든다.
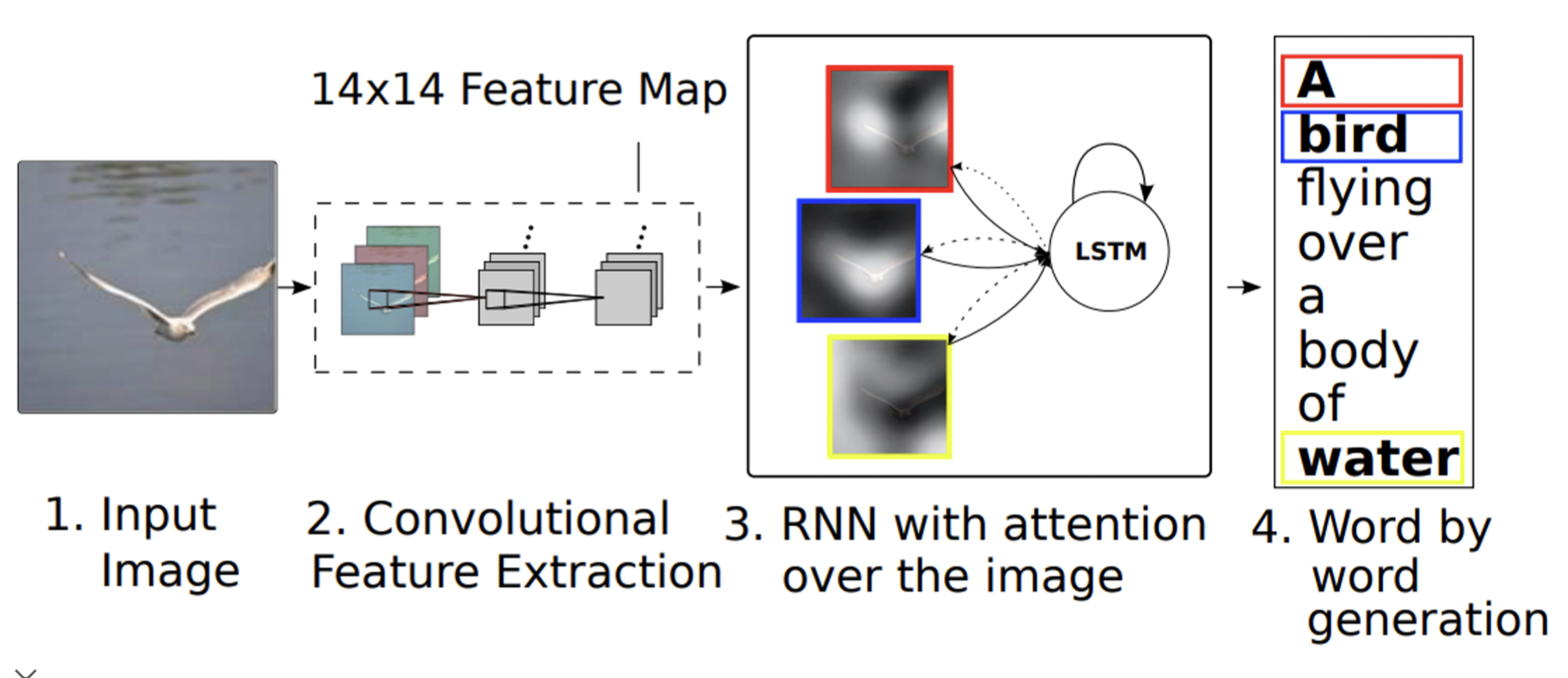
Soft attention
feature map 을 보고 어디 부분을 살펴볼지 확인한다.
해당되는 단어를 출력하고, 다음 해당되는 부분을 살펴보는 작업을 반복한다.
반대로 text-to-image 를 한다면?
Conditional GAN
이미지를 생성해내야 하기 때문에 generator 가 필요하다.
추가적으로 discriminator 도 사용하는데
생성된 이미지로 문장을 만들고 정답 문장과 비교하여 말이 되는지 판단한다.
Cross Modal Reasoning (Referencing)
위에서 본 Show, attend, and tell 도 Cross Modal Reasoning 에 가깝다.
이미지에 대해 질문이 주어졌을 때 답을 도출하는
Visual question answering 태스크에 사용될 수 있다.
Image stream 과 Question stream 을 만들고
join 하여 결과를 출력하고 학습한다.
Multi-modal (2) - Visual Data & Audio
Sound representation
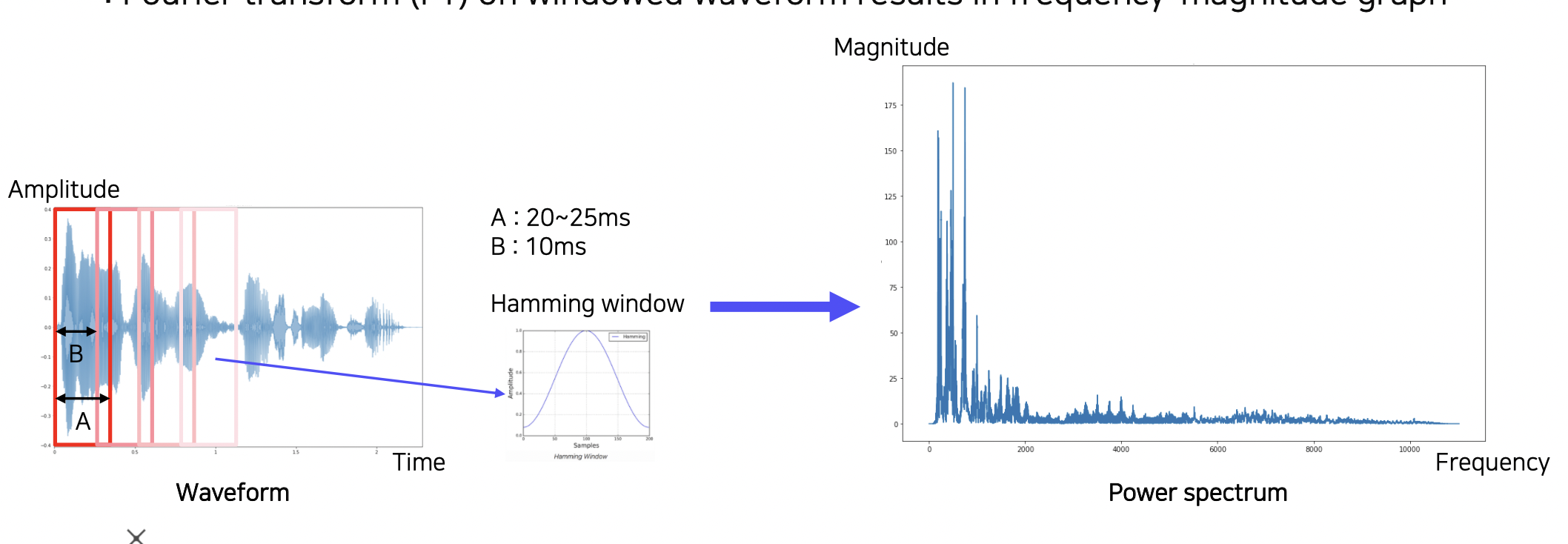
Fourier transform
Short-time Fourier transform (STFT)
짧은 구간에 대해서만 푸리에 변환을 하는 방법이다.
변환된 것에 대해 Hamming window 를 적용하여 가운데 부분만 추출해낸다.
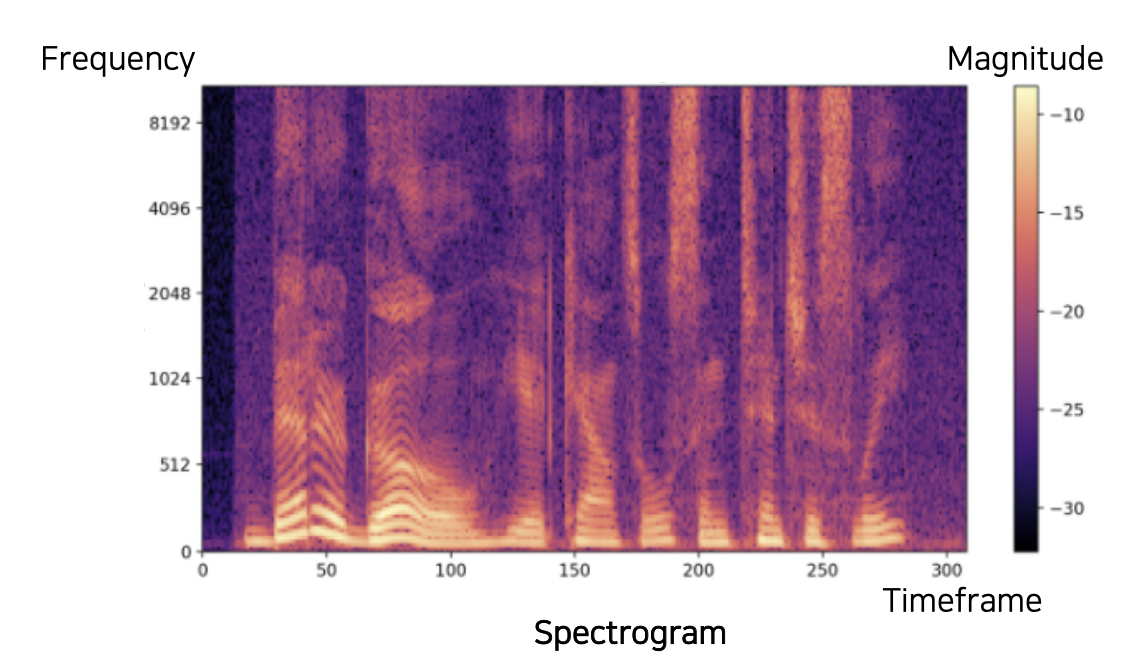
Spectrogram
만들어낸 스펙트럼을 시간에 따라 쌓은 모형이다.
Joint Embedding
소리를 듣고 어떤 장면인지 인식하는 태스크가 있다.
SoundNet
영상으로부터 나온 음성을 Teacher-student 방식으로 학습시킨다.
영상을 음성으로 변환하는 영상 인식 모델에 넣어 음성으로 변환시키고
음성 웨이브폼과 대조하여 학습한다.
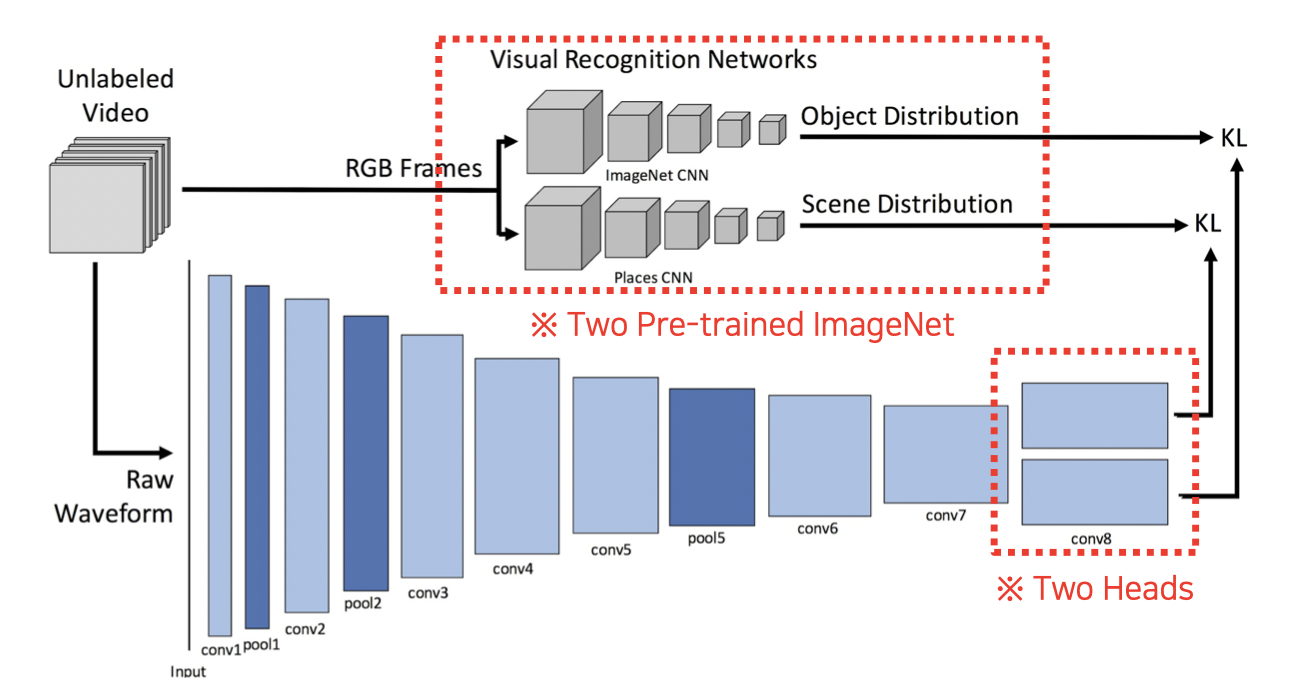
Cross Modal Translation
Speech2Face
음성을 듣고 얼굴을 상상하는 모델이다.
음성을 얼굴로 변환하는 방법을 사용한다.
영상에서 얼굴을 인식하는 부분과
음성을 분석하는 부분을 나누고 이들을 joint 시켜
음성 벡터가 얼굴 벡터를 따라가도록 학습시킨다.
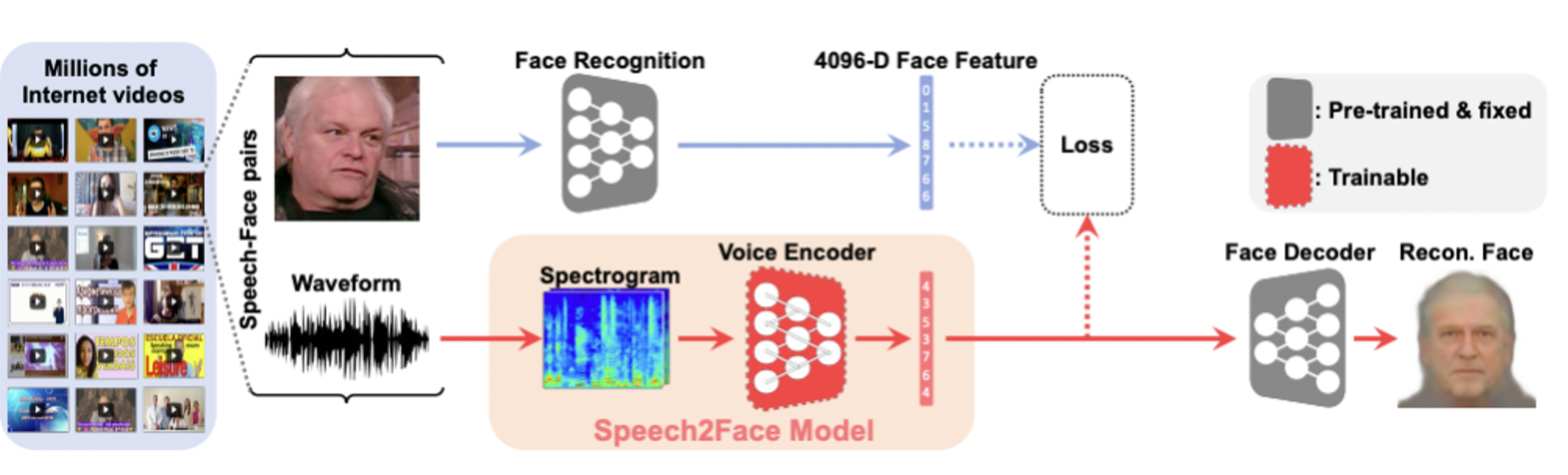
Image-to-speech
사진을 보고 음성으로 설명하는 모델이다.
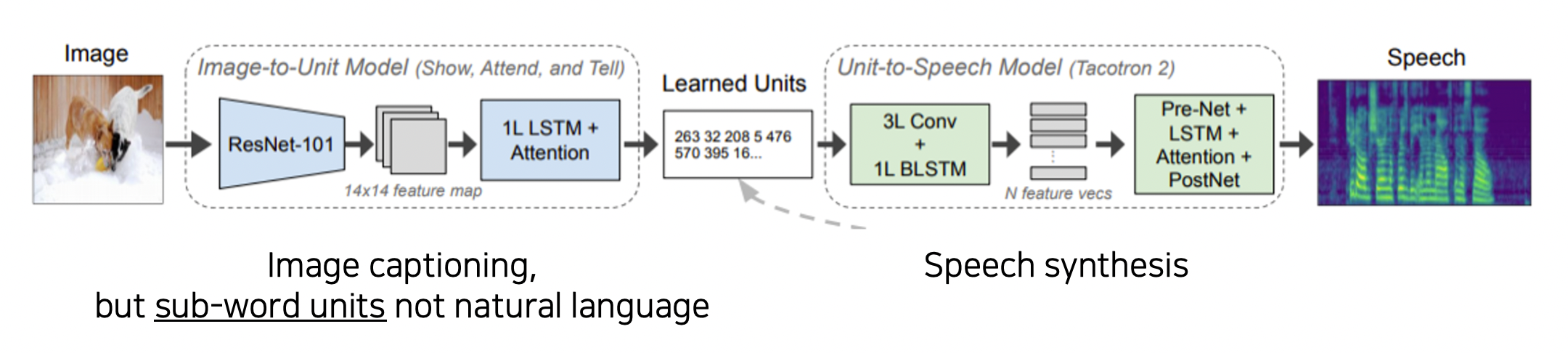
Cross Modal Reasoning
Sound source localization
영상에서 소리가 어느 부분에서 나는지 찾아주는 모델이다.
영상은 Visual net 을 통해 공간을 기억하는 벡터로,
음성은 Audio net 을 통해 벡터로 만들어
서로 어텐션하여 관계를 구한다.
지도 학습, 비지도 학습, semi supervised training 모두 가능하다.
참조
BoostCamp AI Tech
