Transfer Learning
높은 퀄리티의 데이터셋을 구하는 것은 비싸고 어렵다.
또한 품질 측면에서 사람이 데이터 라벨링을 해도 완벽하지 않다.
따라서 기존의 사전학습된 모델에 적은 데이터를 가지고 새로운 태스크를 수행하도록 Transfer Learning 을 하자.
정리하자면 하나의 거대한 데이터셋에서 배운 지식을 다른 데이터셋에 적용하는 방법이다!
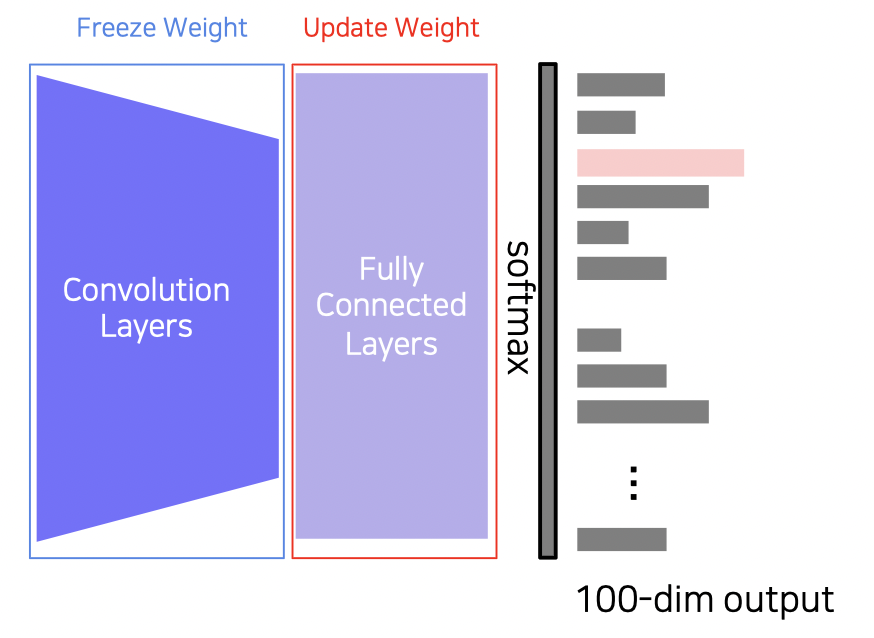
방법 1 : 사전학습된 웨이트 고정
기학습된 Convolution 레이어들은 그대로 두고 FC 레이어의 웨이트만 업데이트한다.
데이터가 정말 적을 때 사용하면 유용하다.
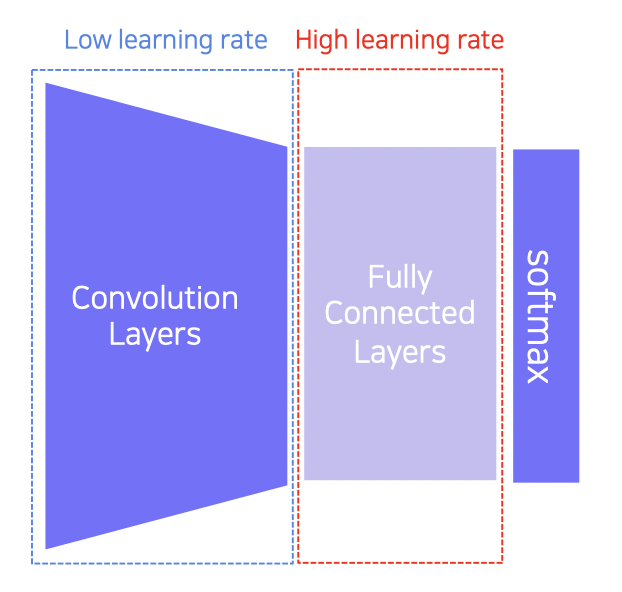
방법 2 : 전체 모델 학습
Convolution 레이어에는 적은 러닝 레이트를 주고 FC 레이어에는 높은 러닝 레이트를 줘서 학습시킨다.
데이터가 조금 더 있을 때 사용하면 유용하다.
Knowledge Distillation
모델이 학습한 것을 다른 작은 모델이 배우도록 하는 방법이다.
기학습된 모델을 직접 사용하지 않고 가벼운 모델을 만들고자 할 때 사용한다.
(Teacher-student learning)
모델 압축 (큰 모델이 아는 것을 따라하기) 과 수도 레이블링 (레이블이 없는 데이터의 레이블 만들기) 을 위해 사용한다.
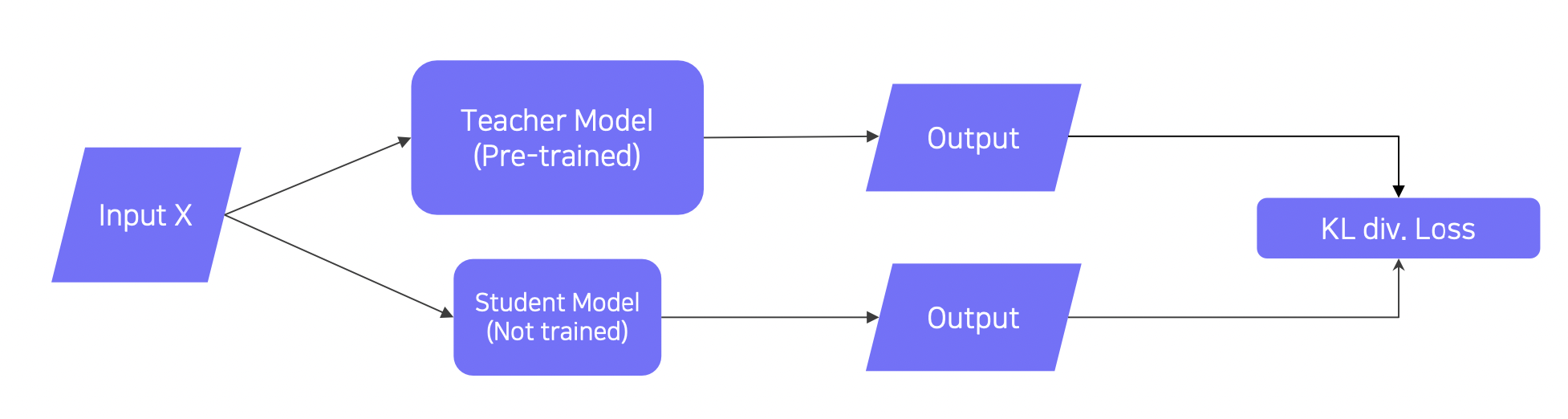
Teacher-student network structure
레이블이 없는 데이터의 경우
티쳐와 스튜던트의 아웃풋을 KL 발산 (divergence) 로스로 만들어 학습한다.
스튜던트는 티쳐의 결과를 따라하게 된다.
레이블이 있는 데이터의 경우
Distillation Loss (KL 발산) 는 레이블이 없을 때와 동일하게 스튜던트가 티쳐를 잘 따라하도록 만드는데 사용된다.
Student Loss (Cross-entropy) 는 Student 가 본연의 태스크를 잘 수행하도록 만드는데 사용된다.
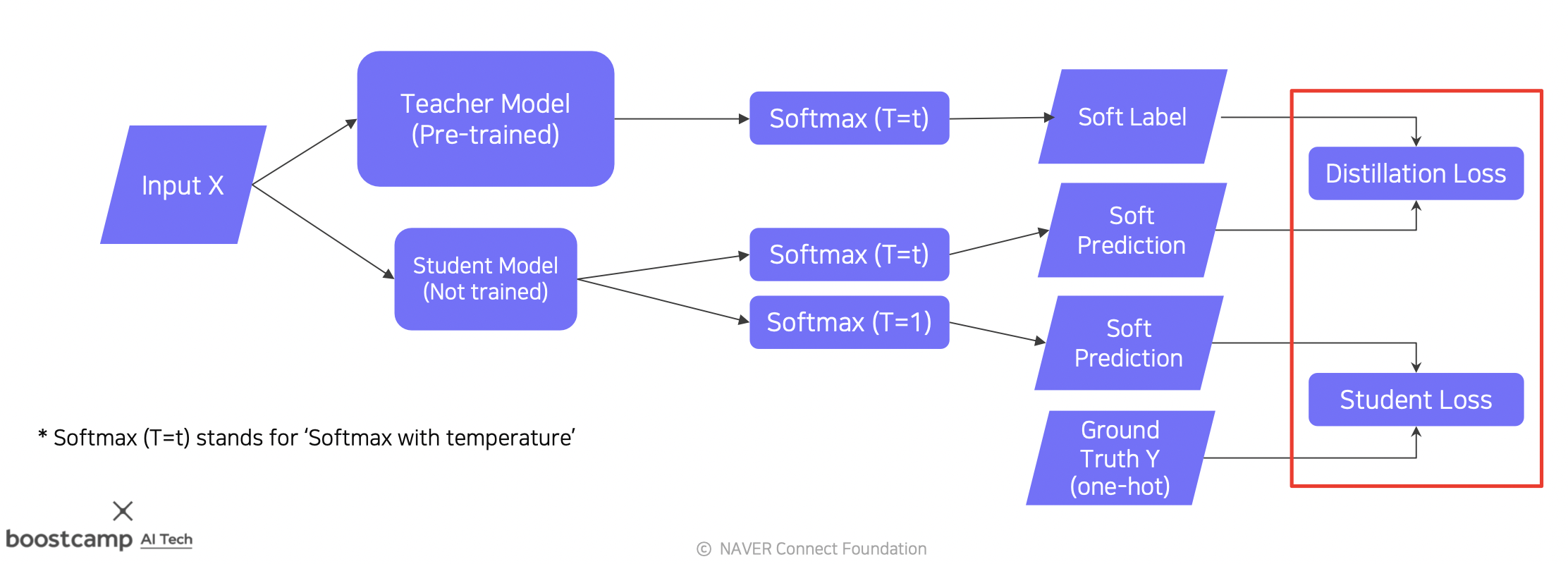
여기서 Soft 레이블은 softmax 처럼 전체가 1 을 이루는 벡터를 말한다.
반대로 Hard 레이블은 원-핫 벡터로 하나의 피쳐만 1 인 벡터를 말한다.
Distilation Loss 를 만들 때 Student 에서 Soft prediction 을 하는 이유는 티쳐의 분포를 그대로 따라가기 위해서다.
Student Loss 를 만들 때 Hard prediction (위 사진에서는 soft 이지만, 사실 저기에 t=1 로 주어 hard 라고 봐도 된다) 을 하는 이유는 분류 태스크를 수행하기 위해서다.
Softmax with temperature (T)
Softmax 의 Temperature 를 어떻게 주냐에 따라 Hard Prediction 과 Soft Prediction 이 구해진다.
T 가 작으면 softmax 가 더 극단적으로 되어 값들이 많이 벌려지고 (0 과 1 에 가까운 값들이 나옴), t 가 크면 값들의 차이가 적어진다 (중간에 가까운 값들이 나옴).
지식을 표현하는데 있어서는 분포가 몇몇 값만 극단적으로 크지 않고 골고루 크게 만드는 Soft prediction 이 적절하다.

의미 있는 정보가 아닌 모형을 따라하는 것
Distillation Loss 로 Student 가 Teacher 의 Soft label 에 대해 따라하고자 할 때, Soft label 의 의미를 알고자 하는게 아니라 단순히 모형을 따라하려는 것임을 기억하자.
최종 웨이트
최종적으로는 Distillation Loss 와 Student Loss 를 가중합하여 사용한다.
Leveraging Unlabeled Dataset for Training
Semi-supervised learning
위에서 말했듯 많은 데이터가 있다 하더라도 이들에게 레이블을 다는 일은 쉽지 않다. 따라서 레이블이 있는 데이터는 매우 드물다.
Semi-supervised learning 은 레이블이 없는 데이터 다수와 레이블이 있는 데이터 소량으로 좋은 성과를 내는 방법이다.
구체적인 방법은 아래의 Self-training 에서 설명하겠다.

Self-training (Google, 2020)
Self-training 은 Augmentation + Teacher-Student Networks + Semi-supervised learning 세 방법을 적용하여 매우 뛰어난 성능을 보여준 모델이다.
Teacher 모델 (Teacher-student) 은 데이터를 라벨링하는 법을 배워서 많은 언레이블 데이터를 분류 (Semi-supervised) 한다. 이 데이터와 기존 데이터를 합치고 RandAugment (Noizy) 하여 Student 모델이 학습한다.
그리고 다시 Student 모델이 Teacher 모델이 되어 언레이블 데이터에 대해 분류하고 새로운 Student 모델을 학습하는 과정을 반복 (Semi-supervised) 한다.
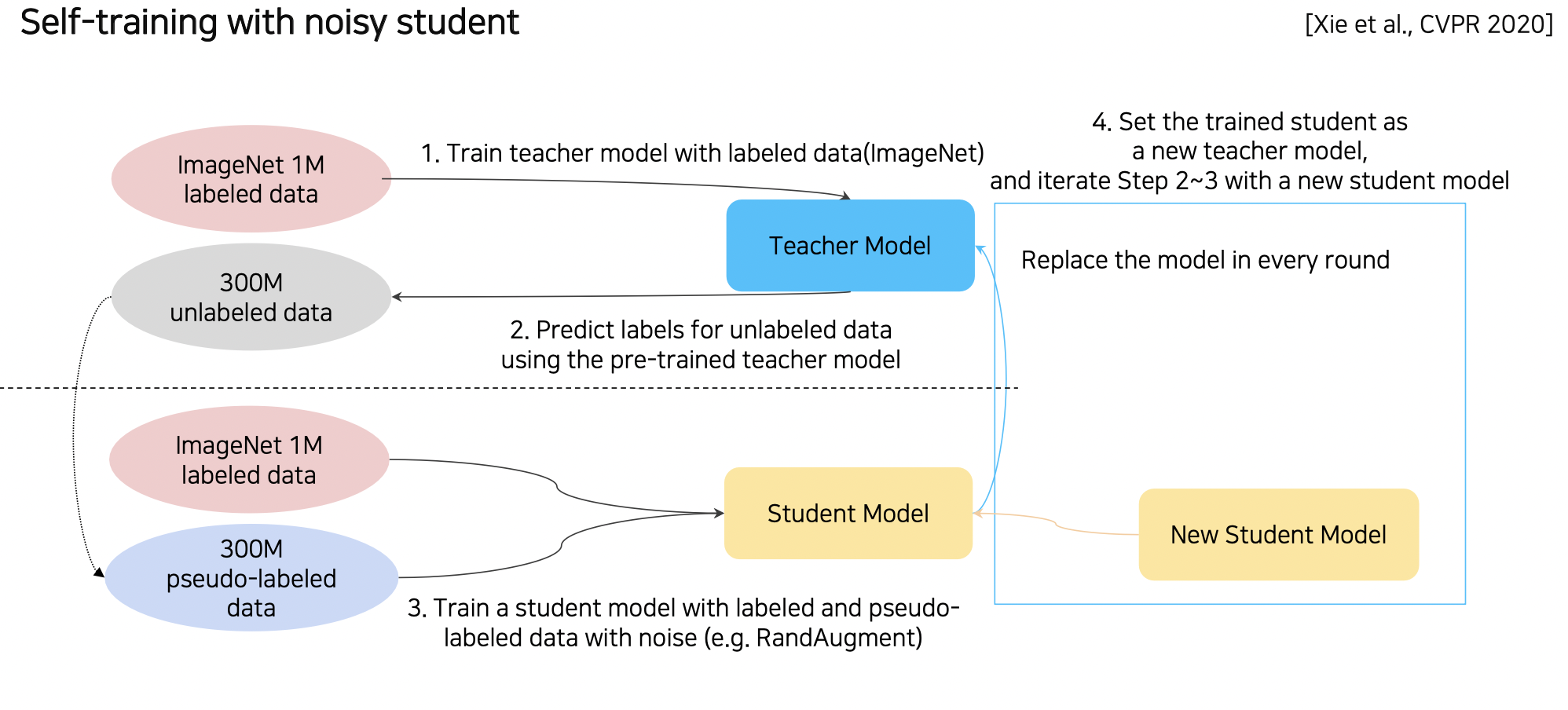
Knowledge Distillation 은 Student 모델을 작게 만들었다면, Self-training 은 Student 모델의 크기가 Teacher 모델보다 크게 만든다. (레이블이 없는 많은 데이터를 학습시키는 것이 목적이기 때문이다.)
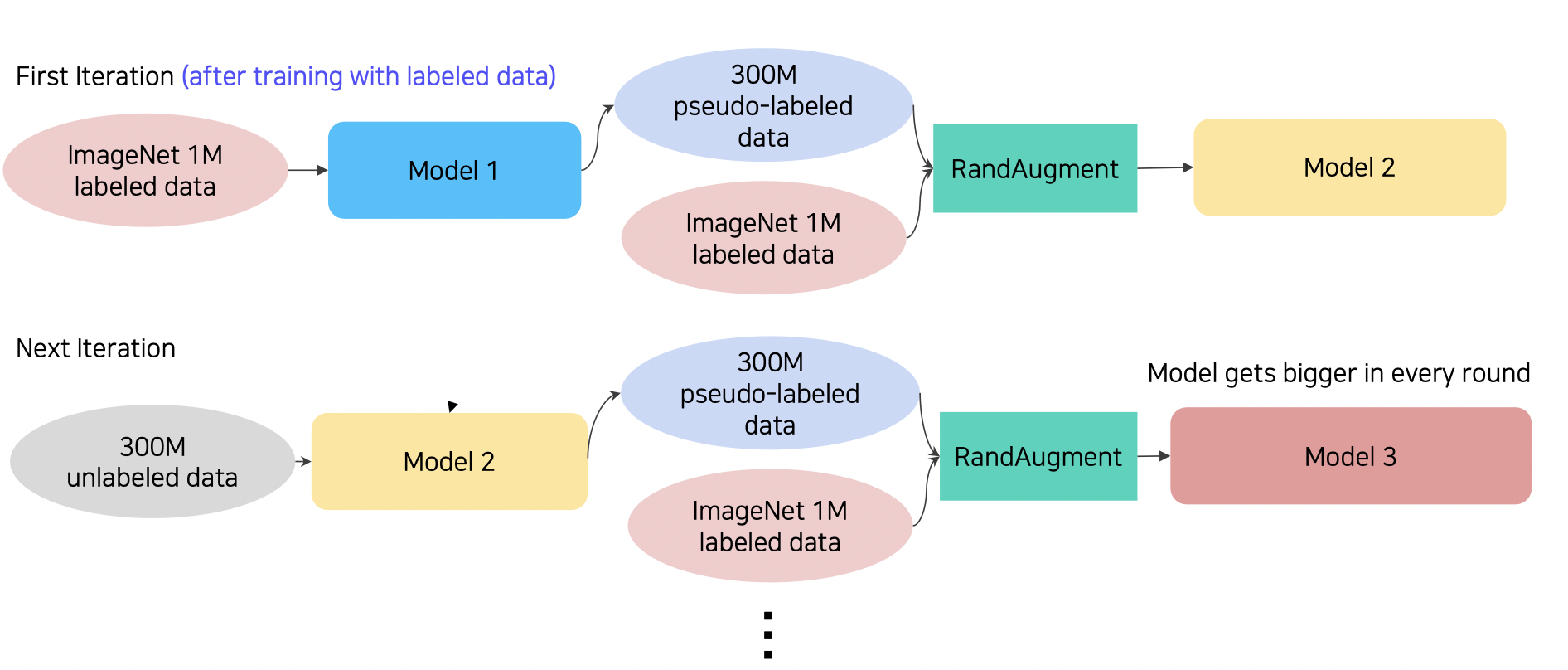
참조
BoostCamp AI Tech
